- Работа с XML из Python
- Введение
- Создание и сборка XML-документов
- Изменение файла XML
- Открытие и чтение больших файлов XML с помощью iterparse (инкрементальный анализ)
- Открытие и чтение с помощью ElementTree
- Поиск в XML с помощью XPath
- Индексы списков и срез в Python
- Работа с датой и временем в Python
- Модуль для работы с XML файлами
- Что будем делать
- Зачем
- Что нам понадобится
- Начнем
- Заключение
- Чтение и запись XML-файлов на Python с помощью Pandas
- Чтение и запись XML-файлов на Python с помощью Pandas
- Вступление
- Чтение XML с помощью панд
- Чтение с помощью xml.etree.ElementTree
- Чтение с помощью lxml
- Чтение с помощью xmltodict
- Написание XML с помощью панд
- Написание XML-файлов с помощью xml.etree.ElementTree
- Написание XML-файлов с помощью lxml
- Чтение и запись XML-файлов на Python
- Модули XML
- Пример XML-файла
- Чтение XML-документов
- Использование minidom
- Использование ElementTree
- Подсчет элементов XML-документа
- Использование minidom
- Использование ElementTree
- Написание XML-документов
- Использование ElementTree
- Поиск XML-элементов
- Использование ElementTree
- Изменение XML-элементов
- Использование ElementTree
- Создание XML-подэлементов
- Использование ElementTree
- Удаление XML-элементов
- Использование ElementTree
- Обертывание
Работа с XML из Python

Введение
Не все элементы входных данных XML будут в конечном итоге являться элементами анализируемого дерева. В настоящий момент этот модуль пропускает все комментарии XML, инструкции по обработке и объявления типа документа во входных данных. Тем не менее, деревья, построенные с использованием API этого модуля, а не синтаксического анализа из XML-текста, могут иметь комментарии и инструкции по обработке в них.
Создание и сборка XML-документов
Импорт модуля Элемента Дерева
Функция Element () используется для создания элементов XML
Функция SubElement (), используемая для создания вложенных элементов в элементе give
Функция dump() используется для вывода элементов xml .
Если вы хотите сохранить в файл, создайте дерево XML с функцией ElementTree() и сохраните в файл, используя метод write()
Функция Comment() используется для вставки комментариев в XML-файл.
Изменение файла XML
Импортируйте модуль ElementTree и откройте файл XML, получите элемент XML
Элементом объекта можно управлять, изменяя его поля, добавляя и изменяя атрибуты, добавляя и удаляя дочерние элементы
Если вы хотите удалить элемент, используйте метод Element.remove()
Метод ElementTree.write() , используемый для вывода объекта XML в файлы XML.
Открытие и чтение больших файлов XML с помощью iterparse (инкрементальный анализ)
Иногда мы не хотим загружать весь XML-файл, чтобы получить необходимую нам информацию. В этих случаях полезно постепенно загружать соответствующие разделы и затем удалять их, когда мы закончим. С помощью функции iterparse вы можете редактировать дерево элементов, которое хранится при разборе XML.
