- SQL-Урок 8. Группировка данных (GROUP BY)
- 1. Создание групп (GROUP BY)
- 2. Фильтрующие группы (HAVING)
- 3. Группировка и сортировка
- Вывести список всех групп sql
- GROUP BY
- Фильтрация групп. HAVING
- SQL запросы быстро. Часть 1
- Введение
- Практика
- Структура sql-запросов
- SELECT, FROM
- WHERE
- GROUP BY
- HAVING
- ORDER BY
- Оператор SQL GROUP BY для группировки в запросах
- Группировка по одному столбцу без агрегатных функций
- Группировка по нескольким столбцам без агрегатных функций
- Группировка с агрегатными функциями
SQL-Урок 8. Группировка данных (GROUP BY)
Группировка данных позволяет разделить все данные на логические наборы, благодаря чему становится возможным выполнение статистических вычислений отдельно в каждой группе.
1. Создание групп (GROUP BY)
Группы создаются с помощью предложения GROUP BY оператора SELECT. Рассмотрим на примере.
SELECT Product, SUM(Quantity) AS Product_num FROM Sumproduct GROUP BY Product
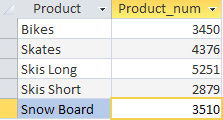
Данным запросом мы извлекли информацию о количестве реализованной продукции в каждом месяце. Оператор SELECT приказывает вывести два столбца Product — название продукта и Product_num — расчетное поле, которое мы создали для отображения количества реализованной продукции (формула поля SUM (Quantity)). Предложение GROUP BY указывает СУБД сгруппировать данные по столбцу Product. Стоит также отметить, что GROUP BY должен идти после предложения WHERE и перед ORDER BY.
2. Фильтрующие группы (HAVING)
Так же, как мы фильтровали строки в таблице, мы можем осуществлять фильтрацию по сгруппированным данным. Для этого в SQL существует оператор HAVING. Возьмем предыдущий пример и добавим фильтрацию по группам.
SELECT Product, SUM(Quantity) AS Product_num FROM Sumproduct GROUP BY Product HAVING SUM(Quantity)> 4000
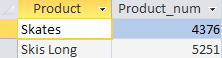
Видим, что после того, как была посчитана количество реализованного товара в разрезе каждого продукта, СУБД «отсекла» те продукты, которых было реализовано меньше 4000 шт.
Как видим, оператор HAVING очень похож на оператора WHERE , однако между собой они имеют существенное отличие: WHERE фильтрует данные до того, как они будут сгруппированы, а HAVING — осуществляет фильтрацию после группировки. Таким образом, строки, которые были изъяты предложением WHERE НЕ будут включены в группу. Итак, операторы WHERE и HAVING могут использоваться в одном предложении. Рассмотрим пример:
SELECT Product, SUM(Quantity) AS Product_num FROM Sumproduct WHERE Product<>‘Skis Long’ GROUP BY Product HAVING SUM(Quantity)> 4000

Мы к предыдущему примеру добавили оператор WHERE, где указали товар Skis Long, что в свою очередь повлияло на группирование оператором HAVING. Как результат видим, что товар Skis Long не попал в перечень групп с количеством реализованной продукции больше 4000 шт.
3. Группировка и сортировка
Как и при обычной выборке данных, мы можем сортировать группы после группировки оператором HAVING. Для этого мы можем использовать уже знакомый нам оператор ORDER BY. В данной ситуации его применения аналогичное предыдущим примерам. К примеру:
SELECT Product, SUM(Quantity) AS Product_num FROM Sumproduct GROUP BY Product HAVING SUM(Quantity)> 3000 ORDER BY SUM(Quantity)
или просто укажем номер поля по порядку, по которому хотим сортировать:
SELECT Product, SUM(Quantity) AS Product_num FROM Sumproduct GROUP BY Product HAVING SUM(Quantity)> 3000 ORDER BY 2
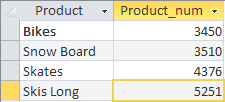
Видим, что для сортировки сводных результатов нам нужно просто прописать предложения с ORDER BY после оператора HAVING. Однако есть один нюанс. СУБД Access не поддерживает сортировку групп по псевдонимами колонок, то есть в нашем примере, чтобы сортировать значения, мы не сможем в конце запроса прописать ORDER BY Product_num .
