- MAX (Transact-SQL)
- Синтаксис
- Аргументы
- Типы возвращаемых данных
- Комментарии
- Примеры
- A. Простой пример
- Б. Использование предложения OVER
- В. Использование MAX с символьными данными
- SQL MAX () с HAVING
- MAX () функция с наличием
- SQL MAX () где
- SQL MAX () с оператором IN
- SQL MAX () с HAVING и IN
- SQL выбирает только строки с максимальным значением в столбце
- 29 ответов
- на первый взгляд.
- это никогда не бывает так просто, не так ли?
- Заметки Лёвика
- web программирование, администрирование и всякая всячина, которая может оказаться полезной
- Выборка записей с максимальным значением в MySQL
- Комментарии (2) к записи “Выборка записей с максимальным значением в MySQL”
MAX (Transact-SQL)
Применимо к: SQL Server (все поддерживаемые версии) База данных SQL Azure Управляемый экземпляр SQL Azure Azure Synapse Analytics Параллельное хранилище данных
Возвращает максимальное значение выражения.
 Синтаксические обозначения в Transact-SQL
Синтаксические обозначения в Transact-SQL
Синтаксис
Ссылки на описание синтаксиса Transact-SQL для SQL Server 2014 и более ранних версий, см. в статье Документация по предыдущим версиям.
Аргументы
ALL
Применяет агрегатную функцию ко всем значениям. ALL является параметром по умолчанию.
DISTINCT
Указывает, что учитывается каждое уникальное значение. Параметр DISTINCT не имеет смысла при использовании функцией MAX и доступен только для совместимости со стандартом ISO.
expression
Может быть константой, именем столбца или функцией, а также любым сочетанием арифметических, побитовых и строковых операторов. MAX можно использовать со столбцами numeric, character, uniqueidentifier и datetime, но не со столбцами bit. Агрегатные функции и вложенные запросы не допускаются.
Дополнительные сведения см. в разделе Выражения (Transact-SQL).
OVER ( partition_by_clause [ order_by_clause ] )
partition_by_clause делит результирующий набор, полученный с помощью предложения FROM, на секции, к которым применяется функция. Если этот параметр не указан, функция обрабатывает все строки результирующего набора запроса как отдельные группы. order_by_clause определяет логический порядок, в котором выполняется операция. partition_by_clause использовать обязательно. Дополнительные сведения см. в статье Предложение OVER (Transact-SQL).
Типы возвращаемых данных
Возвращает то же значение, что и expression.
Комментарии
При выполнении функции MAX все значения NULL пропускаются.
MAX возвращает NULL, если нет строк для выбора.
При использовании со столбцами, содержащими символьные значения, функция MAX находит наибольшее значение в упорядоченной последовательности.
MAX — это детерминированная функция, если она используется без предложений OVER и ORDER BY. Она не детерминирована при использовании с предложениями OVER и ORDER BY. Дополнительные сведения см. в разделе Deterministic and Nondeterministic Functions.
Примеры
A. Простой пример
В следующем примере возвращается наибольший (максимальный) размер налога в базе данных AdventureWorks2012.
Б. Использование предложения OVER
В приведенном ниже примере рассматривается применение функций MIN, MAX, AVG и COUNT с предложением OVER для получения статистических значений для каждого из отделов в таблице HumanResources.Department в базе данных AdventureWorks2012.
В. Использование MAX с символьными данными
В приведенном ниже примере возвращается имя базы данных, которое является последним при сортировке по алфавиту. В нем используется WHERE database_id для обработки только системных баз данных.
Источник
SQL MAX () с HAVING
MAX () функция с наличием
В этой статье мы обсудили, как SQL HAVING CLAUSE можно использовать вместе с SQL MAX (), чтобы найти максимальное значение столбца для каждой группы. SQL HAVING CLAUSE зарезервирован для статистической функции.
Использование предложения WHERE вместе с SQL MAX () также описано на этой странице.
SQL IN OPERATOR, который проверяет значение в наборе значений и извлекает строки из таблицы, также может использоваться с функцией MAX.