Импортируйте объект ElementTree:
Откройте файл .xml и переберите все элементы:
Кроме того, мы можем искать только определенные события, такие как начальный / конечный теги или пространства имен. Если эта опция не указана (как указано выше), возвращаются только события «end»:
Вот полный пример, показывающий, как очистить элементы из дерева в памяти, когда мы закончим с ними:
Открытие и чтение с помощью ElementTree
Импортируйте объект ElementTree, откройте соответствующий XML-файл и получите корневой тег:
Есть несколько способов поиска по дереву. Сначала по итерации:
В противном случае вы можете ссылаться на определенные места, такие как список:
Для поиска конкретных тегов по имени, используйте .find или .findall :
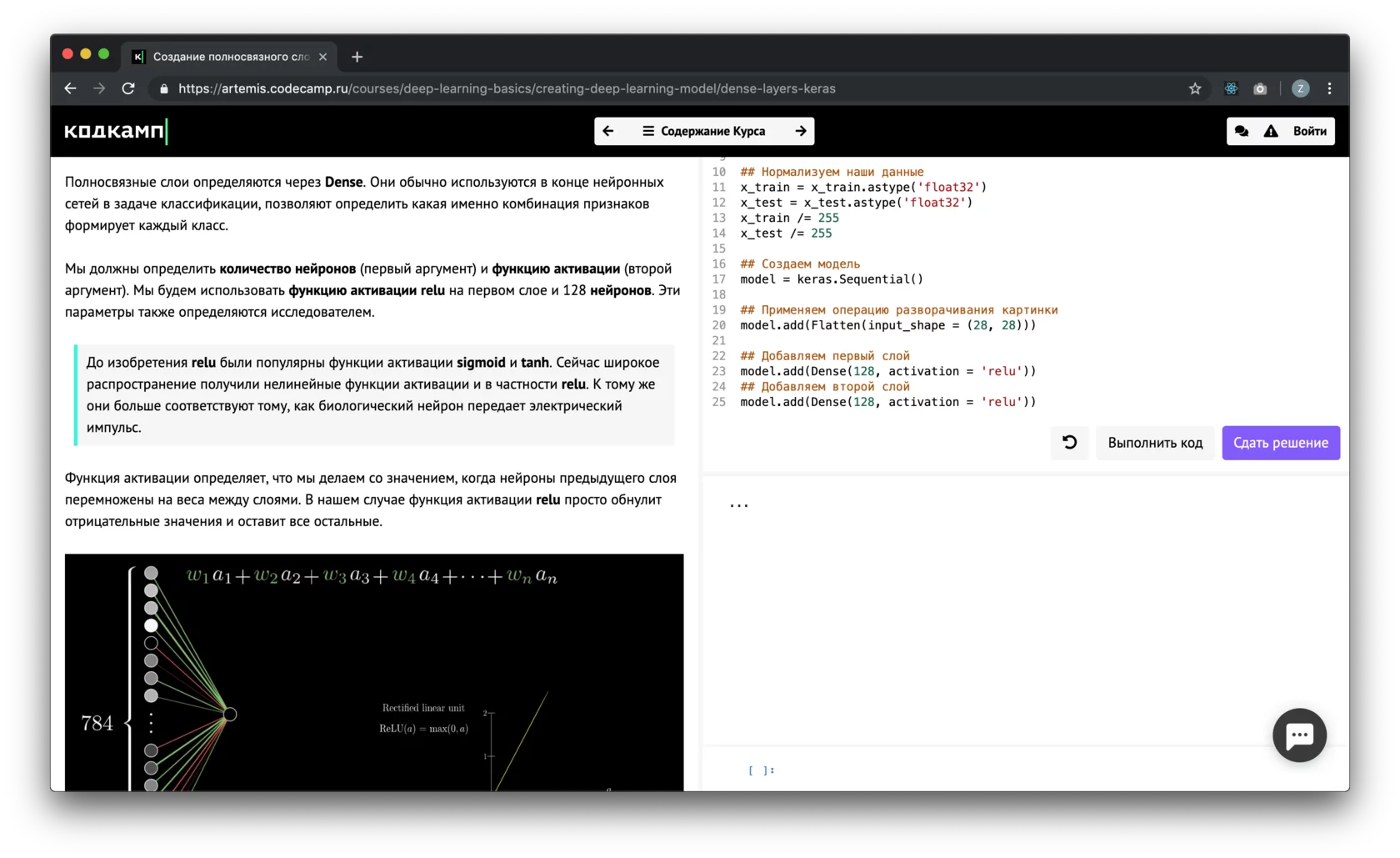
Поиск в XML с помощью XPath
Начиная с версии 2.7 ElementTree имеет лучшую поддержку XPath запросов. XPath — это синтаксис, позволяющий вам перемещаться по XML, как SQL используется для поиска в базе данных. Как find и findall функции поддержки XPath. Xml ниже будет использоваться для этого примера
Поиск всех книг:
Поиск книги с названием «Цвет магии»:
Поиск второй книги:
Поиск последней книги:
Поиск всех авторов:
Научим основам Python и Data Science на практике
Это не обычный теоритический курс, а онлайн-тренажер, с практикой на примерах рабочих задач, в котором вы можете учиться в любое удобное время 24/7. Вы получите реальный опыт, разрабатывая качественный код и анализируя реальные данные.