Источник
Вывести список всех групп sql
Операторы GROUP BY и HAVING позволяют сгруппировать данные. Они употребляются в рамках команды SELECT:
GROUP BY
Оператор GROUP BY определяет, как строки будут группироваться.
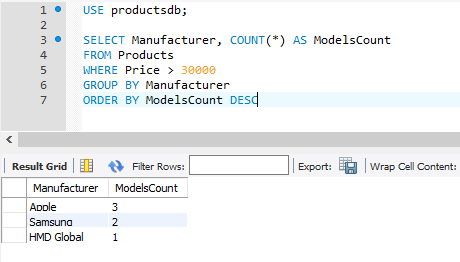
Например, сгруппируем товары по производителю
Первый столбец в выражении SELECT — Manufacturer представляет название группы, а второй столбец — ModelsCount представляет результат функции Count, которая вычисляет количество строк в группе.
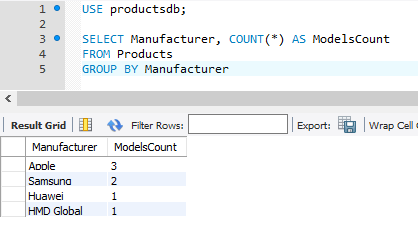
И если в выражении SELECT производится выборка по одному или нескольким столбцам и также используются агрегатные функции, то необходимо использовать выражение GROUP BY. Так, следующий пример работать не будет, так как он не содержит выражение группировки:
Оператор GROUP BY может выполнять группировку по множеству столбцов. Так, добавим группировку по количеству товаров:
Следует учитывать, что выражение GROUP BY должно идти после выражения WHERE , но до выражения ORDER BY :
Фильтрация групп. HAVING
Оператор HAVING позволяет выполнить фильтрацию групп, то есть определяет, какие группы будут включены в выходной результат.
Использование HAVING во многом аналогично применению WHERE. Только есть WHERE применяется для фильтрации строк, то HAVING — для фильтрации групп.
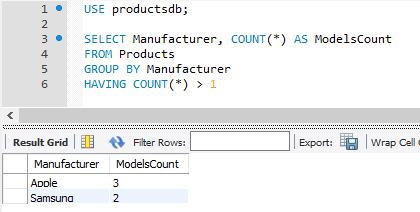
Например, найдем все группы товаров по производителям, для которых определено более 1 модели:
В одной команде также можно сочетать выражения WHERE и HAVING:
То есть в данном случае сначала фильтруются строки: выбираются те товары, общая стоимость которых больше 80000. Затем выбранные товары группируются по производителям. И далее фильтруются сами группы — выбираются те группы, которые содержат больше 1 модели.
Если при этом необходимо провести сортировку, то выражение ORDER BY идет после выражения HAVING:
Здесь группировка идет по производителям, и также выбирается количество моделей для каждого производителя (Models) и общее количество всех товаров по всем этим моделям (Units). В конце группы сортируются по количеству товаров по убыванию.
Источник
SQL запросы быстро. Часть 1
Введение
Язык SQL очень прочно влился в жизнь бизнес-аналитиков и требования к кандидатам благодаря простоте, удобству и распространенности. Из собственного опыта могу сказать, что наиболее часто SQL используется для формирования выгрузок, витрин (с последующим построением отчетов на основе этих витрин) и администрирования баз данных. И поскольку повседневная работа аналитика неизбежно связана с выгрузками данных и витринами, навык написания SQL запросов может стать фактором, из-за которого кандидат или получит преимущество, или будет отсеян. Печальная новость в том, что не каждый может рассчитывать получить его на студенческой скамье. Хорошая новость в том, что в изучении SQL нет ничего сложного, это быстро, а синтаксис запросов прост и понятен. Особенно это касается тех, кому уже доводилось сталкиваться с более сложными языками.
Обучение SQL запросам я разделил на три части. Эта часть посвящена базовому синтаксису, который используется в 80-90% случаев. Следующие две части будут посвящены подзапросам, Join’ам и специальным операторам. Цель гайдов: быстро и на практике отработать синтаксис SQL, чтобы добавить его к арсеналу навыков.
