- 8 примеров использования value_counts из Pandas
- Что такое функция value_counts()?
- Загрузка данных для демонстрации
- Как получить уникальные значения из DataFrame в Python?
- Как получить уникальные значения из DataFrame в Python?
- Что такое Python DataFrame?
- Python Pandas.unique () Функция, чтобы получить уникальные значения из DataFrame
- Синтаксис Python Unique () Функция
- Python Unique () Функция с сериалом Pandas
- Python Unique () Функция с Pandas DataFrame
- Заключение
- 9 первоклассных функций Pandas Python для работы с данными
- 1. Сортировка данных по убыванию и возрастанию
- 2. shift() для смещения данных
- 3. Добавление нового столбца в заданном месте датафрейма
- 4. value_counts() для нахождения уникальных значений
- 5. Выбор столбца на основе типа данных
- 6. mask() для условия if-else
- 7. Фильтрация столбцов на основе частичного совпадения
- 8. nlargest() для определения наибольших значений
- 9. nsmallest()
- Заключение
8 примеров использования value_counts из Pandas
Прежде чем начинать работать над проектом, связанным с данными, нужно посмотреть на набор данных. Разведочный анализ данных (EDA) — очень важный этап, ведь данные могут быть запутанными, и очень многое может пойти не по плану в процессе работы.
В библиотеке Pandas есть несколько функций для решения этой проблемы, и value_counts — одна из них. Она возвращает объект, содержащий уникальные значения из dataframe Pandas в отсортированном порядке. Однако многие забывают об этой возможности и используют параметры по умолчанию. В этом материале посмотрим, как получить максимум пользы от value_counts , изменив параметры по умолчанию.
Что такое функция value_counts()?
Функция value_counts() используется для получения Series , содержащего уникальные значения. Она вернет результат, отсортированный в порядке убывания, так что первый элемент в коллекции будет самым встречаемым. NA-значения не включены в результат.
Синтаксис
df[‘your_column’].value_counts() — вернет количество уникальных совпадений в определенной колонке.
Важно заметить, что value_counts работает только с series, но не dataframe. Поэтому нужно указать одни квадратные скобки df[‘your_column’] , а не пару df[[‘your_column’]] .
Параметры:
- normalize (bool, по умолчанию False) — если True , то возвращаемый объект будет содержать значения относительно частоты встречаемых значений.
- sort (bool, по умолчанию True) — сортировка по частоте.
- ascending (bool, по умолчанию False) — сортировка по возрастанию.
- bins (int) — вместе подсчета значений группирует их по отрезкам, но это работает только с числовыми данными.
- dropna (bool, по умолчанию True) — не включать количество NaN.
Загрузка данных для демонстрации
Рассмотрим, как использовать этот метод на реальных данных. Возьмем в качестве примера датасет из курса Coursera на Kaggle.
Для начала импортируем нужные библиотеки и сами данные. Это нужно в любом проекте. После этого проанализируем данные в notebook Jupyter.
Источник
Как получить уникальные значения из DataFrame в Python?
Здравствуйте, читатели! В этой статье мы будем сосредоточиться на том, как получить уникальные значения из DataFrame в Python.
Автор: admin
Дата записи
Как получить уникальные значения из DataFrame в Python?
Здравствуйте, читатели! В этой статье мы будем сосредоточиться на Как получить уникальные значения из Dataframe в Python Отказ
Итак, давайте начнем!
Что такое Python DataFrame?
Модуль Python Pandas предлагает нам различные структуры данных и функции для хранения и манипулирования огромным объемом данных.
Dataframe Является ли структурированные данные PandaS модулем Pandas для решения больших наборов данных в более чем в одном измерении, таких как огромные файлы CSV или Excel и т. Д.
Как мы можем хранить большой объем данных в кадре данных, мы часто встречаемся в ситуации, чтобы найти уникальные значения данных из набора данных, который может содержать избыточные или повторные значения.
Это когда Pandas.dataframe.unique () Функция входит в картину.
Давайте теперь будем сосредоточиться на функционировании уникальной () функции в предстоящем разделе.
