SQL. Занимательные задачки
Вот уже более 3-х лет я преподаю SQL в разных тренинг центрах, и одним из моих наблюдений является то, что студенты осваивают и понимают SQL лучше, если ставить перед ними задачу, а не просто рассказывать о возможностях и теоретических основах.
В этой статье я поделюсь с вами своим списком задач, которые я даю студентам в качестве домашнего задания и над которыми мы проводим разного рода брейнстормы, что приводит к глубокому и четкому пониманию SQL.
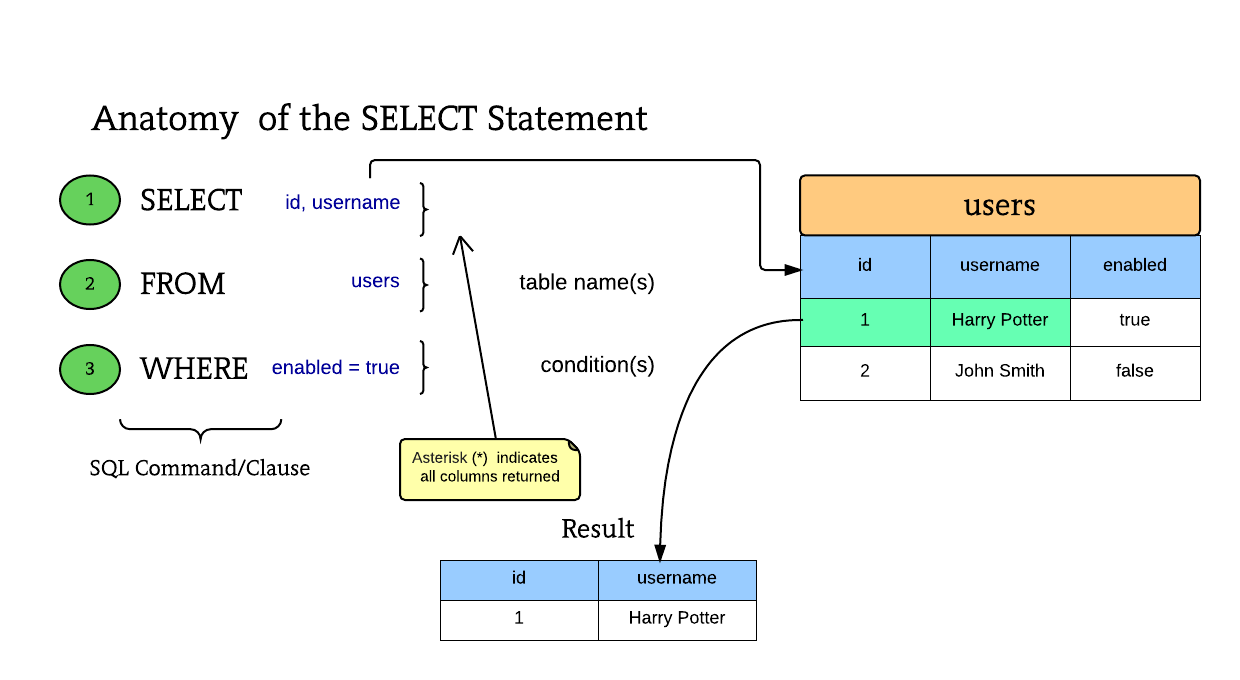
SQL (ˈɛsˈkjuˈɛl; англ. structured query language — «язык структурированных запросов») — декларативный язык программирования, применяемый для создания, модификации и управления данными в реляционной базе данных, управляемой соответствующей системой управления базами данных. Подробнее…
Почитать об SQL можно из разных источников.
Данная статья не преследует цели обучить вас SQL с нуля.
