- Хитрости поиска в интернете – как быстро найти, то что вам нужно
- Будьте конкретнее
- Используйте кавычки, чтобы найти конкретную фразу
- Поиск на любом сайте
- Найти слова в веб-адресе
- Поиск в заголовках веб-страниц
- Просмотр кэшированной версии сайта
- Какие страницы ссылаются на определенный сайт
- Поиск конкретных слов на веб-странице
- Ограничение поиска по доменам верхнего уровня
- Используйте Basic Math, чтобы сузить результаты поиска
- Найти конкретные форматы файлов
- Расширение запроса с помощью подстановочных знаков
- Попробуйте несколько поисковых систем
- Вывод результатов поиска и проблемы с производительностью
- Вариант пейджинга #1
- Вариант пейджинга #2
- Нюансы реализации пейджинга
Хитрости поиска в интернете – как быстро найти, то что вам нужно
Вы когда-нибудь были разочарованы результатами веб-поиска? Конечно, мы все были там! Однако, для более эффективного поиска в интернете существует несколько базовых навыков, которые необходимо изучить, чтобы сделать поиск более успешным.
Будьте конкретнее
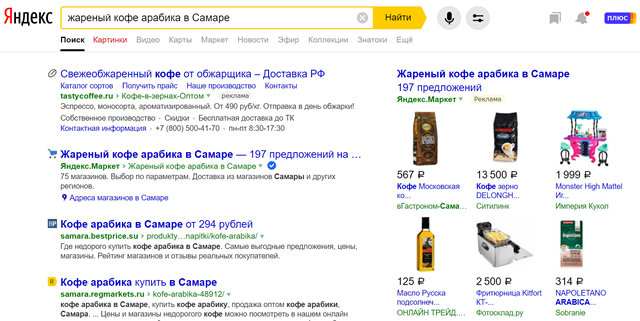
Чем более конкретнее будет поисковый запрос с самого начала, тем более успешным будет поиск. Например, если вы ищете «кофе», вы получите гораздо больше результатов, чем вам нужно; однако, если вы сузите его до фразы естественного языка «жареный кофе арабика в Самаре», вы добьетесь большего успеха.
Естественный язык – это способ, которым вы говорите в обычной жизни, хотя вы можете не говорить «жареный кофе арабика в Самаре, когда говорите о кофе, но если вы будете использовать эту конкретную фразу при поиске кофе, сваренного в Самаре, то быстрее найдёте то, что ищете.
Используйте кавычки, чтобы найти конкретную фразу
Вероятно, одна из вещей номер один, которую вы можете сделать, чтобы сэкономить время при веб-поиске, – заключение поисковой фразы в кавычки.
Когда вы используете кавычки вокруг фразы, вы предлагаете поисковой системе возвращать только те страницы, которые содержат указанный поисковый запрос в том виде, как вы его ввели. Этот совет работает почти в каждой поисковой системе и очень успешен в поиске сфокусированных результатов.
Если вы ищете точную фразу, поместите её в кавычки. В противном случае вы получите огромного количеством бесполезных результатов.
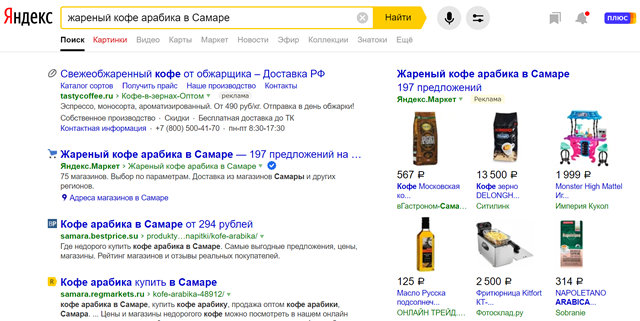
Например, если вы ищете «кошки с длинной шерстью» , ваш поиск вернёт результаты с этими словами, расположенными рядом друг с другом и в том порядке, в котором вы их хотели, а не разбросанными по странице сайта.
Если вы используете поисковую фразу без кавычек, некоторые из возвращенных результатов поиска будут содержать не все три слова, или слова могут быть в разных порядках и совсем не находиться рядом друг с другом. Таким образом, страница, которая говорит о длинноволосой блондинке, которая ненавидит кошек, может оказаться в результатах.
