- Вывод последних K строк входного файла на C++
- Авторизуйтесь
- Вывод последних K строк входного файла на C++
- Как в SQL получить первые (или последние) строки запроса? TOP или OFFSET?
- Получаем первые строки результата SQL запроса
- Исходные данные для примеров
- Получаем первые строки запроса с помощью TOP
- Получаем первые строки запроса с помощью OFFSET-FETCH
- Как вывести последние строки SQL запроса?
- Получаем последние строки SQL запроса с помощью TOP
- Получаем последние строки SQL запроса с помощью OFFSET-FETCH
- Команда tail Linux
- Команда tail в Linux
- Использование tail
- Выводы
Вывод последних K строк входного файла на C++
Авторизуйтесь
Вывод последних K строк входного файла на C++
Можно действовать прямо — подсчитать количество строк (N) и вывести строки с N-K до N. Для этого понадобится дважды прочитать файл, что очень неэффективно. Давайте найдем решение, которое потребует прочитать файл только один раз и выведет последние K строк.
Можно создать массив для K строк и прочитать последние K строк. В нашем массиве там будут храниться строки от 1 до K, затем от 2 до K+1, затем от 3 до K+2 и т.д. Каждый раз, считывая новую строку, мы будем удалять самую старую строку из массива.
Вы можете удивиться: разве может быть эффективным решение, требующее постоянного сдвига элементов в массиве? Это решение станет эффективным, если мы правильно реализуем сдвиг. Вместо того чтобы каждый раз выполнять сдвиг массива, можно «закольцевать» массив.
Используя такой массив, читая новую строку, мы всегда будем заменять самый старый элемент. Самый старый элемент будет храниться в отдельной переменной, которая будет меняться при добавлении новых элементов.
Белкасофт , Санкт-Петербург, можно удалённо , От 120 000 до 190 000 ₽
Пример использования закольцованного массива:
Приведенный далее код реализует этот алгоритм:
Мы считываем весь файл, но в памяти хранится только 10 строк.
Разбор взят из перевода книги Г. Лакман Макдауэлл и предназначен исключительно для ознакомления.
Если он вам понравился, то рекомендуем купить книгу «Карьера программиста. Как устроиться на работу в Google, Microsoft или другую ведущую IT-компанию».
Источник
Как в SQL получить первые (или последние) строки запроса? TOP или OFFSET?
Всем привет, сегодня мы поговорим о том, как в Microsoft SQL Server на языке T-SQL можно оставить только определенное количество первых строк результирующего набора данных. При этом мы рассмотрим два способа реализации этой простой задачи. Также я покажу Вам, как можно вывести, наоборот, только последние строки SQL запроса.

В языке T-SQL существует две стандартные возможности, которые позволяют нам применить фильтр к результирующему набору данных, иными словами, оставить в результате только определённое количество строк. Это могут быть первые строки, с учётом сортировки, что достаточно часто требуется при работе с базами данных на SQL, или последние строки, а также существует возможность вывести любой набор строк, например, пропустить первые строки и вывести определённое количество следующих строк.
Как я уже отметил, существует два способа фильтрации результирующего набора данных, первый – это использование фильтра TOP, и второй – это использование конструкции OFFSET-FETCH, которую мы подробно рассмотрели в отдельном материале — «OFFSET-FETCH в T-SQL – описание и примеры использования».
Получаем первые строки результата SQL запроса
Сейчас давайте я покажу, как можно вывести первые строки результирующего набора данных, сначала мы рассмотрим пример с использованием TOP, а затем сделаем то же самое только с помощью OFFSET-FETCH.
Но для начала давайте определимся с исходными данными, чтобы Вы понимали, какие данные у нас есть и что мы получаем в итоге.
Исходные данные для примеров
В качестве сервера у меня выступает Microsoft SQL Server 2016 Express. А теперь давайте представим, что у нас есть таблица TestTable и в ней содержатся следующие данные (перечень товаров с указанием цены).