Пример :
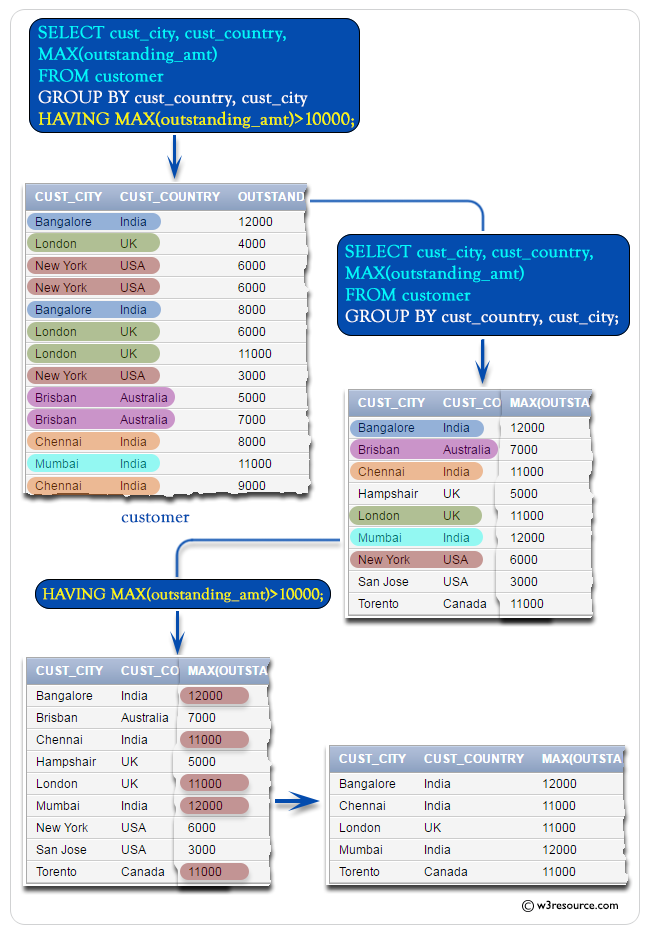
Образец таблицы: клиент
Чтобы получить данные ‘cust_city’, ‘cust_country’ и максимальный размер «привели_амт» из таблицы клиентов при следующих условиях —
1. комбинация cust_country и cust_city должна создать группу
можно использовать следующий оператор SQL:
Иллюстрированная презентация:
SQL MAX () где
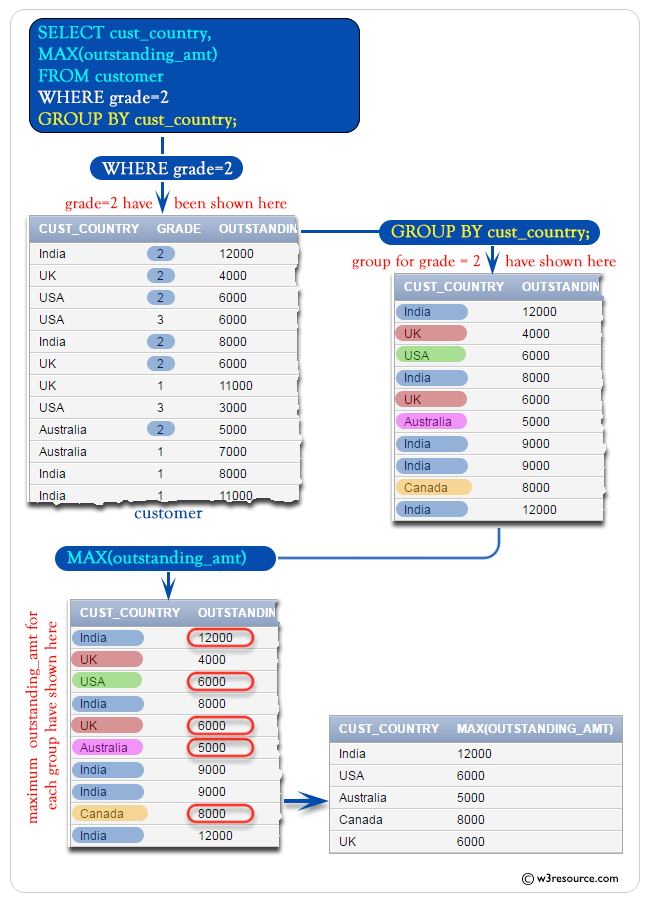
Образец таблицы: клиент
Чтобы получить данные «cust_country» и максимального значения «yal_amt »из таблицы« customer »с соблюдением следующих условий:
1. ‘cust_country’ должен быть отформатирован в группе,
2. оценка должна быть 2,
можно использовать следующий оператор SQL:
Иллюстрированная презентация:
SQL MAX () с оператором IN
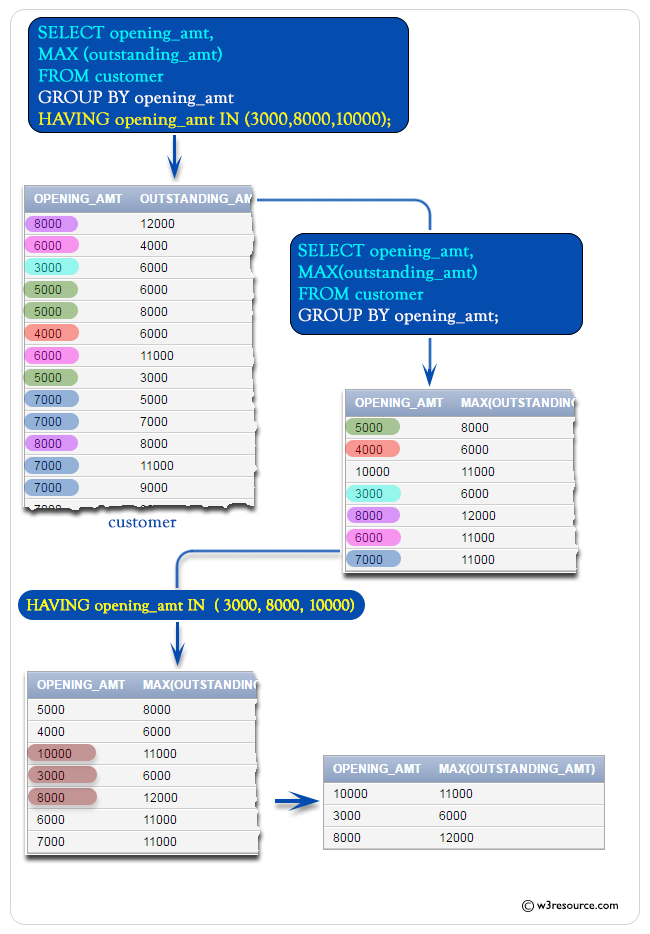
Образец таблицы: клиент
Чтобы получить данные для «открытие_amt» и максимум «выдающиеся_amt» из таблицы «клиент» при следующих условиях —
1. «Opening_amt» должен прийти в группу,
2. значение ‘creation_amt’ должно быть 3000, или 8000, или 10000,
можно использовать следующий оператор SQL:
Иллюстрированная презентация:
SQL MAX () с HAVING и IN
Пример таблицы: заказы