Поиск на любом сайте
Если вы когда-либо пытались использовать собственный инструмент поиска веб-сайта, чтобы найти что-то, и не добились успеха, вы определенно не одиноки! Однако, вы можете использовать глобальную поисковую систему для поиска по любому сайту, и, поскольку большинство инструментов поиска по сайту не так хороши, это хороший способ найти то, что вы ищете, с минимальными усилиями.
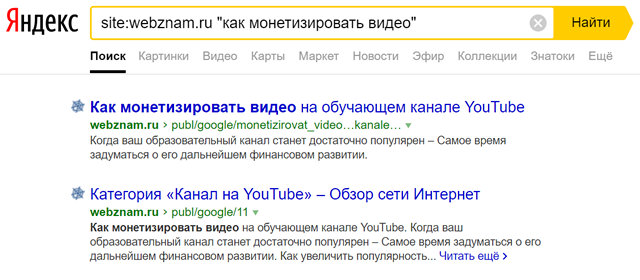
Просто используйте команду в строке поисковой системы: site: затем URL-адрес веб-сайта, по которому вы хотите выполнить поиск. Например, site:webznam.ru «как монетизировать видео», введенный в Яндексе, вернет результаты поиска только с указанного домена, связанные с монетизацией видео.
Найти слова в веб-адресе
Вы можете осуществлять поиск по веб-адресу с помощью команды inurl через Google; это позволяет вам искать слова в URL.
Это просто ещё один интересный способ поиска в интернете и поиска сайтов, которые вы, возможно, не нашли, просто введя слово или фразу. Например, если вы хотите найти результаты только с сайтов, в URL-адресе которых содержится слово «website», вы должны включить этот запрос в строку поиска Google: inurl: website. Результаты вашего поиска будут содержать только сайты с этим словом в URL.
Поиск в заголовках веб-страниц
Заголовки веб-страниц находятся в верхней части браузера и в результатах поиска. Вы можете ограничить свой поиск только заголовками веб-страниц с помощью команды поиска allintitle . Термин allintitle – это поисковый оператор, специфичный для Google, который возвращает результаты поиска, ограниченные поисковыми терминами, найденными в заголовках веб-страниц.
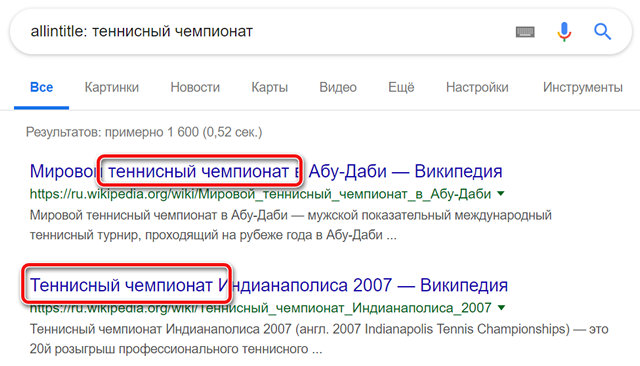
Например, если вы хотите получить результаты поиска только со словосочетанием «теннисный чемпионат», вы должны использовать этот синтаксис: allintitle: теннисный чемпионат
Это вернет результаты поиска Google со словами «теннисный чемпионат» в заголовках веб-страниц.
Просмотр кэшированной версии сайта
Если сайт или контент на странице был удалено, вы больше его не видите, верно? Это не обязательно правда. Google хранит кэшированную копию большинства сайтов. Это архивная версия веб-сайта, которая позволяет вам легко просматривать информацию или страницы, которые были удалены (по какой-либо причине).
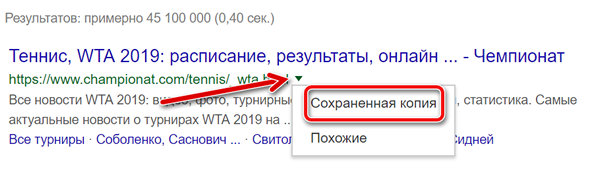
Это также удобная функция, когда веб-сайт страдает от слишком большого трафика и не отображается правильно.
Какие страницы ссылаются на определенный сайт
Если вы хотите узнать, какие сайты ссылаются на определенную страницу, вы можете узнать это, воспользовавшись оператором link: Этот оператор в сочетании с URL-адресом веб-сайта показывает, какие страницы ссылаются на этот URL-адрес.