Индексы списков и срез в Python
Базовый срез Для любого итерируемого объекта (например, строки, списка и т. Д.) Python позволяет срезать и вернуть подстроку или подсписок своих данных. Формат для среза: iterable_name[start:stop:step] где, * start первый индекс среза. По
Работа с датой и временем в Python
Введение Примеры Как спарсить строку в datetime с часовым поясом Python 3.2+ поддерживает формат %z при разборе строки в объекте datetime. UTC в форме +HHMM или -HHMM (пустая строка, если объект не содержит информации
Источник
Модуль для работы с XML файлами
Что будем делать
Сегодня мы с Вами сделаем модуль для работы с XML файлами.
Зачем
Иногда при разработке программы на Python требуется сделать настройки, которые сможет поменять любой пользователь без изменения кода.
Что нам понадобится
Начнем
Для начала импортируем библиотеку и создадим основной класс.
Для работы с XML файлом нам понадобится сам XML файл, но на первом запуске программы у пользователя может не оказаться этого файла, по этому нам понадобится создать его.
При создание экземпляра класса передадим имя файла и сохраним его в параметр fileName.
Теперь напишем функцию, которая будет проверять существует ли наш файл и будем вызывать ее в момент создания экземпляра класса.
Далее напишем функцию, которая создаст наш файл если его нет, и будем вызывать его, если программа не нашла файла.
Теперь более подробно разберем функцию XML.createFile():
- rootXML — это основной элемент, который позволит записать все настройки в новый файл гораздо быстрее чем, если бы мы записывали все теги по отдельности
- text — тег, который будет отображаться внутри rootXML. В поле Element.text указываем, что должно быть внутри элемента
Для того, чтобы сделать список элементов, например:
Создайте главный элемент, в нашем случаи «list» и субэлементы «item».
Если наша программа — программа с интерфейсом, а файл настроек используется для сохранения каких-либо значений, которые может изменить пользователь, то нам понадобится функция, которая может изменить значение элемента. Давайте напишем ее.
В функцию editFile() мы передаем имя элемента(element), который хотим изменить и новое значение(value).
И последнее, что нужно для любой работы с XML файлами — это парсинг данных.
В метод parsingFile() мы передаем имя тега(element), который хотим получить и boolean значение какой тип данных нам вернуть. Если text = True то вернется значение элемента, иначе объект, который после можно будет перебрать. Например у нас есть XML файл:
И если мы хотим вывести в консоль все значения item, то мы парсим параметр «list» и в parsingFile() 2-м параметром передаем False. Начинаем перебирать полученный элемент и выводить element.text — имеющий значение выбранного элемента.
После выполнения данного кода в консоли мы увидим:
Заключение
В итоге у нас получился модуль, который можно использовать в своих проектах для работы с XML файлами.
Источник
Чтение и запись XML-файлов на Python с помощью Pandas
В этой статье вы узнаете, как считывать данные из XML-файла и загружать их в фрейм данных Pandas. Вы также экспортируете данные из фрейма данных Pandas в XML-файл.
Автор: Naazneen Jatu
Дата записи
Чтение и запись XML-файлов на Python с помощью Pandas
Вступление
XML (Extensible Markup Language) – это язык разметки, используемый для хранения структурированных данных. Библиотека анализа данных Pandas предоставляет функции для чтения/записи данных для большинства типов файлов.
Например, он включает в себя read_csv() и to_csv() для взаимодействия с CSV-файлами. Однако Pandas не включает в себя никаких методов чтения и записи XML-файлов.
В этой статье мы рассмотрим, как мы можем использовать другие модули для чтения данных из XML-файла и загрузки их в фрейм данных Pandas. Мы также возьмем данные из фрейма данных Pandas и запишем их в XML-файл.