Будем использовть всем известную схему HR в Oracle с ее таблицами (Подробнее):
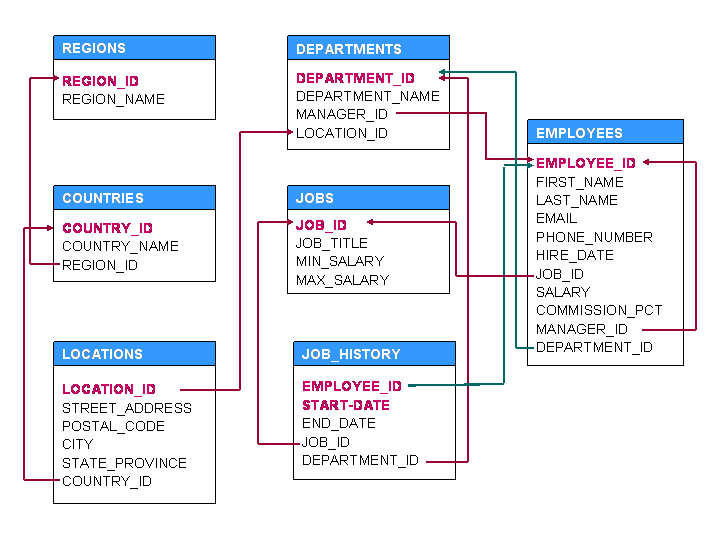
Отмечу что мы будем рассматривать только задачи на SELECT. Тут нет задач на DML и DDL.
Задачи
Restricting and Sorting Data
Таблица Employees. Получить список с информацией обо всех сотрудниках
Источник
Наш вариант теста на знание SQL
У нас, как и во многих других организациях, проводится тестирование соискателей при поступлении их на работу. Основу тестирования составляет устное собеседование, но в некоторых случаях, даются также практические задания. Несколько дней назад, Руководство попросило меня подготовить набор задач на знание SQL.
Разумеется, я постарался сделать задания не слишком сложными. Уровень соискателей различен и задачи, на мой взгляд, должны быть составлены таким образом, чтобы по результатам их решения можно было судить о том, насколько хорошо испытуемый знает предмет.
Также, не имело смысла давать задания на знание каких-либо особенностей тех или иных СУБД. Мы в работе используем Oracle, но это не должно создавать трудностей для соискателей знающих, например, только MS SQL или PostgreSQL. Таким-образом, использование платформо-зависимых решений не возбраняется, но и не является ожидаемым при решении задач.
Для проведения тестирования, в Oracle 11g была развернута схема, содержащая следующие таблицы:

Требовалось составить SQL-запросы, для решения следующих пяти заданий:
Вывести список сотрудников, получающих заработную плату большую чем у непосредственного руководителя
Вывести список сотрудников, получающих максимальную заработную плату в своем отделе
Вывести список ID отделов, количество сотрудников в которых не превышает 3 человек
Вывести список сотрудников, не имеющих назначенного руководителя, работающего в том-же отделе
Найти список ID отделов с максимальной суммарной зарплатой сотрудников
Не требовалось искать в каком-либо смысле оптимальное решение. Единственное требование: запрос должен возвращать правильный ответ на любых входных данных. Задания разрешалось решать в любом порядке, без ограничения времени. При правильном решении всех заданий, предлагалось следующее задание повышенной сложности:
Составить SQL-запрос, вычисляющий произведение вещественных значений, содержащихся в некотором столбце таблицы
Источник
OlegPetrenkoGit / Queries.sql
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
| — 1. Вывести список сотрудников, получающих заработную плату большую чем у непосредственного руководителя |
| SELECT * |
| FROM Employee AS employees, Employee AS chieves |
| WHERE chieves . id = employees . chief_id AND employees . salary > chieves . salary ; |
| — 2. Вывести список сотрудников, получающих максимальную заработную плату в своем отделе |
| SELECT * |
| FROM Employee AS employees |
| WHERE employees . salary = ( SELECT MAX (salary) FROM Employee AS max WHERE max . department_id = employees . department_id ); |
| — 3. Вывести список ID отделов, количество сотрудников в которых не превышает 3 человек |
| SELECT department_id |
| FROM Employee |
| GROUP BY department_id |
| HAVING COUNT ( * ) 3 ; |
| — 4. Вывести список сотрудников, не имеющих назначенного руководителя, работающего в том-же отделе |
| SELECT * |
| FROM Employee AS employees |
| LEFT JOIN Employee AS chieves ON ( employees . chief_id = chieves . Id AND employees . department_id = chieves . department_id ) |
| WHERE chieves . id IS NULL ; |
| — 5. Найти список ID отделов с максимальной суммарной зарплатой сотрудников |
| WITH dep_salary AS |
| ( SELECT department_id, sum (salary) AS salary |
| FROM employee |
| GROUP BY department_id) |
| SELECT department_id |
| FROM dep_salary |
| WHERE dep_salary . salary = ( SELECT max (salary) FROM dep_salary); |
You can’t perform that action at this time.