Например, если вы хотите знать, какие страницы ссылаются на такой сайт, как наш, вы должны использовать эту команду поиска: link:webznam.ru
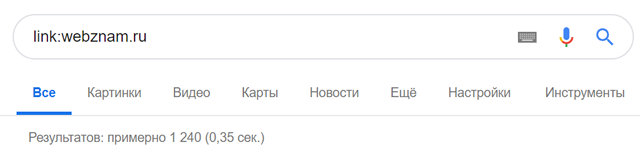
Результатом этого поиска стали 1240 страниц других сайтов, которые ссылаются на сайт WebZnam.
Поиск конкретных слов на веб-странице
Скажем, вы ищете конкретную концепцию или тему, возможно, чьё-то имя, бизнес или конкретную фразу. Вы используете свою любимую поисковую систему, нажимаете на несколько страниц и кропотливо просматриваете тонны контента, чтобы найти то, что ищете. Правильно?
Не обязательно. Вы можете использовать чрезвычайно простой трюк веб-поиска для поиска слов на веб-странице, и это будет работать в любом браузере, который вы используете.
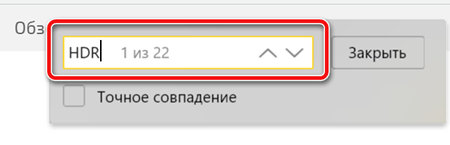
Откройте страницу сайта, нажмите Ctrl + F , а затем введите искомое слово в появившемся поле поиска. Всё просто, и вы можете использовать его в любом веб-браузере, на любом веб-сайте.
Ограничение поиска по доменам верхнего уровня
Если вы хотите ограничить область поиска определенным доменом, например .edu, .org, .ru и т.д., вы можете использовать команду site: для этого. Это работает в большинстве популярных поисковых систем и является отличным способом сузить ваш поиск до очень определенного уровня.
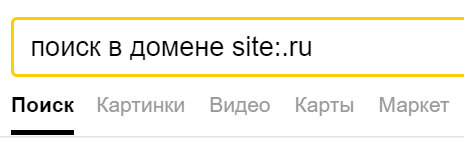
Используйте Basic Math, чтобы сузить результаты поиска
Ещё один обманчиво простой способ поиска в интернете заключается в использовании сложения и вычитания для повышения релевантности результатов поиска. Базовая математика может действительно помочь вам в поиске (ваши учителя всегда говорили вам, что когда-нибудь вы будете использовать математику в реальной жизни, верно?). Это называется булевым поиском и является одним из руководящих принципов, по которым большинство поисковых систем формируют свои результаты поиска.
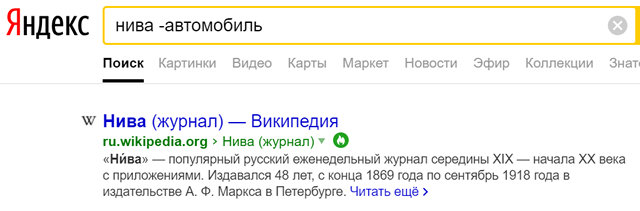
Например, вы ищете «нива», но вы получите много результатов об автомобиле марки «Нива». Чтобы решить проблему, просто объедините здесь несколько правил веб-поиска: нива -автомобиль. Теперь ваши результаты вернутся без всех этих страниц об автомобилях.
Найти конкретные форматы файлов
Поисковые системы не просто индексируют веб-страницы, написанные на HTML и других языках разметки. Вы также можете использовать их для поиска большинства популярных форматов файлов, включая файлы PDF, документы Word и электронные таблицы Excel.
Выполняйте поиск по типу файла с помощью команды filetype:(type) , заменяя (type) расширением файла, который вы хотите найти. Например, если вы хотите искать только файлы PDF, которые ссылаются на «длинношерстных кошек», ваш запрос будет выглядеть так: filetype:pdf «длинношерстных кошек».
Расширение запроса с помощью подстановочных знаков
Вы можете использовать «подстановочные» символы, чтобы расширить поисковый запрос. Эти символы подстановки включают * (звездочка), # (хэштег) и ? (вопросительный знак).