Чтение XML с помощью панд
Давайте рассмотрим несколько способов чтения XML-данных и помещаем их в фрейм данных Pandas.
В этом разделе мы будем использовать один набор входных данных для каждого сценария. Сохраните следующий XML-файл в файле с именем properties.xml :
Чтение с помощью xml.etree.ElementTree
Файл xml.etree.Модуль ElementTree поставляется встроенным в Python. Он предоставляет функциональные возможности для синтаксического анализа и создания XML-документов. ElementTree представляет XML-документ в виде дерева. Мы можем перемещаться по документу, используя узлы, которые являются элементами и подэлементами XML-файла.
В этом подходе мы читаем содержимое файла в переменной и используем ET.XML() для синтаксического анализа XML-документа из строковой константы. Мы будем петлять по каждому дочернему и дочернему элементу, поддерживая список содержащихся в них данных. Тем временем, написание дочерних тегов для столбца фрейма данных. Затем мы записываем эти данные в фрейм данных.
Примечание: При чтении данных из XML мы должны транспонировать фрейм данных, так как подэлементы списков данных записываются в столбцы.
Давайте посмотрим на код, демонстрирующий использование xml.etree.ElementTree :
Приведенный выше код будет производить этот вывод (зависит от используемого входного файла):
Чтение с помощью lxml
Библиотека lxml является привязкой Python для библиотек C libxml2 и libxslt . Он также расширяет собственный модуль ElementTree . Поскольку это сторонний модуль, вам нужно будет установить его с помощью pip вот так:
В отличие от ElementTree , мы не читаем данные файла и не анализируем их. Мы можем напрямую использовать objectify.parse() и дать ему путь к XML-файлу. Чтобы получить корневой элемент, мы будем использовать getroot() для анализируемых XML-данных.
Теперь мы можем перебирать дочерние элементы корневого узла и записывать их в список Python. Как и раньше, мы создадим фрейм данных с помощью списка данных и транспонируем его.
Давайте посмотрим на код для создания фрейма данных Pandas с помощью lxml :
Если мы запустим это на интерпретаторе Python, то увидим следующий вывод:
Чтение с помощью xmltodict
Модуль xmltodict преобразует XML-данные в словарь Python, как следует из названия. Как и lxml , это сторонний модуль, который нам нужно установить с помощью pip :
Как и раньше, мы считываем содержимое XML в переменную. Мы приводим эти данные в методе parse() , который возвращает словарь XML – данных. Это будет вложенный словарь, содержащий элементы и подэлементы XML-файла. Мы можем перебирать элементы и записывать их в список данных, который мы используем для создания фрейма данных.
Давайте посмотрим на код для анализа XML-данных для создания фрейма данных с помощью xmltodict :
Если мы запустим приведенный выше код, то увидим результат следующим образом:
Примечание : Библиотека xmltodict не рекомендуется для больших XML-файлов, так как многие разработчики наблюдали снижение производительности. Библиотека lxml считается самой быстрой при работе с XML, даже быстрее, чем включенная xml.etree.ElementTree .
Используйте то, что лучше всего подходит для вашего проекта, и если производительность критична, вы должны запустить тесты с каждой библиотекой.
Написание XML с помощью панд
Давайте рассмотрим различные способы записи фрейма данных Pandas в XML-файл. Каждый сценарий, который мы используем ниже, создаст новый файл с именем coordinates.xml со следующим содержанием:
Мы можем использовать включенную функцию write() для файлов, чтобы записать фрейм данных в виде XML-файла. Для этого мы будем хранить список XML-данных таким образом, чтобы каждый элемент представлял собой строку в XML. Затем мы переберем фрейм данных и запишем данные с соответствующими открывающими и закрывающими тегами XML в список данных.
Как только это будет сделано, мы еще раз пройдемся по списку, чтобы записать данные в XML-файл. Вот код, который показывает использование write() :
Запуск этого кода приведет к созданию файла с именем coordinates.xml в текущем каталоге.