You signed in with another tab or window. Reload to refresh your session. You signed out in another tab or window. Reload to refresh your session.
Источник
OtherMedia
Информация должна принадлежать людям
Функциональная СУБД
В этой статье я хочу описать концепцию функциональной базы данных. Для лучшего понимания, я буду это делать путем сравнения с классической реляционной моделью. В качестве примеров будут использоваться задачи из различных тестов по SQL, найденные в интернете.
Введение
Реляционные базы данных оперируют таблицами и полями. В функциональной базе данных вместо них будут использоваться классы и функции соответственно. Поле в таблице с N ключами будет представлена как функция от N параметров. Вместо связей между таблицами будут использоваться функции, которые возвращают объекты класса, на который идет связь. Вместо JOIN будет использоваться композиция функций.
Прежде чем перейти непосредственно к задачам, опишу задание доменной логики. Для DDL я буду использовать синтаксис PostgreSQL. Для функциональной свой синтаксис.
Таблицы и поля
Простой объект Sku с полями наименование и цена:
| CLASS Sku; name = DATA STRING [ 100 ] (Sku); price = DATA NUMERIC [ 10 , 5 ] (Sku); |
Мы объявляем две функции, которые принимают на вход один параметр Sku, и возвращают примитивный тип.
Предполагается, что в функциональной СУБД у каждого объекта будет некий внутренний код, который автоматически генерируется, и к которому при необходимости можно обратиться.
Зададим цену для товара / магазина / поставщика. Она может изменяться со временем, поэтому добавим в таблицу поле время. Объявление таблиц для справочников в реляционной базе данных пропущу, чтобы сократить код:
| CLASS Sku; CLASS Store; CLASS Supplier; dateTime = DATA DATETIME (Sku, Store, Supplier); price = DATA NUMERIC [ 10 , 5 ] (Sku, Store, Supplier); |
Индексы
Для последнего примера построим индекс по всем ключам и дате, чтобы можно было быстро находить цену на определенное время.
| INDEX Sku sk, Store st, Supplier sp, dateTime(sk, st, sp); |
Задачи
Начнем с относительно простых задач, взятых из соответствующей статьи на Хабре.
Сначала объявим доменную логику (для реляционной базы это сделано непосредственно в приведенной статье).
| CLASS Department; name = DATA STRING [ 100 ] (Department); |
CLASS Employee;
department = DATA Department (Employee);
chief = DATA Employee (Employee);
name = DATA STRING [ 100 ] (Employee);
salary = DATA NUMERIC [ 14 , 2 ] (Employee);
Задача 1
Вывести список сотрудников, получающих заработную плату большую чем у непосредственного руководителя.
| SELECT name(Employee a) WHERE salary(a) > salary(chief(a)); |
Задача 2
Вывести список сотрудников, получающих максимальную заработную плату в своем отделе
| maxSalary ‘Максимальная зарплата’ (Department s) = GROUP MAX salary(Employee e) IF department(e) = s; SELECT name(Employee a) WHERE salary(a) = maxSalary(department(a)); |
// или если «заинлайнить»
SELECT name(Employee a) WHERE
salary(a) = maxSalary( GROUP MAX salary(Employee e) IF department(e) = department(a));
Обе реализации эквивалентны. Для первого случая в реляционной базе можно использовать CREATE VIEW, который таким же образом сначала посчитает для конкретного отдела максимальную зарплату в нем. В дальнейшем я для наглядности буду использовать первый случай, так как он лучше отражает решение.