Используйте подстановочные знаки, если хотите расширить поиск. Например, если вы ищете сайты, которые обсуждают грузовики и темы, связанные с грузовиками, не ищите просто «грузовик», а найдите грузовик*. Это вернёт страницы, которые содержат слово «грузовик», а также страницы, которые содержат «грузовик», «грузоперевозки», «форум водителей грузовиков» и так далее.
Попробуйте несколько поисковых систем
Не впадайте в рутину использования одной поисковой системы для всех ваших поисковых запросов. Каждая поисковая система возвращает разные результаты. Кроме того, существует множество поисковых систем, которые фокусируются на определенных нишах: игры, блоги, книги, форумы и т.д.

Чем внимательнее вы будете выбирать поисковую систему, тем успешнее будут ваши поиски. Проверьте этот список поисковых систем, чтобы использовать в следующий раз, когда вы что-то ищете.
У вас будет большой соблазн воспользоваться вашей любимой поисковой системы и использовать только самые известные функции; тем не менее, большинство поисковых систем имеют широкий спектр расширенных опций поиска, инструменты и сервисы, которые позволяют здорово экономить время. Всё это может сделать ваши поиски более продуктивными.
Кроме того, если вы только начинаете изучать, как искать в интернете, легко оказаться перегруженным огромным количеством информации, которая доступна вам, особенно если вы ищете что-то очень конкретное. Не сдавайтесь! Продолжайте пробовать, и не бойтесь пробовать новые поисковые системы, новые комбинации фраз, новые методы веб-поиска и т.д.
Источник
Вывод результатов поиска и проблемы с производительностью
Один из типовых сценариев во всех привычных нам приложениях — поиск данных по определенным критериям и вывод их в удобном для чтения виде. Тут же могут быть дополнительные возможности по сортировке, группировке, постраничному выводу. Задача, по идее, тривиальная, но при ее решении многие разработчики делают ряд ошибок, из-за которых потом страдает производительность. Попробуем рассмотреть различные варианты решений этой задачи и сформулировать рекомендации по выбору наиболее эффективной реализации.

Вариант пейджинга #1
Самый простой вариант, который приходит в голову — это постраничный вывод результатов поиска в его самом классическом в виде.

Предположим, в приложении используется реляционная база данных. В этом случае для вывода информации в таком виде нужно будет выполнить два SQL запроса:
- Получить строки для текущей страницы.
- Посчитать общее количество строк, соответствующее критериям поиска — это нужно для показа страниц.
Рассмотрим первый запрос на примере тестовой MS SQL базы AdventureWorks для 2016 сервера. Для этой цели будем использовать таблицу Sales.SalesOrderHeader:
Приведенный выше запрос выведет первые 50 заказов из списка, отсортированного по убыванию даты добавления, другими словами — 50 последних заказов.
Выполняется он быстро на тестовой базе, но давайте посмотрим на план выполнения и статистику ввода-вывода:
Получить статистику ввода/вывода для каждого запроса можно, выполнив в среде выполнения запросов команду SET STATISTICS IO ON.
Как видно из плана выполнения, наиболее ресурсоемкой является сортировка всех строк исходной таблицы по дате добавления. И проблема в том, что чем больше в таблице будет появляться строк, тем «тяжелее» будет сортировка. На практике таких ситуаций следует избегать, поэтому добавим индекс на дату добавления и посмотрим, изменилось ли потребление ресурсов:
Очевидно, стало намного лучше. Но все ли проблемы решены? Изменим запрос на поиск заказов, где суммарная стоимость товаров превышает 100 долларов:
Имеем забавную ситуацию: план запроса ненамного хуже предыдущего, но фактическое количество логических чтений почти в два раза больше, чем при полном скане таблицы. Выход есть — если из уже существующего индекса сделать составной и вторым полем добавить суммарную цену товаров, то снова получим 165 logical reads:
Эту серию примеров можно продолжать еще долго, но две основных мысли, которые я хочу здесь выразить, такие:
- Добавление любого нового критерия или порядка сортировки в поисковый запрос может существенно повлиять на скорость его выполнения.
- Но если нам необходимо вычитать только часть данных, а не все результаты, подходящие под условия поиска — есть много способов оптимизировать такой запрос.