Написание XML-файлов с помощью xml.etree.ElementTree
Значение по умолчанию xml.etree.Модуль ElementTree может использоваться для хранения данных в формате XML и преобразования их в строку, чтобы их можно было записать в файл.
Наш первый шаг-это создание корневого элемента. Затем мы перебираем столбцы и строки фрейма данных, добавляя их как элементы и подэлементы в дерево элементов. Затем мы преобразуем данные объекта ElementTree в двоичную строку с помощью метода tostring () .
Поскольку XML-данные представляют собой двоичную строку, мы декодируем ее в UTF-8 перед записью в файл.
Следующий код использует xml.etree.ElementTree для записи фрейма данных в виде XML-файла:
Как и раньше, запуск этого скрипта создаст coordinates.xml файл с ожидаемым результатом.
Написание XML-файлов с помощью lxml
Использование lxml аналогично тому, как мы использовали xml.etree.ElementTree . Мы начинаем с создания объекта etree с корневым элементом создаваемого файла. Затем мы перебираем фрейм данных, добавляя столбцы и строки в качестве элементов и подэлементов дерева. Наконец, мы используем метод tostring() для получения etree в виде двоичной строки. Мы пишем файл после декодирования двоичной строки в UTF-8.
Вот код для записи DataFrame в виде XML с помощью lxml:
Источник
Чтение и запись XML-файлов на Python
Автор: Scott Robinson
Дата записи
XML, или расширяемый язык разметки,-это язык разметки, который обычно используется для структурирования, хранения и передачи данных между системами. Хотя он и не так распространен, как раньше, он все еще используется в таких сервисах, как RSS и SOAP, а также для структурирования файлов, таких как документы Microsoft Office.
Поскольку Python является популярным языком для Интернета и анализа данных, вполне вероятно, что в какой-то момент вам придется читать или записывать XML-данные, и в этом случае вам повезет.
В этой статье мы в первую очередь рассмотрим модуль ElementTree для чтения, записи и изменения XML-данных. Мы также сравним его со старым модулем minidom в первых нескольких разделах, чтобы вы могли получить хорошее сравнение этих двух модулей.
Модули XML
minidom , или Минимальная реализация DOM, представляет собой упрощенную реализацию объектной модели документа (DOM). DOM – это интерфейс прикладного программирования, который рассматривает XML как древовидную структуру, где каждый узел в дереве является объектом. Таким образом, использование этого модуля требует, чтобы мы были знакомы с его функциональными возможностями.
Модуль ElementTree предоставляет более “питонический” интерфейс для обработки XML и является хорошим вариантом для тех, кто не знаком с DOM. Это также, вероятно, лучший кандидат для использования более начинающими программистами из-за его простого интерфейса, который вы увидите на протяжении всей этой статьи.
В этой статье модуль ElementTree будет использоваться во всех примерах, тогда как minidom также будет продемонстрирован, но только для подсчета и чтения XML-документов.
Пример XML-файла
В приведенных ниже примерах мы будем использовать следующий XML-файл, который мы сохраним как “items.xml”:
Как вы можете видеть, это довольно простой пример XML, содержащий только несколько вложенных объектов и один атрибут. Однако этого должно быть достаточно, чтобы продемонстрировать все операции XML в этой статье.
Чтение XML-документов
Использование minidom
Чтобы разобрать XML-документ с помощью minidom , мы должны сначала импортировать его из модуля xml.dom . Этот модуль использует функцию parse для создания DOM-объекта из нашего XML-файла. Функция parse имеет следующий синтаксис:
Здесь имя файла может быть строкой, содержащей путь к файлу, или объектом типа файла. Функция возвращает документ, который может быть обработан как тип XML. Таким образом, мы можем использовать функцию getelementsbytagname() для поиска определенного тега.
Поскольку каждый узел можно рассматривать как объект, мы можем получить доступ к атрибутам и тексту элемента, используя свойства объекта. В приведенном ниже примере мы получили доступ к атрибутам и тексту конкретного узла и всех узлов вместе.
В результате получается следующее:
Если мы хотим использовать уже открытый файл, то можем просто передать наш файловый объект в parse вот так:
Кроме того, если XML-данные уже были загружены в виде строки, то вместо этого мы могли бы использовать функцию parseString () .