Python Pandas.unique () Функция, чтобы получить уникальные значения из DataFrame
Pandas.unique () Функция Возвращает уникальные значения, присутствующие в наборе данных.
Он в основном использует технику на основе хэш-таблиц для возврата неадрендальных значений из набора значений, присутствующих в структуре данных кадра/серии данных.
Давайте попробуем понять роль уникальной функции через пример
Рассмотрим набор данных, содержащий значения следующим образом: 1,2,3,2,4,3,2,3,2
Теперь, если мы применяем уникальную функцию, мы получим следующий результат: 1,2,3,4. При этом мы обнаружили уникальные значения набора данных.
Теперь давайте обсудим структуру функции PandaS.Unique () в следующем разделе.
Синтаксис Python Unique () Функция
Посмотрите на синтаксис ниже:
Вышеуказанный синтаксис полезен, когда данные имеют 1-мерную. Он представляет собой уникальное значение из 1-мерных значений данных (структура данных серии).
Но, что, если данные содержит более одного размера I.e. Строки и столбцы? Да, у нас есть решение для этого в синтаксисе ниже
Этот синтаксис позволяет нам найти уникальные значения из определенного столбца набора данных.
Хорошо, что данные имеют категориальный тип для уникальной функции, чтобы воспользоваться правильными результатами. Более того, данные отображаются в порядке его возникновения в наборе данных.
Python Unique () Функция с сериалом Pandas
В приведенном ниже примере мы создали список, который содержит избыточные значения.
Кроме того, мы преобразовали список в структуру данных серии, поскольку она имеет одно измерение. Наконец, мы применили уникальную функцию () функцию для получения уникальных значений от данных.
Python Unique () Функция с Pandas DataFrame
Давайте сначала загрузим набор данных в среду, как показано ниже
Вы можете найти набор данных здесь Отказ
Pandas.dataframe.nunique () Функция Представляет уникальные значения, присутствующие в каждом столбце DataFrame.
Кроме того, мы представляли уникальные значения, представляющие в столбце «сезон», используя ниже.
Заключение
По этому, мы подошли к концу этой темы. Не стесняйтесь комментировать ниже, если вы столкнетесь с любым вопросом.
Для большего количества таких постов, связанных с Python, оставаться настроенными, а до тех пор, как потом, счастливое обучение !! 🙂.
Источник
9 первоклассных функций Pandas Python для работы с данными

Pandas — одна из наиболее востребованных библиотек Python в повседневной работе с данными. Подобно Numpy она царствует в таких областях программирования, как наука о данных, МО, ИИ, опираясь на свои многочисленные искусно созданные методы, атрибуты и функции. Изо дня в день анализируя данные, мы сталкиваемся с разными незаурядными ситуациями, решения которых находятся сокровищнице встроенного API Pandas и реализуются посредством краткого и качественного кода.
В статье я поделюсь простыми, но очень эффективными приемами, которые превратят процесс программирования в удовольствие. Именно благодаря этим первоклассным функциям Pandas так полюбилась ученым по данным и инженерам МО.
Нижепредставленный датафрейм позволит прояснить ряд концепций, в других же примерах обойдемся без вспомогательных средств.
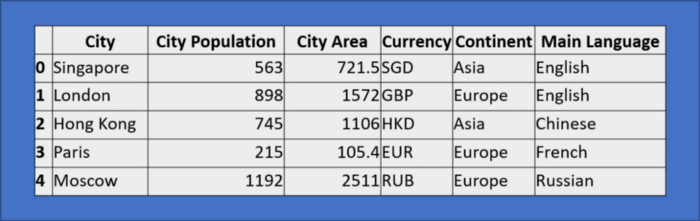 Изображение автора
Изображение автора 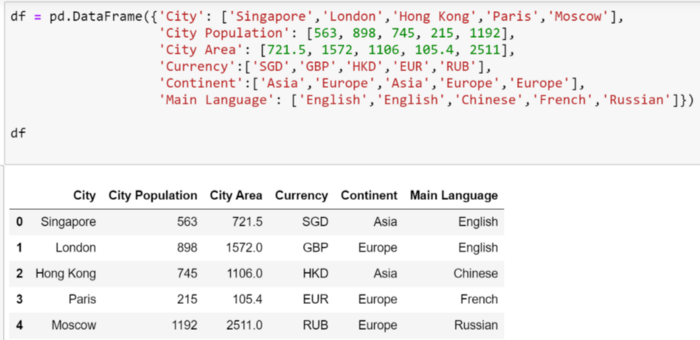 Изображение автора
Изображение автора
1. Сортировка данных по убыванию и возрастанию
В Pandas есть встроенная функция sort_values() для сортировки значений столбца или индекса в порядке возрастания или убывания. Отсортируем столбцы разными способами: один в порядке возрастания, а другой — убывания.