Получаем первые строки запроса с помощью TOP
TOP – это инструкция T-SQL, с помощью которой можно ограничить число строк в результирующем наборе данных SQL запроса.
Синтаксис
TOP (Число строк) [PERCENT]
У инструкции TOP несколько параметров:
- Число строк – сразу после ключевого слова TOP в скобочках мы указываем число, которое будет означать количество строк в итоговом результате. В инструкции SELECT допускается указание данного числа без скобочек, однако это не рекомендуется;
- PERCENT – параметр, который говорит, что в запросе необходимо оставить не фактическое количество строк, а процент строк от общего количества, т.е. число, указанное ранее, будет означать процент, а не количество;
- WITH TIES – параметр, который говорит, что в результирующий набор необходимо включить и записи с тем же значением, что и последняя строка, в случае наличия подобных записей. Например, если Вам нужно получить 5 самых дорогих товаров, при этом на пятом месте запись с ценой 100, а на шестом месте также цена 100, так вот, без параметра WITH TIES Вам вернётся 5 строк, а если данный параметр указать — вернется 6 строк.
Фильтр TOP обычно применяется с сортировкой данных (ORDER BY), однако это необязательно, можно применять данный фильтр и без сортировки данных, только в этом случае строки будут возвращаться в произвольном порядке (так, как они хранятся).
Пример SQL запроса с TOP – выводим первые 5 строк
Допустим, нам нужно получить 5 самых дорогих товаров, для этого пишем следующий запрос.

В данном случае мы указали сортировку по уменьшению цены (ORDER BY Price DESC), а также применили фильтр TOP (5), для ограничения вывода строк результирующего набора.
Пример SQL запроса с TOP и параметром WITH TIES
Сейчас давайте запустим два запроса, в обоих случаях мы будем запрашивать 4 самых дорогих товара, т.е. применим фильтр TOP (4), однако во втором запросе дополнительно мы укажем параметр WITH TIES и посмотрим на разницу итогового результата.

В итоге мы очень хорошо видим разницу, в первом случае вывелось 4 строки, а во втором 5, так как товар в 5 строке имеет точно такую же цену, как и товар в 4 строке.
Пример SQL запроса с TOP и параметром PERCENT
В этом примере давайте просто выведем 50 процентов итогового набора записей, т.е. половину. Для этого мы используем параметр PERCENT.

Так как у нас в таблице TestTable всего 8 записей, нам вывелось 4 строки, т.е. как раз 50 процентов.
Получаем первые строки запроса с помощью OFFSET-FETCH
Вторым способом получения первых строк является использование конструкции OFFSET-FETCH, однако она появилась только в 2012 версии SQL сервер, до этого, соответственно, этот способ использовать не получится.
У конструкции OFFSET-FETCH отсутствуют такие параметры, как PERCENT и WITH TIES, которые есть у фильтра TOP, однако у OFFSET-FETCH есть одно очень важное преимущество – это возможность пропускать определенное количество первых строк.
Примечание! OFFSET-FETCH — это часть конструкции ORDER BY, поэтому без сортировки использовать OFFSET-FETCH не удастся. Также не получится одновременно использовать OFFSET-FETCH и TOP в одном запросе SELECT.
Пример SQL запроса с OFFSET-FETCH — выводим первые 5 строк
Чтобы вывести первые строки с помощью конструкции OFFSET-FETCH, нам нужно в секции OFFSET указать 0, т.е. начинать вывод сразу с первой строки (если указать другое число, то именно такое количество строк будет пропущено). В секции FETCH мы соответственно указываем 5.

Результат, мы видим, точно такой же, как и в случае с TOP.
Как вывести последние строки SQL запроса?
Если Вам нужно получить не первые строки результирующего набора данных, а последние (например, последние записи в таблице), причем с той же самой сортировкой, то Вы также можете использовать два способа, т.е. и TOP, и OFFSET. В обоих случаях нам нужно будет немного усложнить запросы.
Получаем последние строки SQL запроса с помощью TOP
В случае с TOP нам дополнительно потребуется использовать конструкцию WITH (CTE – обобщенное табличное выражение), для того чтобы выполнить сортировку по идентификатору для применения фильтра TOP, т.е. отобрать самые последние записи. А после этого мы уже можем отсортировать строки так, как нам нужно.