Чтобы получить данные «agent_code», количество агентов в виде «count (agent_code)» и максимальное значение ord_amount из таблицы «orders» при следующих условиях:
1. ‘agent_code’ должен быть отформатирован в группе,
2. максимальное значение ord_amount должно быть 500, 800 или 2000,
можно использовать следующий оператор SQL:
Примечание. Выводы указанного оператора SQL, показанного здесь, взяты с использованием Oracle Database 10g Express Edition.
Вот слайд-презентация всех агрегатных функций.
Источник
SQL выбирает только строки с максимальным значением в столбце
у меня есть эта таблица для документов (упрощенная версия здесь):
Как выбрать одну строку на id и только самый большой rev?
С приведенными выше данными результат должен содержать две строки: [1, 3, . ] и [2, 1, ..] . Я использую MySQL.
В настоящее время я использую проверки в while цикл для обнаружения и перезаписи старых оборотов из resultset. Но разве это единственный способ достичь результата? Нет среда SQL решение?
обновление
Как показывают ответы, там is решение SQL и вот демонстрация sqlfiddle.
обновление 2
Я заметил после добавления выше sqlfiddle, скорость, с которой вопрос upvoted превысил скорость upvote ответов. Это не было намерением! Скрипка основана на ответах, особенно на принятом ответе.