Теперь перейдем ко второму запросу, упомянутому в самом начале — к тому, который считает количество записей, удовлетворяющих поисковому критерию. Возьмем тот же пример — поиск заказов, которые дороже 100 долларов:
При наличии составного индекса, указанного выше, получаем:
То, что запрос проходит весь индекс целиком — неудивительно, так как поле SubTotal стоит не на первой позиции, поэтому запрос не может им воспользоваться. Проблема решается добавлением еще одного индекса на поле SubTotal, и по итогу дает уже всего 48 logical reads.
Можно привести еще несколько примеров запросов на подсчет количества, но суть останется той же: получение порции данных и подсчет общего количества — это два принципиально разных запроса, и каждый требует своих мер для оптимизации. В общем случае не получится найти комбинацию индексов, которая одинаково хорошо работает для обоих запросов.
Соответственно, одно из важных требований, которое следует уточнить при разработке такого поискового решения — действительно ли бизнесу важно видеть общее количество найденных объектов. Зачастую бывает, что нет. А навигация по конкретным номерам страницы, на мой взгляд — решение с очень узкой областью применения, так как большинство сценариев с пейджингом выглядит как «перейти на следующую страницу».
Вариант пейджинга #2
Предположим, пользователям не важно знание общего количества найденных объектов. Попробуем упростить поисковую страницу:
По факту изменилось только то, что нет возможности переходить по конкретным номерам страниц, и теперь этой таблице для отображения не нужно знать, сколько всего их может быть. Но возникает вопрос — а как таблица узнает, есть ли данные для следующей страницы (чтобы правильно отобразить ссылку «Next»)?
Ответ очень простой: можно вычитывать из базы на одну запись больше, чем нужно для отображения, и наличие этой «дополнительной» записи и будет показывать, есть ли следующая порция. Таким образом, для получения одной страницы данных нужно будет выполнить всего один запрос, что существенно улучшает производительность и облегчает поддержку такой функциональности. У меня на практике был случай, когда отказ от подсчета общего количества записей ускорил выдачу результатов в 4-5 раз.
Для этого подхода существует несколько вариантов пользовательского интерфейса: команды «назад» и «вперед», как в примере выше, кнопка «загрузить еще», которая просто добавляет новую порцию в отображаемые результаты, «бесконечная прокрутка», которая работает по принципу «загрузить еще», но сигналом для получения следующей порции является прокрутка пользователем всех выведенных результатов до конца. Каким бы ни было визуальное решение, принцип выборки данных остается таким же.
Нюансы реализации пейджинга
Во всех примерах запросов, приведенных выше, используется подход «смещение + количество», когда в самом запросе указывается с какой по порядку строки результата и какое количество строк нужно вернуть. Сперва рассмотрим, как лучше организовать передачу параметров в этом случае. На практике я встречал несколько способов:
- Порядковый номер запрашиваемой страницы (pageIndex), размер страницы (pageSize).
- Порядковый номер первой записи, которую нужно вернуть (startIndex), максимальное количество записей в результате (count).
- Порядковый номер первой записи, которую нужно вернуть (startIndex), порядковый номер последней записи, которую нужно вернуть (endIndex).
На первый взгляд может показаться, что это настолько элементарно, что никакой разницы нет. Но это не так — наиболее удобным и универсальным вариантом является второй (startIndex, count). На это есть несколько причин:
- Для подхода с вычиткой +1 записи, приведенного выше, первый вариант с pageIndex и pageSize крайне неудобен. Например, мы хотим отображать 50 записей на странице. Согласно приведенному выше алгоритму, нужно читать на одну запись больше, чем надо. Если этот «+1» не заложен на сервере, получается, что для первой страницы мы должны запрашивать записи с 1 по 51, для второй — с 51 по 101 и т.д. Если указать размер страницы 51 и увеличивать pageIndex, то вторая страница вернет с 52 по 102 и т.д. Соответственно, в первом варианте единственный способ нормально реализовать кнопку перехода на следующую страницу — закладывать на сервере вычитку «лишней» строки, что будет очень неявным нюансом.
- Третий вариант вообще не имеет смысла, так как для выполнения запросов в большинстве баз данных все равно нужно будет передать количество, а не индекс последней записи. Пусть вычитание startIndex из endIndex и элементарная арифметическая операция, но она здесь лишняя.