Практика
Введение в синтаксис будет рассмотрено на примере открытой базы данных, предназначенной специально для практики SQL. Чтобы твое обучение прошло максимально эффективно, открой ссылку ниже в новой вкладке и сразу запускай приведенные примеры, это позволит тебе лучше закрепить материал и самостоятельно поработать с синтаксисом.
Кликнуть здесь
После перехода по ссылке можно будет увидеть сам редактор запросов и вывод данных в центральной части экрана, список таблиц базы данных находится в правой части.
Структура sql-запросов
Общая структура запроса выглядит следующим образом:
Разберем структуру. Для удобства текущий изучаемый элемент в запроса выделяется CAPS’ом.
SELECT, FROM
SELECT, FROM — обязательные элементы запроса, которые определяют выбранные столбцы, их порядок и источник данных.
Выбрать все (обозначается как *) из таблицы Customers:
Выбрать столбцы CustomerID, CustomerName из таблицы Customers:
WHERE
WHERE — необязательный элемент запроса, который используется, когда нужно отфильтровать данные по нужному условию. Очень часто внутри элемента where используются IN / NOT IN для фильтрации столбца по нескольким значениям, AND / OR для фильтрации таблицы по нескольким столбцам.
Фильтрация по одному условию и одному значению:
Фильтрация по одному условию и нескольким значениям с применением IN (включение) или NOT IN (исключение):
Фильтрация по нескольким условиям с применением AND (выполняются все условия) или OR (выполняется хотя бы одно условие) и нескольким значениям:
GROUP BY
GROUP BY — необязательный элемент запроса, с помощью которого можно задать агрегацию по нужному столбцу (например, если нужно узнать какое количество клиентов живет в каждом из городов).
При использовании GROUP BY обязательно:
- перечень столбцов, по которым делается разрез, был одинаковым внутри SELECT и внутри GROUP BY,
- агрегатные функции (SUM, AVG, COUNT, MAX, MIN) должны быть также указаны внутри SELECT с указанием столбца, к которому такая функция применяется.
Группировка количества клиентов по городу:
Группировка количества клиентов по стране и городу:
Группировка продаж по ID товара с разными агрегатными функциями: количество заказов с данным товаром и количество проданных штук товара:
Группировка продаж с фильтрацией исходной таблицы. В данном случае на выходе будет таблица с количеством клиентов по городам Германии:
Переименование столбца с агрегацией с помощью оператора AS. По умолчанию название столбца с агрегацией равно примененной агрегатной функции, что далее может быть не очень удобно для восприятия.
HAVING
HAVING — необязательный элемент запроса, который отвечает за фильтрацию на уровне сгруппированных данных (по сути, WHERE, но только на уровень выше).
Фильтрация агрегированной таблицы с количеством клиентов по городам, в данном случае оставляем в выгрузке только те города, в которых не менее 5 клиентов:
В случае с переименованным столбцом внутри HAVING можно указать как и саму агрегирующую конструкцию count(CustomerID), так и новое название столбца number_of_clients:
Пример запроса, содержащего WHERE и HAVING. В данном запросе сначала фильтруется исходная таблица по пользователям, рассчитывается количество клиентов по городам и остаются только те города, где количество клиентов не менее 5:
ORDER BY
ORDER BY — необязательный элемент запроса, который отвечает за сортировку таблицы.
Простой пример сортировки по одному столбцу. В данном запросе осуществляется сортировка по городу, который указал клиент:
Осуществлять сортировку можно и по нескольким столбцам, в этом случае сортировка происходит по порядку указанных столбцов:
По умолчанию сортировка происходит по возрастанию для чисел и в алфавитном порядке для текстовых значений. Если нужна обратная сортировка, то в конструкции ORDER BY после названия столбца надо добавить DESC:
Обратная сортировка по одному столбцу и сортировка по умолчанию по второму:
JOIN — необязательный элемент, используется для объединения таблиц по ключу, который присутствует в обеих таблицах. Перед ключом ставится оператор ON.