В следующем примере столбец “Continent” отсортирован по возрастанию, а “City Population” — по убыванию (второй уровень сортировки работает с соответствующими значениями первого уровня).
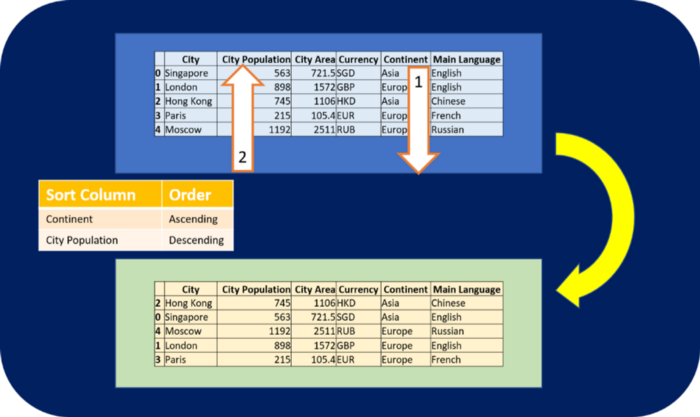 Изображение автора
Изображение автора 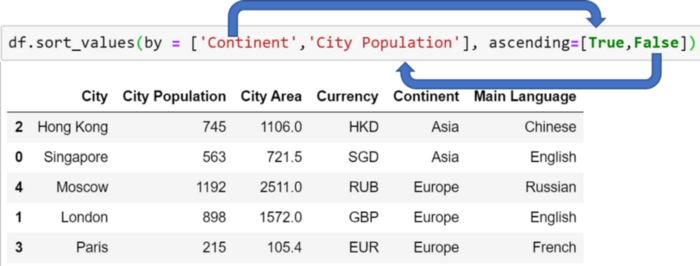 Изображение автора
Изображение автора
Аналогичным способом можно создать больше уровней сортировки, перечислив в одном списке имена столбцов, а в другом — соответствующий порядок. Используйте ключевые слова “ by ” и “ ascending ”, как показано ниже (имя каждого столбца в первом списке соотносится с порядком сортировки во втором).
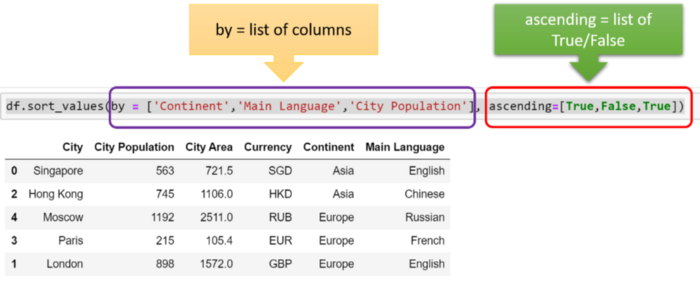 Изображение автора
Изображение автора
2. shift() для смещения данных
Допустим, ситуация требует сместить все строки в датафрейме или отобразить в нем цену акций предыдущего дня. Перед нами может стоять задача вывести среднюю температуру последних трех дней. Так вот shift() идеально подходит для всех этих целей.
Данная функция в Pandas сдвигает индекс на желаемое число периодов. Она принимает скалярный параметр под названием период, который представляет число сдвигов по требуемой оси. shift() пригодится для работы с данными временных рядов. Можно воспользоваться fill_value для заполнения за пределами граничных значений.