Задача 3
Вывести список ID отделов, количество сотрудников в которых не превышает 3 человек.
| countEmployees ‘Количество сотрудников’ (Department d) = GROUP SUM 1 IF department(Employee e) = d; SELECT Department d WHERE countEmployees(d) 3 ; |
Задача 4
Вывести список сотрудников, не имеющих назначенного руководителя, работающего в том-же отделе.
| SELECT name(Employee a) WHERE NOT (department(chief(a)) = department(a)); |
Задача 5
Найти список ID отделов с максимальной суммарной зарплатой сотрудников.
| salarySum ‘Максимальная зарплата’ (Department d) = GROUP SUM salary(Employee e) IF department(e) = d; maxSalarySum ‘Максимальная зарплата отделов’ () = GROUP MAX salarySum(Department d); SELECT Department d WHERE salarySum(d) = maxSalarySum(); |
Перейдем к более сложным задачам из другой статьи. В ней есть подробный разбор того, как реализовывать эту задачу на MS SQL.
Задача 1
Какие продавцы продали в 1997 году более 30 штук товара №1?
Доменная логика (как и раньше на РСУБД пропускаем объявление):
| CLASS Employee ‘Продавец’ ; lastName ‘Фамилия’ = DATA STRING [ 100 ] (Employee); |
CLASS Product ‘Продукт’ ;
id = DATA INTEGER (Product);
name = DATA STRING [ 100 ] (Product);
CLASS Order ‘Заказ’ ;
date = DATA DATE (Order);
employee = DATA Employee (Order);
CLASS Detail ‘Строка заказа’ ;
order = DATA Order (Detail);
product = DATA Product (Detail);
quantity = DATA NUMERIC [ 10 , 5 ] (Detail);
| sold (Employee e, INTEGER productId, INTEGER year) = GROUP SUM quantity(OrderDetail d) IF employee(order(d)) = e AND id(product(d)) = productId AND extractYear(date(order(d))) = year; SELECT lastName(Employee e) WHERE sold(e, 1 , 1997 ) > 30 ; |
Задача 2
Для каждого покупателя (имя, фамилия) найти два товара (название), на которые покупатель потратил больше всего денег в 1997-м году.
Расширяем доменную логику из предыдущего примера:
| CLASS Customer ‘Клиент’ ; contactName ‘ФИО’ = DATA STRING [ 100 ] (Customer); |
customer = DATA Customer (Order);
unitPrice = DATA NUMERIC [ 14 , 2 ] (Detail);
discount = DATA NUMERIC [ 6 , 2 ] (Detail);
| sum (Detail d) = quantity(d) * unitPrice(d) * ( 1 — discount(d)); bought ‘Купил’ (Customer c, Product p, INTEGER y) = GROUP SUM sum(Detail d) IF customer(order(d)) = c AND product(d) = p AND extractYear(date(order(d))) = y; rating ‘Рейтинг’ (Customer c, Product p, INTEGER y) = PARTITION SUM 1 ORDER DESC bought(c, p, y), p BY c, y; SELECT contactName(Customer c), name(Product p) WHERE rating(c, p, 1997 ) 3 ; |
Оператор PARTITION работает по следующему принципу: он суммирует выражение, указанное после SUM (здесь 1), внутри указанных групп (здесь Customer и Year, но может быть любое выражение), сортируя внутри групп по выражениям, указанным в ORDER (здесь bought, а если равны, то по внутреннему коду продукта).
Задача 3
Сколько товаров нужно заказать у поставщиков для выполнения текущих заказов.