Как видите, нам вывелись 5 последних строк.
Получаем последние строки SQL запроса с помощью OFFSET-FETCH
Для получения последних строк с помощью OFFSET-FETCH нам потребуется предварительно узнать общее количество строк, для того чтобы определить, сколько строк нужно пропустить. Это можно сделать как с помощью вложенного запроса, так и с помощью предварительного сохранения нужного нам значения в переменной. Я покажу способ с использованием переменной.

Итоговый результат такой же, как и в запросе с TOP.
Теперь Вы знаете, как с помощью TOP и OFFSET получать первые и последние строки результирующего набора данных, который возвращает SQL запрос.
В данной статье мы затронули одну очень маленькую возможность языка T-SQL, но их, как Вы понимаете, гораздо больше, поэтому, если Вы начинающий программист и хотите изучить язык T-SQL, то рекомендую посмотреть мои видеокурсы по T-SQL, с помощью которых Вы «с нуля» научитесь работать с SQL и программировать на T-SQL.
У меня на этом все, удачи в освоении языка T-SQL!
Источник
Команда tail Linux
Все знают о команде cat, которая используется для просмотра содержимого файлов. Но в некоторых случаях вам не нужно смотреть весь файл, иногда достаточно посмотреть только то, что находится в конце файла. Например, когда вы хотите посмотреть содержимое лог файла, то вам не нужно то, с чего он начинается, вам будет достаточно последних сообщений об ошибках.
Для этого можно использовать команду tail, она позволяет выводить заданное количество строк с конца файла, а также выводить новые строки в интерактивном режиме. В этой статье будет рассмотрена команда tail Linux.
Команда tail в Linux
Перед тем как мы будем рассматривать примеры tail linux, давайте разберем ее синтаксис и опции. А синтаксис очень прост:
$ tail опции файл
По умолчанию утилита выводит десять последних строк из файла, но ее поведение можно настроить с помощью опций:
- -c — выводить указанное количество байт с конца файла;
- -f — обновлять информацию по мере появления новых строк в файле;
- -n — выводить указанное количество строк из конца файла;
- —pid — используется с опцией -f, позволяет завершить работу утилиты, когда завершится указанный процесс;
- -q — не выводить имена файлов;
- —retry — повторять попытки открыть файл, если он недоступен;
- -v — выводить подробную информацию о файле;
В качестве значения параметра -c можно использовать число с приставкой b, kB, K, MB, M, GB, G T, P, E, Z, Y. Еще есть одно замечание по поводу имен файлов. По умолчанию утилита не отслеживает изменение имен, но вы можете указать что нужно отслеживать файл по дескриптору, подробнее в примерах.
Использование tail
Теперь, когда вы знаете основные опции, рассмотрим приемы работы с утилитой. Самый простой пример — выводим последние десять строк файла:
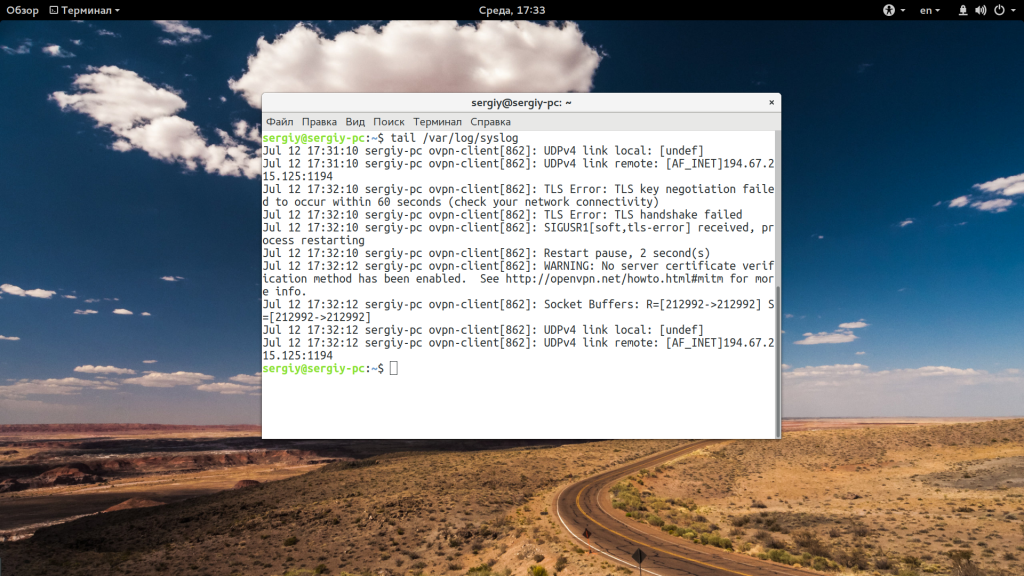
Если вам недостаточно 10 строк и нужно намного больше, то вы можете увеличить этот параметр с помощью опции -n:
tail -n 100 /var/log/syslog