Запрос, в котором соединяем таблицы Order и Customer по ключу CustomerID, при этом перед названиям столбца ключа добавляется название таблицы через точку:
Нередко может возникать ситуация, когда надо промэппить одну таблицу значениями из другой. В зависимости от задачи, могут использоваться разные типы присоединений. INNER JOIN — пересечение, RIGHT/LEFT JOIN для мэппинга одной таблицы знаениями из другой,
Внутри всего запроса JOIN встраивается после элемента from до элемента where, пример запроса:
Другие типы JOIN’ов можно увидеть на замечательной картинке ниже:

В следующей части подробнее поговорим о типах JOIN’ов и вложенных запросах.
При возникновении вопросов/пожеланий, всегда прошу обращаться!
Источник
Оператор SQL GROUP BY для группировки в запросах
Оглавление
- Группировка по одному столбцу без агрегатных функций
- Группировка по нескольким столбцам без агрегатных функций
- Группировка с агрегатными функциями
- Особенности применения группировки в MS SQL Server
Связанные темы
- Оператор SELECT
- Агрегатные функции
| Назад >> |
Оператор SQL GROUP BY служит для распределения строк — результата запроса — по группам, в которых значения некоторого столбца, по которому происходит группировка, являются одинаковыми. Группировку можно производить как по одному столбцу, так и по нескольким.
Часто оператор SQL GROUP BY применяется вместе с агрегатными функциями (COUNT, SUM, AVG, MAX, MIN). В этих случаях агрегатные функции служат для вычисления соответствующего агрегатного значения ко всему набору строк, для которых некоторый столбец — общий.
Оператор GROUP BY имеет следующий синтаксис:
Группировка по одному столбцу без агрегатных функций
Если в результате запроса требуется вывести один столбец и по этому же столбцу производится группировка, то оператор GROUP BY просто выбирает уникальные значения и убирает дубликаты, то есть выполняет те же задачи, что и ключевое слово DISTINCT.
Если вы хотите выполнить запросы к базе данных из этого урока на MS SQL Server, но эта СУБД не установлена на вашем компьютере, то ее можно установить, пользуясь инструкцией по этой ссылке .
Скрипт для создания базы данных библиотеки, её таблиц и заполения таблиц данными — в файле по этой ссылке .
В примерах работаем с базой данных библиотеки и ее таблицей «Книга в пользовании» (Bookinuse). Отметим, что оператор GROUP BY ведёт себя несколько по-разному в MySQL и в MS SQL Server. Эти различия будут показаны на примерах.
| Author | Title | Pubyear | Inv_No | Customer_ID |
| Толстой | Война и мир | 2005 | 28 | 65 |
| Чехов | Вишневый сад | 2000 | 17 | 31 |
| Чехов | Избранные рассказы | 2011 | 19 | 120 |
| Чехов | Вишневый сад | 1991 | 5 | 65 |
| Ильф и Петров | Двенадцать стульев | 1985 | 3 | 31 |
| Маяковский | Поэмы | 1983 | 2 | 120 |
| Пастернак | Доктор Живаго | 2006 | 69 | 120 |
| Толстой | Воскресенье | 2006 | 77 | 47 |
| Толстой | Анна Каренина | 1989 | 7 | 205 |
| Пушкин | Капитанская дочка | 2004 | 25 | 47 |
| Гоголь | Пьесы | 2007 | 81 | 47 |
| Чехов | Избранные рассказы | 1987 | 4 | 205 |
| Пушкин | Сочинения, т.1 | 1984 | 6 | 47 |
| Пастернак | Избранное | 2000 | 137 | 18 |
| Пушкин | Сочинения, т.2 | 1984 | 8 | 205 |
| NULL | Наука и жизнь 9 2018 | 2019 | 127 | 18 |
| Чехов | Ранние рассказы | 2001 | 171 | 31 |
Пример 1. Вывести авторов выданных книг, сгруппировав их. Пишем следующий запрос:
Этот запрос вернёт следующий результат:
| Author |
| NULL |
| Гоголь |
| Ильф и Петров |
| Маяковский |
| Пастернак |
| Пушкин |
| Толстой |
| Чехов |
Как видим, в таблице стало меньше строк, так как фамилии авторов остались каждая по одной.
В следующем примере увидим, что оператор GROUP BY не следует путать с оператором ORDER BY и поймём, чем эти операторы отличаются друг от друга.