Теперь следует описать недостатки реализации пейджинга через «смещение + количество»:
- Получение каждой следующей страницы будет затратнее и медленнее, чем предыдущей, потому что базе данных все равно нужно будет пройти все записи «с начала» согласно критериям поиска и сортировки, после чего остановиться на нужном фрагменте.
- Не все СУБД могут поддерживать этот подход.
Альтернативы есть, но они тоже неидеальны. Первый из таких подходов называется «keyset paging» или «seek method» и заключается в следующем: после получения порции можно запоминать значения полей в последней записи на странице, а затем использовать их для получения следующей порции. Например, мы выполняли такой запрос:
И в последней записи получили значение даты заказа ‘2014-06-29’. Тогда для получения следующей страницы можно будет попытаться выполнить такое:
Проблема в том, что OrderDate — неуникальное поле и условие, указанное выше, с большой вероятностью пропустит много нужных строк. Для внесения однозначности в этот запрос, необходимо добавить к условию уникальное поле (предположим, что 75074 — последнее значение первичного ключа из первой порции):
Этот вариант будет работать корректно, но в общем случае его будет тяжело оптимизировать, так как условие содержит оператор OR. Если с ростом OrderDate растет значение первичного ключа, то условие можно упростить, оставив только фильтр по SalesOrderID. Но если между значениями первичного ключа и поля, по которому отсортирован результат, нет строгой корреляции — в большинстве СУБД избежать этого OR не получится. Известным мне исключением является PostgreSQL, где в полной мере поддерживается сравнение кортежей, и указанное выше условие можно записать как «WHERE (OrderDate, SalesOrderID) 50 . На заполнение такого массива данных не хватит ни памяти, ни времени. Тут можно возразить и сказать, что не все комбинации реальны и пользователь редко когда выберет больше 5-10 критериев. Да, можно сделать ленивую загрузку и кеширование количества только для того, что когда-либо было выбрано, но чем больше будет вариантов выбора, тем менее эффективным будет такой кеш и тем более заметными будут проблемы с временем отклика (особенно если набор данных регулярно изменяется).
К счастью, подобная задача уже давно имеет достаточно эффективные решения, предсказуемо работающие на больших объемах данных. Для любого из этих вариантов имеет смысл разделить пересчет фасетов и получение страницы результатов на два параллельных обращения к серверу и организовать интерфейс пользователя таким образом, что загрузка данных по фасетам «не мешает» отображению результатов поиска.
- Вызывать полный пересчет «фасетов» как можно реже. Например, не пересчитывать все на каждом изменении критериев поиска, а вместо этого находить общее количество результатов, соответствующих текущим условиям, и предлагать пользователю их показать — «1425 записей найдено, показать?» Пользователь может либо продолжить менять условия поиска, либо нажать кнопку «показать». Только во втором случае будут выполнены все запросы по получению результатов и пересчету количеств на всех «фасетах». При этом, как несложно заметить, придется иметь дело с запросом на получение общего количества результатов и его оптимизацией. Этот способ можно встретить во многих небольших интернет-магазинах. Очевидно, что это не панацея для данной проблемы, но в простых случаях может быть неплохим компромиссом.
- Использовать search engine для поиска результатов и подсчета фасетов, такие как Solr, ElasticSearch, Sphinx и другие. Все они рассчитаны на построение «фасетов» и делают это достаточно эффективно за счет инвертированного индекса. Как устроены поисковые системы, почему они в таких случаях эффективнее баз данных общего назначения, какие есть практики и подводные камни — это тема для отдельной статьи. Здесь же я хочу обратить внимание, что search engine не может быть заменой основного хранилища данных, используется он как дополнение: любые изменения в основной базе, имеющие значение для поиска, синхронизируются в поисковый индекс; механизм поиска взаимодействует обычно только с search engine и не обращается к основной базе. Один из самых важных моментов здесь — как организовать эту синхронизацию надежно. Все зависит от требований к «времени реакции». Если время между изменением в основной базе и его «проявлением» в поиске не критично, можно сделать сервис, который раз в несколько минут ищет недавно измененные записи и их индексирует. Если требуется минимально возможное время реакции, можно реализовать что-то типа transactional outbox для отправки обновлений в поисковый сервис.
Источник