Когда вы хотите отслеживать появление новых строк в файле, добавьте опцию -f:
tail -f /var/log/syslog

Вы можете открыть несколько файлов одновременно, просто перечислив их в параметрах:
tail /var/log/syslog /var/log/Xorg.0.log

С помощью опции -s вы можете задать частоту обновления файла. По умолчанию данные обновляются раз в секунду, но вы можете настроить, например, обновление раз в пять секунд:
tail -f -s 5 /var/log/syslog

При открытии нескольких файлов будет выводиться имя файла перед участком кода. Если вы хотите убрать этот заголовок, добавьте опцию -q:
tail -q var/log/syslog /var/log/Xorg.0.log

Если вас интересует не число строк, а именно число байт, то вы можете их указать с помощью опции -c:
tail -c 500 /var/log/syslog

Для удобства, вы можете выбирать не все строки, а отфильтровать интересующие вас:
tail -f /var/log/syslog | grep err
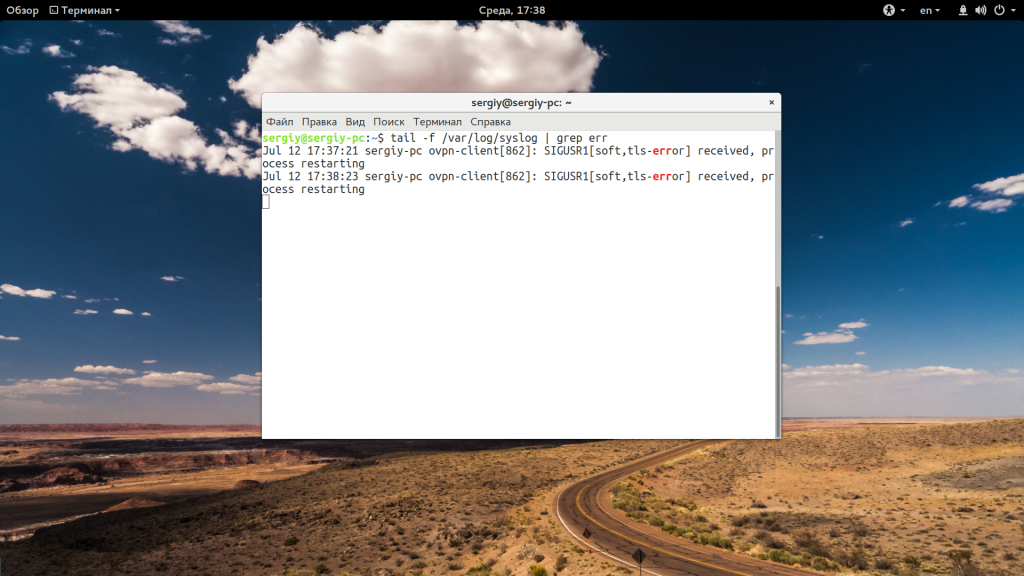
Особенно, это полезно при анализе логов веб сервера или поиске ошибок в реальном времени. Если файл не открывается, вы можете использовать опцию retry чтобы повторять попытки:
tail -f —retry /var/log/syslog | grep err
Как я говорил в начале статьи, по умолчанию опция -f или —follow отслеживает файл по его имени, но вы можете включить режим отслеживания по дескриптору файла, тогда даже если имя измениться, вы будете получать всю информацию:
tail —follow=descriptor /var/log/syslog | grep err

Выводы
В этой статье была рассмотрена команда tail linux. С помощью нее очень удобно анализировать логи различных служб, а также искать в них ошибки. Надеюсь, эта информация была полезной для вас.
Источник