Использование ElementTree
ElementTree представляет нам очень простой способ обработки XML-файлов. Как всегда, чтобы использовать его, мы должны сначала импортировать модуль. В нашем коде мы используем команду import с ключевым словом as , что позволяет нам использовать упрощенное имя (в данном случае ET ) для модуля в коде.
После импорта мы создаем древовидную структуру с функцией parse и получаем ее корневой элемент. Как только у нас есть доступ к корневому узлу, мы можем легко обойти дерево, потому что дерево-это связный граф.
Используя ElementTree , как и в предыдущем примере кода, мы получаем атрибуты узла и текст, используя объекты, связанные с каждым узлом.
Код выглядит следующим образом:
Результат будет следующим:
Как видите, это очень похоже на пример minidom . Одно из главных отличий заключается в том, что объект attrib является просто объектом словаря, что делает его немного более совместимым с другим кодом Python. Нам также не нужно использовать value для доступа к значению атрибута элемента, как мы делали это раньше.
Возможно, вы заметили, что доступ к объектам и атрибутам с помощью ElementTree немного более питонен, как мы уже упоминали ранее. Это происходит потому, что XML-данные анализируются как простые списки и словари, в отличие от minidom , где элементы анализируются как пользовательские xml.dom.minidom.Attr и “Текстовые узлы DOM”.
Подсчет элементов XML-документа
Использование minidom
Как и в предыдущем случае, файл minidom должен быть импортирован из модуля dom . Этот модуль предоставляет функцию getElementsByTagName , которую мы будем использовать для поиска элемента тега. После получения мы используем встроенный метод len() для получения количества подэлементов, подключенных к узлу. Результат, полученный из приведенного ниже кода, показан на рисунке 3 .
Имейте в виду, что это будет только подсчитывать количество дочерних элементов под примечанием, которое вы выполняете land() on, которое в данном случае является корневым узлом. Если вы хотите найти все подэлементы в гораздо большем дереве, вам нужно будет пересечь все элементы и подсчитать каждый из их дочерних элементов.
Использование ElementTree
Аналогично, модуль ElementTree позволяет вычислить количество узлов, подключенных к узлу.
В результате получается следующее:
Написание XML-документов
Использование ElementTree
ElementTree также отлично подходит для записи данных в XML-файлы. В приведенном ниже коде показано, как создать XML-файл с той же структурой, что и файл, который мы использовали в предыдущих примерах.
- Создайте элемент, который будет действовать как наш корневой элемент. В нашем случае тег для этого элемента – “data”.
- Как только у нас есть корневой элемент, мы можем создавать подэлементы с помощью функции SubElement . Эта функция имеет следующий синтаксис:
ПодЭлемент(parent, tag, attrib=<>, **extra)
Здесь parent – это родительский узел для подключения, attrib – словарь, содержащий атрибуты элемента, а extra – дополнительные аргументы ключевого слова. Эта функция возвращает нам элемент, который можно использовать для присоединения других подэлементов, как мы делаем в следующих строках, передавая элементы в конструктор SubElement . 3. Хотя мы можем добавить ваши атрибуты с помощью функции SubElement , мы также можем использовать функцию set () , как мы это делаем в следующем коде. Текст элемента создается с помощью свойства text объекта Element . 4. В последних 3 строках приведенного ниже кода мы создаем строку из XML-дерева и записываем эти данные в открытый файл.
Выполнение этого кода приведет к созданию нового файла”. items2.xml”, который должен быть эквивалентен оригиналу “items.xml – файл, по крайней мере, с точки зрения структуры данных XML. Вы, вероятно, заметите, что результирующая строка представляет собой только одну строку и не содержит отступов.
Поиск XML-элементов
Использование ElementTree
Модуль ElementTree предлагает функцию findall () , которая помогает нам находить определенные элементы в дереве. Он возвращает все элементы с заданным условием. Кроме того, модуль имеет функцию find() , которая возвращает только первый подэлемент, соответствующий заданным критериям. Синтаксис для обеих этих функций выглядит следующим образом:
Для обеих этих функций параметр match может быть именем XML-тега или путем. Функция findall() возвращает список элементов, а find возвращает один объект типа Element .