 Изображение автора
Изображение автора
При необходимости вывести цену акций предыдущего дня в новом столбце применяем shift() следующим образом:
Мы можем легко вычислить среднюю цену акций за три последних дня и создать новый столбец, как показано ниже:
Датафрейм приобретает такой вид:
Можно пойти дальше и получить значение из следующего временного интервала или ряда:
В этом случае датафрейм будет выглядеть так:
Более подробная информация о данной функции доступна в документации Pandas.
3. Добавление нового столбца в заданном месте датафрейма
С помощью Pandas мы довольно часто создаем новые столбцы для датафрейма. По умолчанию каждый такой столбец добавляется к нему с конца. Создадим новый столбец со значениями плотности населения для представленных в датафрейме городов (“City Population” / “City Area”). Новое поле по умолчанию будет выглядеть так:
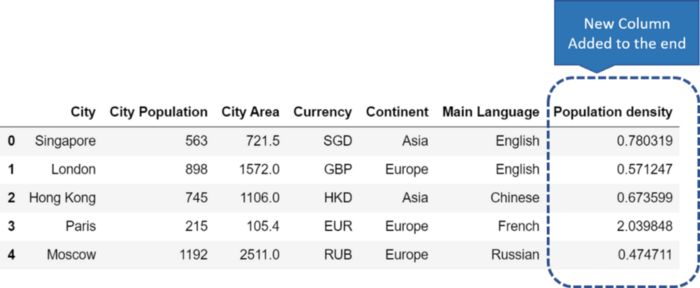 Изображение автора
Изображение автора
При необходимости создать столбец в определенном месте датафрейма, например между “City Area” и “Currency”, воспользуемся функцией insert .
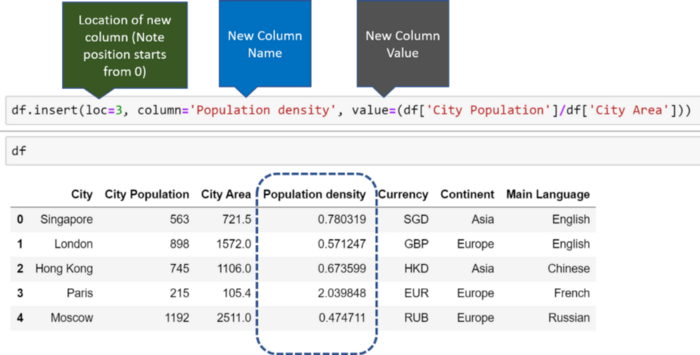 Изображение автора
Изображение автора
4. value_counts() для нахождения уникальных значений
Функция Pandas value_counts() возвращает объект, содержащий число уникальных значений. Полученный объект можно отсортировать по убыванию или возрастанию, включая или исключая NA посредством управления параметрами. Данная функция применяется с индексом или сериями Pandas.
 Изображение автора
Изображение автора
Ниже представлен пример серии:
Можно воспользоваться опцией bin вместо подсчета уникальных значений и разделить индекс в указанном количестве полуоткрытых интервалов.
Более подробная информация о данной функции представлена в документации Pandas.
5. Выбор столбца на основе типа данных
Во многих случаях требуется выбрать или выполнить определенные операции на основе типа данных столбцов. Допустим, наша задача — применить маску ко всем целым числам с плавающей точкой или преобразовать все столбцы с символьными данными в верхний регистр. В Pandas для этой цели существует один эффективный подход — встроенная функция select_dtypes . У нее есть опции include (включение)и exclude (исключение), и в форме списка мы можем задавать несколько их вариантов.
Сначала с помощью встроенного атрибута dtypes выясним, какие типы данных присутствуют в датафрейме.