29 ответов
на первый взгляд.
все, что вам нужно-это GROUP BY п. с MAX агрегатная функция:
это никогда не бывает так просто, не так ли?
я только что заметил, что вам нужно
Я предпочитаю использовать как можно меньше кода.
Вы можете сделать это с помощью IN попробуйте это:
на мой взгляд, это менее сложно. легче читать и поддерживать.
еще одно решение-использовать коррелированный подзапрос:
наличие индекса на (id, rev)отображает подзапрос почти как простой поиск.
Ниже приведены сравнения с решениями в ответе @AdrianCarneiro (subquery, leftjoin), основанными на измерениях MySQL с таблицей InnoDB
1million записей, размер группы: 1-3.
в то время как для полного сканирования таблицы подзапрос/левое соединение/коррелированные тайминги относятся друг к другу как 6/8/9, когда дело доходит до прямой поиск или пакет ( id in (1,2,3) ), подзапрос намного медленнее остальных (из-за перезапуска подзапроса). Однако я не мог различать левое соединение и коррелированные решения в скорости.
одна заключительная нота, поскольку leftjoin создает N * (n+1)/2 присоединяется к группам, его производительность может сильно зависеть от размера групп.
Я не могу ручаться за производительность, но вот трюк, вдохновленный ограничениями Microsoft Excel. Он имеет некоторые хорошие особенности
ХОРОШЕЕ
- он должен принудительно вернуть только одну «максимальную запись», даже если есть галстук (иногда полезный)
- это не требует соединения
подход
это немного уродливо и требует, чтобы вы знали что-то о диапазоне допустимых значения rev
Я поражен тем, что ни один ответ не предложил решение функции окна SQL:
добавлено в SQL standard ANSI / ISO Standard SQL: 2003 и позже расширено с ANSI / ISO Standard SQL: 2008, оконные (или оконные) функции доступны со всеми основными поставщиками в настоящее время. Существует больше типов ранговых функций, доступных для решения проблемы галстука: RANK, DENSE_RANK, PERSENT_RANK .
Я думаю, что это самое простое решение :
- SELECT *: возврат всех полей.
- от сотрудника: таблица искала дальше.
- (выберите *. ) подзапрос: вернуть всех людей, отсортированных по зарплате.
- группа по employeesub.Зарплата:: заставьте строку зарплаты каждого сотрудника, отсортированную сверху, быть возвращенным результатом.
Если вам понадобится только одна строка, это еще проще:
Я также думаю, что это проще всего разбить, понять и модифицировать для других целей:
- заказ сотрудником.Зарплата DESC: заказать результаты по зарплате, с самой высокой заработной платой в первую очередь.
- LIMIT 1: верните только один результат.
понимая этот подход, решение любой из этих подобных проблем становится тривиальным: получить сотрудника с самой низкой зарплатой (изменить DESC на ASC), получить первую десятку зарабатывающих сотрудников (изменить предел 1 на предел 10), сортировать с помощью другого поля (порядок изменения по сотруднику.Зарплата на заказ по работнику.Комиссия) и др..
что-то вроде этого?
Так как это самый популярный вопрос в отношении этой проблемы, я повторно опубликую еще один ответ на него здесь:
похоже, что есть простой способ сделать это (но только в MySQL):
пожалуйста, кредитный ответ пользователя Bohemian на этот вопрос за предоставление такого краткого и элегантного ответа на эту проблему.
EDIT: хотя это решение работает для многих людей, оно может быть нестабильным в долгосрочной перспективе, поскольку MySQL не гарантирует, что оператор GROUP BY вернет значимые значения для столбцов не в списке GROUP BY. Поэтому используйте это решение на свой страх и риск
мне нравится использовать NOT EXIST — основанное решение для этой проблемы:
третье решение, которое я едва ли когда-либо видел, является специфичным для MySQL и выглядит так:
Да, это выглядит ужасно (преобразование в строку и обратно и т. д.) но по моему опыту это обычно быстрее, чем другие решения. Возможно, это только для моих случаев использования, но я использовал его на таблицах с миллионами записей и многими уникальными идентификаторами. Возможно, это потому, что MySQL довольно плохо оптимизирует другие решения (по крайней мере, в дни 5.0, когда я придумал это решение.)