Опять расширяем доменную логику:
| CLASS Supplier ‘Поставщик’ ; companyName = DATA STRING [ 100 ] (Supplier); |
supplier = DATA Supplier (Product);
unitsInStock ‘Остаток на складе’ = DATA NUMERIC [ 10 , 3 ] (Product);
reorderLevel ‘Норма продажи’ = DATA NUMERIC [ 10 , 3 ] (Product);
| orderedNotShipped ‘Заказано, но не отгружено’ (Product p) = GROUP SUM quantity(OrderDetail d) IF product(d) = p; toOrder ‘К заказу’ (Product p) = orderedNotShipped(p) + reorderLevel(p) — unitsInStock(p); SELECT companyName(supplier(Product p)), name(p), toOrder(p) WHERE toOrder(p) > 0 ; |
Задача со звездочкой
И последней пример лично от меня. Есть логика социальной сети. Люди могут дружить друг с другом и нравится друг другу. С точки зрения функциональной базы данных это будет выглядеть следующим образом:
| CLASS Person; likes = DATA BOOLEAN (Person, Person); friends = DATA BOOLEAN (Person, Person); |
Необходимо найти возможных кандидатов на дружбу. Более формализовано нужно найти всех людей A, B, C таких, что A дружит с B, а B дружит с C, A нравится C, но A не дружит с C.
С точки зрения функциональной базы данных запрос будет выглядеть следующим образом:
| SELECT Person a, Person b, Person c WHERE likes(a, c) AND NOT friends(a, c) AND friends(a, b) AND friends(b, c); |
Читателю предлагается самостоятельно решить эту задачу на SQL. Предполагается, что друзей гораздо меньше чем тех, кто нравится. Поэтому они лежат в отдельных таблицах. В случае успешного решения есть также задача с двумя звездочками. В ней дружба не симметрична. На функциональной базе данных это будет выглядеть так:
| SELECT Person a, Person b, Person c WHERE likes(a, c) AND NOT friends(a, c) AND (friends(a, b) OR friends(b, a)) AND (friends(b, c) OR friends(c, b)); |
UPD: решение задачи с одной звездочкой от dss_kalika:
Заключение
Следует отметить, что приведенный синтаксис языка — это всего лишь один из вариантов реализации приведенной концепции. За основу был взят именно SQL, и целью было, чтобы он максимально был похож на него. Конечно, кому-то могут не понравится названия ключевых слов, регистры слов и прочее. Здесь главное — именно сама концепция. При желании можно сделать и C++, и Python подобный синтаксис.
Описанная концепция базы данных, на мой взгляд обладает следующими преимуществами:
- Простота. Это относительно субъективный показатель, который не очевиден на простых случаях. Но если посмотреть более сложные случаи (например, задачу со звездочкой), то, на мой взгляд, писать такие запросы значительно проще.
- Инкапсуляция. В некоторых примерах я объявлял промежуточные функции (например, sold, bought и т.д.), от которых строились последующие функции. Это позволяет при необходимости изменять логику определенных функций без изменения логики зависящих от них. Например, можно сделать, чтобы продажи sold считались от совершенно других объектов, при этом остальная логика не изменится. Да, в РСУБД это можно реализовать при помощи CREATE VIEW. Но если всю логику писать таким образом, то она будет выглядеть не очень читабельной.
- Отсутствие семантического разрыва. Такая база данных оперирует функциями и классами (вместо таблиц и полей). Точно также, как и в классическом программировании (если считать, что метод — это функция с первым параметром в виде класса, к которому он относится). Соответственно, «подружить» с универсальными языками программирования должно быть значительно проще. Кроме того, эта концепция позволяет реализовывать гораздо более сложные функции. Например, можно встраивать в базу данных операторы вида:
| CONSTRAINT sold(Employee e, 1 , 2019 ) > 100 IF name(e) = ‘Петя’ MESSAGE ‘Что-то Петя продает слишком много одного товара в 2019 году’ ; |
Несмотря на то, что это всего лишь концепция, у нас есть уже некоторая реализация на Java, которая транслирует всю функциональную логику в реляционную логику. Плюс к ней красиво прикручена логика представлений и много чего другого, благодаря чему получается целая платформа. По сути, мы используем РСУБД (пока только PostgreSQL) как «виртуальную машину». При такой трансляции иногда возникают проблемы, так как оптимизатор запросов РСУБД не знает определенной статистики, которую знает ФСУБД. В теории, можно реализовать систему управления базой данных, которая будет использовать в качестве хранилища некую структуру, адаптированную именно под функциональную логику.
Добавить комментарий Отменить ответ
Для отправки комментария вам необходимо авторизоваться.
Источник