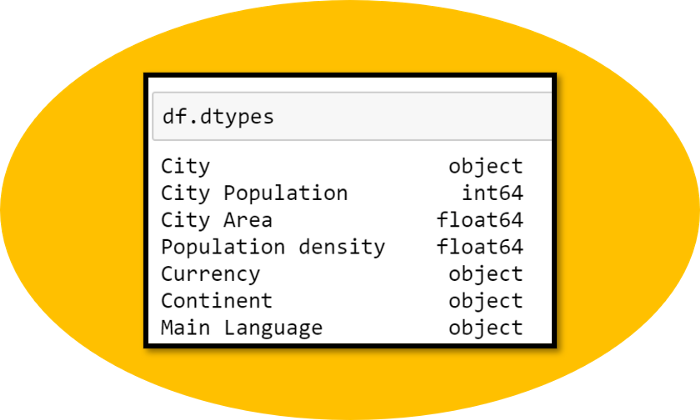 Изображние автора
Изображние автора
Теперь выберем только столбцы, содержащие значения float , воспользовавшись select_dtypes , как показано ниже:
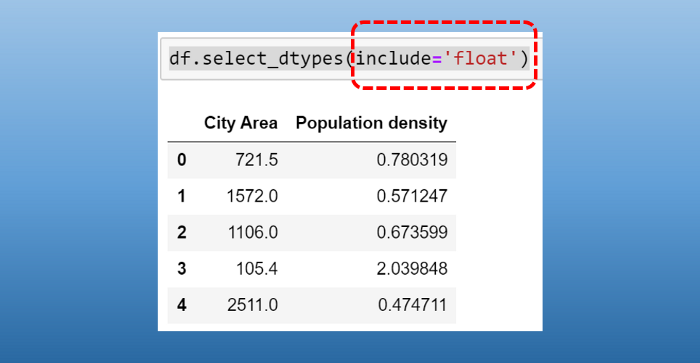 Изображение автора
Изображение автора
Также можно воспользоваться exclude для выбора всех типов данных, кроме исключенных. Например, в этом примере уберем все типы данных object :
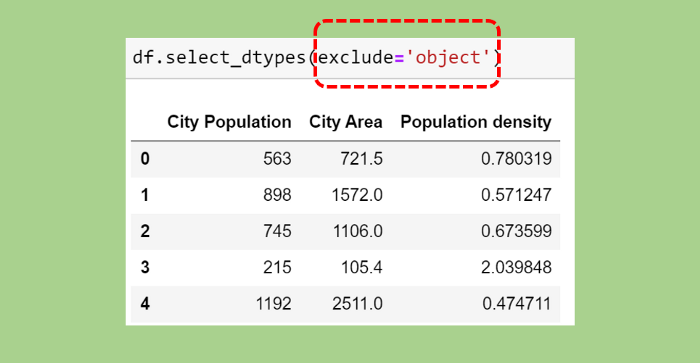 Изображение автора
Изображение автора
Исключение или включение нескольких типов данных происходит посредством списка. Помимо этого, допускаются комбинации этих операций.
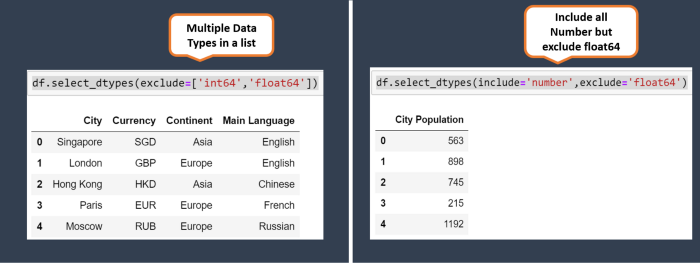
6. mask() для условия if-else
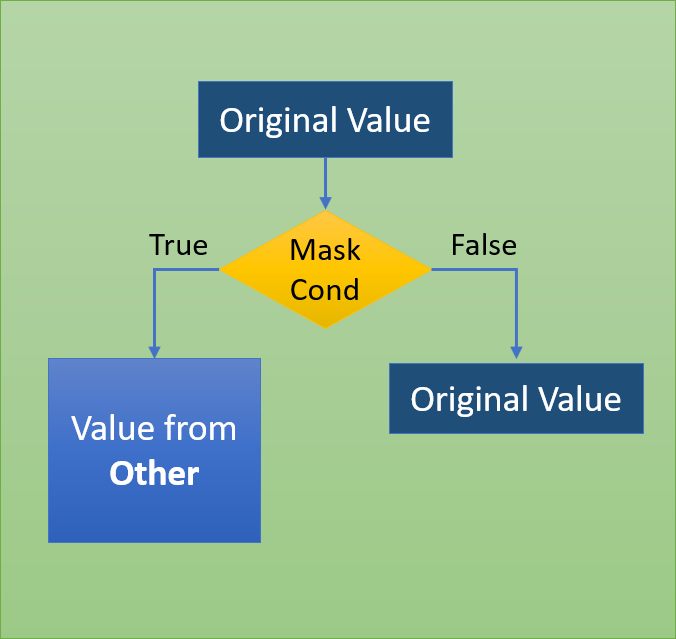
Метод mask() представляет собой применение условия if-then для каждого элемента серий или датафрейма. Если cond равно True , то используется значение из other (значение по умолчанию — NaN), в противном случае сохраняется исходное значение. Данный метод аналогичен where().