Пример 2. Вывести авторов и названия выданных книг, сгруппировав по авторам. Пишем следующий запрос, который допустим в MySQL:
Этот запрос вернёт следующий результат:
| Author | Title |
| NULL | Наука и жизнь 9 2018 |
| Гоголь | Пьесы |
| Ильф и Петров | Двенадцать стульев |
| Маяковский | Поэмы |
| Пастернак | Доктор Живаго |
| Пушкин | Капитанская дочка |
| Толстой | Война и мир |
| Чехов | Вишнёвый сад |
Как видим, в таблице каждому автору соответствует лишь одна книга, причём та, которая в таблице BOOKINUSE является первой по порядку записей.
Если бы нам требовалось вывести все книги, причём авторы должны были бы следовать не «вразброс», а по порядку: сначала Гоголь и все его книги, затем другие авторы и все их книги, то мы применили бы не оператор GROUP BY, а оператор ORDER BY.
Группировка по нескольким столбцам без агрегатных функций
И всё же вывести все записи, соответствующие значению столбца, по которому происходит группировка, можно. Но в этом случае в результирующей таблице должен появиться ещё один столбец. Такой случай проиллюстирован в следующем примере.
Пример 3. Вывести авторов, названия выданных книг, ID пользователя и инвентарный номер выданной книги. Сгруппировать по авторам, ID пользователя и инвентарному номеру. На MySQL запрос будет следующим:
Этот запрос вернёт следующий результат:
| Author | Title | Customer_ID | Inv_no |
| Гоголь | Пьесы | 47 | 81 |
| Ильф и Петров | Двенадцать стульев | 31 | 3 |
| Маяковский | Поэмы | 120 | 2 |
| Пастернак | Избранное | 18 | 137 |
| Пастернак | Доктор Живаго | 120 | 69 |
| Пушкин | Капитанская дочка | 47 | 25 |
| Пушкин | Сочинения, т.1 | 47 | 6 |
| Пушкин | Сочинения, т.2 | 205 | 8 |
| Толстой | Воскресенье | 47 | 77 |
| Толстой | Война и мир | 65 | 28 |
| Толстой | Анна Каренина | 205 | 7 |
| Чехов | Вишневый сад | 31 | 19 |
| Чехов | Ранние рассказы | 31 | 171 |
| Чехов | Вишневый сад | 65 | 5 |
| Чехов | Избранные рассказы | 120 | 19 |
| Чехов | Избранные рассказы | 205 | 4 |
Как видим, в результирующей таблице присутствуют все книги всех авторов, причём авторы следуют по порядку, как если бы мы применили оператор ORDER BY. Кроме того, видно, что записи сгруппированы и по второму указанному столбцу — Customer_ID. Так, у автора Пушкина сначала перечисляются книги, выданные пользователю с Customer_ID 47, а затем — 205. У автора Чехова сначала перечисляются книги, выданные пользователю с Customer_ID 31, а затем — с другими номерами. Третий столбец, по которому происходит группировка — Inv_no — добавлен только для того, чтобы в результирующей таблице выводились все строки, соответствующие значениям ранее перечисленных столбцов для группировки, а не только уникальные.
По-другому ведёт себя оператор GROUP BY в MS SQL Server и в случае этого запроса.
Группировка с агрегатными функциями
Агрегатные функции COUNT, SUM, AVG, MAX, MIN служат для вычисления соответствующего агрегатного значения ко всему набору строк, для которых некоторый столбец — общий.
Пример 4. Вывести количество выданных книг каждого автора. Запрос будет следующим:
Результатом выполнения запроса будет следующая таблица:
| Author | InUse |
| NULL | 1 |
| Гоголь | 1 |
| Ильф и Петров | 1 |
| Маяковский | 1 |
| Пастернак | 2 |
| Пушкин | 3 |
| Толстой | 3 |
| Чехов | 5 |
Пример 5. Вывести количество книг, выданных каждому пользователю. Запрос будет следующим:
Результатом выполнения запроса будет следующая таблица:
| User_ID | InUse |
| 18 | 1 |
| 31 | 3 |
| 47 | 4 |
| 65 | 2 |
| 120 | 3 |
| 205 | 3 |
Примеры запросов к базе данных «Библиотека» есть также в уроках по оператору IN, предикату EXISTS и функциям CONCAT, COALESCE.
Источник