важно то, что GROUP_CONCAT имеет максимальную длину для строки, которую он может создать. Вероятно, вы хотите поднять этот предел, установив group_concat_max_len переменной. И имейте в виду, что это будет ограничение на масштабирование, если у вас большое количество строк.
В любом случае, вышеизложенное не работает напрямую, если ваше поле содержимого уже является текстом. В этом случае вы, вероятно, захотите использовать другой разделитель, например \0. Вы также столкнетесь с group_concat_max_len ограничение быстрее.
Если у вас много полей в инструкции select и вы хотите получить последнее значение для всех этих полей с помощью оптимизированного кода:
Источник
Заметки Лёвика
web программирование, администрирование и всякая всячина, которая может оказаться полезной
Выборка записей с максимальным значением в MySQL
Выбираем записи с максимальным значением определенного поля.
На всякий случай — требуется получить не сами максимальные значения, а записи, в которых определенное поле равно максимальному.
Если поля всего два — сработает простой запрос:
id|date
select id, max(date) from table1;
При добавлении еще одного поля задача выбора записей с максимальным значением усложняется:
чтобы получить все записи с максимальной датой:
1) для MySQL версии 4.1 и выше можно сделать одним запросом:
select * from table1 where date in (select max(date) from table1)
2)Если версия ниже, то это надо делать в два запроса:
select @mxdate:=max(date) from table1;
select * from table1 where date=@mxdate;
id|date|count (id, date primary key) — next level
нужно вычислить count для каждого id с последней датой (с максимальным значением даты)
решение в один запрос рабочее, но нерациональное — на склейку и сравнение строк уходит неоправданно много времени
SELECT * FROM cms_catalog_goods_is_arc
WHERE CONCAT( date, id )
IN (SELECT concat( max( date ) , id ) FROM cms_catalog_goods_is_arc GROUP BY id )
Гораздо быстрей операция поиска строк с максимальным значением производится с использованием временных таблиц:
CREATE Temporary TABLE table2 (
`id` int(11) NOT NULL, `date` datetime NOT NULL, `cnt` int(11) NOT NULL,
PRIMARY KEY (`id`,`date`)
) ;
insert into table2 (id,date) select id, max(date) from table1 group by id;
update table2 t2, table1 t1 set t2.cnt=t1.cnt where t2.id=t1.id and t2.date=t1.date;
теперь в table2 все нужные нам записи.
ps. Довольно часто выполнить два простых запроса получается выгоднее, чем один сложный. http://www.samag.ru/art/07.2007/07.2007_02.html
pps В многих других СУБД (например, MS SQL, Oracle, PostgreSQL …) такого рода выборки решаются гораздо проще (с точки зрения пользователя БД) — достаточно одного незамудренного запроса. Что называется “в одну строчку” ..
В Oracle такого рода задача легко решается одним запросом. Причем, методов выбора строк с максимальным значением поля (даты в нашем случае) несколько. Часть из них приведена ниже (спасибо гостю SQL.ru с ником “Добрый Э — Эх” — http://sql.ru/forum/actualthread.aspx?tid=580229#5985168 )
1)
select *
from (
select t.*, row_number()
over(partition by num
order by dt desc) as rn
from
)
where rn = 1;
2)
select t1.*
from
left join
on t1.num = t2.num
and t1.dt
Метки: mysql
Опубликовано Суббота, Август 2, 2008 в 05:44 в следующих категориях: Без рубрики. Вы можете подписаться на комментарии к этому сообщению через RSS 2.0. Вы можете добавить комментарий, или trackback со своего сайта.
Автор будет признателен, если Вы поделитесь ссылкой на статью, которая Вам помогла:
BB-код (для вставки на форум)
html-код (для вставки в ЖЖ, WP, blogger и на страницы сайта)
ссылка (для отправки по почте)
Комментарии (2) к записи “Выборка записей с максимальным значением в MySQL”
Привет всем!
Вчера нашел через гугл по запросу “разработка электроники на заказ цены”
Рекомендую!
Пока!
Огромное спасибо, Вы мне очень помогли, я искал именно выборку по определенному полю…
Источник