 Изображение автора
Изображение автора
Обратимся к датафрейму, в котором нужно изменить знак всех элементов, кратных двум без остатка.
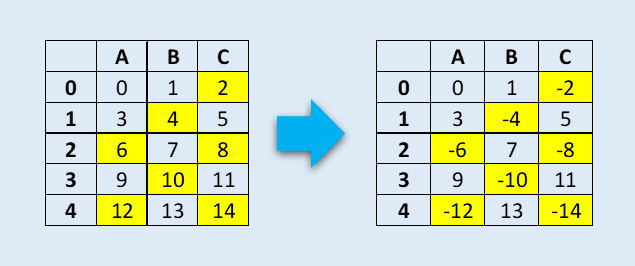 Изображение автора
Изображение автора
Эта задача легко решается с помощью функции mask() .
Более подробная информация о данном методе предоставлена в документации Pandas.
7. Фильтрация столбцов на основе частичного совпадения
Ежедневно обрабатывая данные, мы сталкиваемся с ситуациями, в которых нужно найти столбцы, связанные друг с другом совпадающими именами. При этом совпадение может быть не полным, а частичным. Допустим, необходимо вывести все столбцы, содержащие “date” или “amount”. В таких случаях не обойтись без функции filter . В рассматриваемом датафрейме найдем все столбцы, включающие “City”. При этом нужно обратить внимание на регистр сопоставляемых строк, так как он имеет значение.
 Изображение автора
Изображение автора
Далее рассмотрим примеры, в которых мы получаем требуемые результаты:
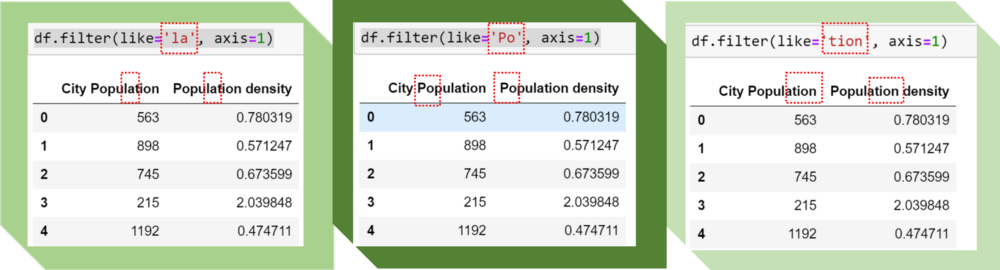 Изображение автора
Изображение автора
8. nlargest() для определения наибольших значений
Зачастую требуется найти три наибольших или пять наименьших значений в сериях или датафрейме (например, трех лучших студентов с их суммарным баллом или трех худших кандидатов с общим числом голосов, полученных на выборах).
Как раз для таких целей Pandas предоставляет nlargest() и nsmallest() .