Кроме того, существует еще одна вспомогательная функция, которая возвращает текст первого узла, соответствующего заданному критерию:
Вот несколько примеров кода, чтобы показать вам, как именно работают эти функции:
И вот результат выполнения этого кода:
Изменение XML-элементов
Использование ElementTree
Модуль ElementTree представляет несколько инструментов для изменения существующих XML-документов. В приведенном ниже примере показано, как изменить имя узла, изменить имя атрибута и изменить его значение, а также как добавить дополнительный атрибут к элементу.
Текст узла можно изменить, указав новое значение в текстовом поле объекта узла. Имя атрибута можно переопределить с помощью функции set(name, value) . Функция set не должна просто работать с существующим атрибутом, она также может быть использована для определения нового атрибута.
В приведенном ниже коде показано, как выполнять эти операции:
После запуска кода полученный XML-файл “newitems.xml” будет иметь XML-дерево со следующими данными:
Как мы видим при сравнении с исходным XML-файлом, имена элементов item изменились на “new item”, текст-на “new text”, а атрибут “name2” был добавлен в оба узла.
Вы также можете заметить, что запись XML-данных таким образом (вызов three.write с именем файла) добавляет еще некоторое форматирование к XML-дереву, поэтому оно содержит новые строки и отступы.
Создание XML-подэлементов
Использование ElementTree
Модуль ElementTree имеет несколько способов добавления нового элемента. Первый способ, который мы рассмотрим, – это использование функции makeelement () , которая имеет имя узла и словарь с его атрибутами в качестве параметров.
Второй способ-через класс Sub Element () , который принимает в качестве входных данных родительский элемент и словарь атрибутов.
В нашем примере ниже мы покажем оба метода. В первом случае узел не имеет атрибутов, поэтому мы создали пустой словарь ( attrib = <> ). Во втором случае мы используем заполненный словарь для создания атрибутов.
После запуска этого кода полученный XML файл будет выглядеть следующим образом:
Как мы видим при сравнении с исходным файлом, элемент “second items” и его подэлемент “second item” были добавлены. Кроме того, узел “второй элемент” имеет в качестве атрибута “имя 2”, а его текст – “seconditemabc”, как и ожидалось.
Удаление XML-элементов
Использование ElementTree
Как вы, вероятно, и ожидали, модуль ElementTree обладает необходимой функциональностью для удаления атрибутов и подэлементов узла.
В приведенном ниже коде показано, как удалить атрибут узла с помощью функции pop () . Функция применяется к параметру объекта attrib . Он задает имя атрибута и устанавливает его в None .
Результатом будет следующий XML-файл:
Как мы видим в приведенном выше XML-коде, первый элемент не имеет атрибута “name”.
Удаление одного подэлемента
Один конкретный подэлемент может быть удален с помощью функции remove . Эта функция должна указать узел, который мы хотим удалить.
Следующий пример показывает нам, как его использовать:
Результатом будет следующий XML-файл:
Как мы видим из приведенного выше XML-кода, теперь существует только один узел “элемент”. Второй был удален из исходного дерева.
Удаление всех подэлементов
Модуль ElementTree представляет нам функцию clear () , которая может быть использована для удаления всех подэлементов данного элемента.
В приведенном ниже примере показано, как использовать clear() :
Результатом будет следующий XML-файл:
Как мы видим в приведенном выше XML-коде, все подэлементы элемента “items” были удалены из дерева.
Обертывание
Python предлагает несколько вариантов обработки XML-файлов. В этой статье мы рассмотрели модуль ElementTree и использовали его для анализа, создания, изменения и удаления XML-файлов. Мы также использовали модель minidom для анализа XML-файлов. Лично я бы рекомендовал использовать модуль ElementTree , так как он гораздо проще в работе и является более современным модулем из двух.
Источник