Далее следует пример, отображающий 3 наибольших значения высоты в датафрейме из 10 имеющихся результатов измерения:
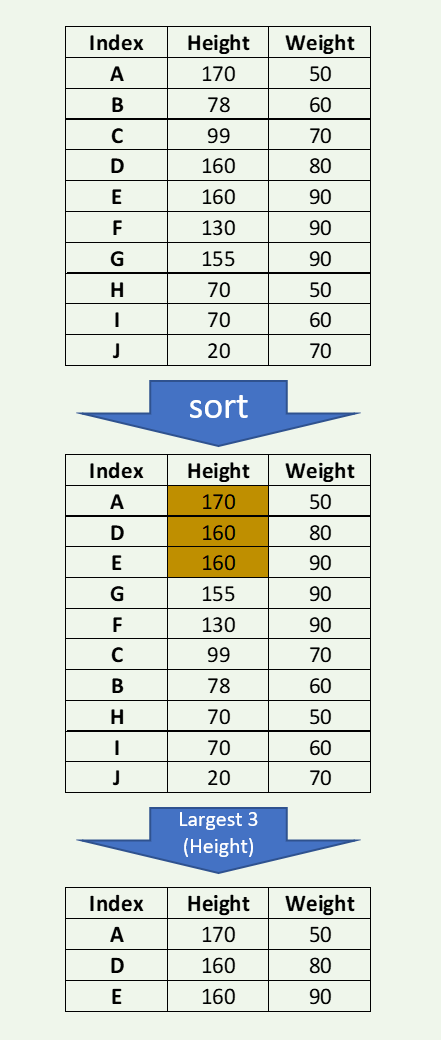 Изображение автора
Изображение автора
При наличии повторяющихся значений опции first , last , all помогают выбрать нужные (по умолчанию first ). Оставим все три полученных варианта и попробуем найти 2 наибольших значения высоты, как показано в примерах:
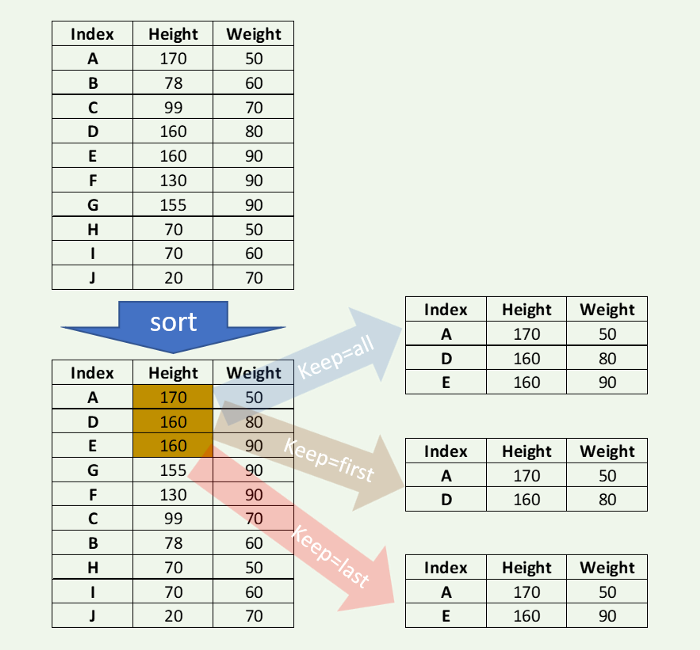 Изображения автора
Изображения автора
Оставляем последнее значение с конца:
Оставляем первое полученное значение:
С более подробной информацией о данной функции можно ознакомиться в документации Pandas.
9. nsmallest()
nsmallest() работает аналогичным образом, но только в отношении наименьших значений. В следующих примерах найдем 2 наименьших значения веса:
Документация Pandas содержит более подробную информацию о данной функции.
Заключение
Рассмотренные функции Pandas отличаются не только эффективностью, но также содержательностью, простой и краткостью. С течением лет API Pandas подвергся серьезной доработке и теперь предоставляет множество встроенных функций, требующих немало строк кода, или лямбда-функций для выполнения требуемых операций с данными. Надеюсь, материал был вам полезен.
Источник







