- Как посмотреть план выполнения запроса в Microsoft SQL Server
- Введение
- Типы планов выполнения запроса
- Предполагаемый план выполнения
- Действительный план выполнения
- Статистика активных запросов
- Как посмотреть план выполнения запроса
- Отображение предполагаемого плана выполнения запроса
- С помощью интерфейса SSMS
- С помощью инструкции Transact-SQL
- Отображение действительного плана выполнения запроса
- С помощью интерфейса SSMS
- С помощью инструкции Transact-SQL
- Просмотр динамической статистики запросов
- SQL-Ex blog
- Получение плана выполнения запроса в PostgreSQL
- Введение
- Объяснение синтаксиса
- ANALYZE
- VERBOSE
- COSTS
- BUFFERS
- TIMING
- SUMMARY
- FORMAT
- Примеры
- Заключение
- Обратные ссылки
- Комментарии
- SQL-Ex blog
- Изучение плана запроса в SQL
- Идентификация проблем сканирования
- Поиск планов запросов, вызывающих сканирование
- Идентификация проблем поиска закладок
- Настройка исследовательских запросов на практические цели
- Заключение
- Обратные ссылки
- Комментарии
Как посмотреть план выполнения запроса в Microsoft SQL Server
Всем привет! Сегодня мы поговорим о том, как посмотреть план выполнения запроса в Microsoft SQL Server, при этом мы рассмотрим несколько способов.

Введение
План выполнения запроса – это набор конкретных действий, выполнение которых приведет SQL запрос к итоговому результату.
Иными словами, план выполнения запроса – это то, как именно будет выполняться пользовательский запрос, т.е. как именно будет осуществляться доступ к исходным данных, в каком порядке, какие конкретные методы будут использоваться для извлечения данных из каждой таблицы, какие конкретные методы будут использованы для вычислений, фильтрации, статистической обработки и сортировки данных.
Более подробно план выполнения запроса мы рассматривали в материале
Сегодня мы с Вами поговорим о том, как посмотреть план запроса и начать его анализировать. Однако сначала обязательно стоит отметить, что существует несколько типов планов запроса.
Типы планов выполнения запроса
Оптимизатор запросов Microsoft SQL Server формирует только один план выполнения для запроса, однако существует несколько типов планов выполнения запроса, которые можно отобразить с помощью SQL Server Management Studio (SSMS).
Предполагаемый план выполнения
Предполагаемый план выполнения (Estimated Execution Plan) – это план, созданный оптимизатором запросов на основе оценок.
При создании предполагаемого плана выполнения сам запрос и в целом пакеты языка Transact-SQL не выполняются, поэтому такой план не содержит фактических метрик использования ресурсов.
Вместо этого предполагаемый план отображает наиболее вероятный план выполнения запроса, которому следовал бы SQL Server при фактическом выполнении запроса, а также этот план отображает расчетное движение строк при выполнении нескольких операторов в плане.
За счет того, что запрос фактически не выполняется, это не создает никакой серьезной задержки перед отображением предполагаемого плана выполнения запроса.
Такой план удобно использовать в тех случаях, когда запрос выполняется долго, а нам необходимо посмотреть план, который собирается использовать SQL Server для данного запроса.
Действительный план выполнения
Действительный план выполнения (Actual Execution Plan) – это план, созданный оптимизатором запросов после фактического выполнения запроса. Иными словами, план становится доступным после выполнения SQL инструкции. Поэтому такой план отображает фактические метрики использования ресурсов.
Примечание! Для того, чтобы иметь возможность просматривать план выполнения запроса пользователи должны обладать соответствующими разрешениями на запуск SQL запроса, для которого создается графический план выполнения. Кроме того, пользователям должно быть предоставлено разрешение SHOWPLAN для всех баз данных, упоминаемых в запросе.
Статистика активных запросов
Статистика активных запросов (Live Query Statistics) – это план, который создаётся в режиме реального времени. Такой план доступен во время выполнения SQL запроса и обновляется каждую секунду, что позволяет нам просматривать динамический план выполнения активного запроса.
Такая возможность позволяет нам анализировать процесс выполнения запроса в режиме реального времени по мере передачи управления от одного оператора плана запроса другому.
Динамический план запроса отображает общий ход выполнения запроса и текущую статистику выполнения на уровне оператора, например, число полученных строк, затраченное время, ход выполнения оператора и т. д. Так как эти данные доступны в режиме реального времени, чтобы их увидеть, не нужно дожидаться завершения запроса, такая статистика бывает полезна для отладки проблем с производительностью запросов. Статистика активных запросов доступна с версии SQL Server 2016.
Примечание! Эта функция предназначена в основном для диагностики. Ее использование может значительно снизить общую производительность запроса.
Как посмотреть план выполнения запроса
Посмотреть план выполнения запроса можно, конечно же, с помощью SQL Server Management Studio. При этом для каждого типа используется свой способ просмотра.
Отображение предполагаемого плана выполнения запроса
Посмотреть предполагаемый план выполнения запроса можно несколькими способами, в частности:
- С помощью интерфейса SQL Server Management Studio
- С помощью инструкции языка Transact-SQL
С помощью интерфейса SSMS
В окне создания запроса на панели инструментов нажмите кнопку «Показать предполагаемый план выполнения» (Display Estimated Execution Plan).
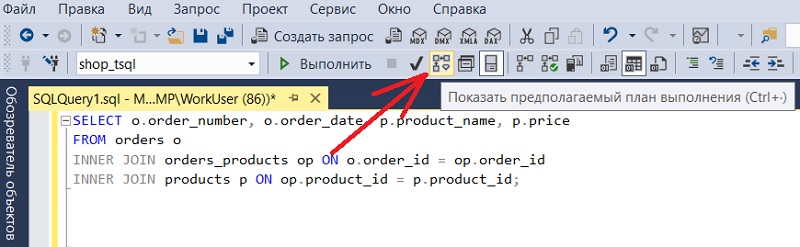
В результате откроется вкладка «План выполнения». Сам запрос, как Вы помните, в данный момент выполняться не будет.
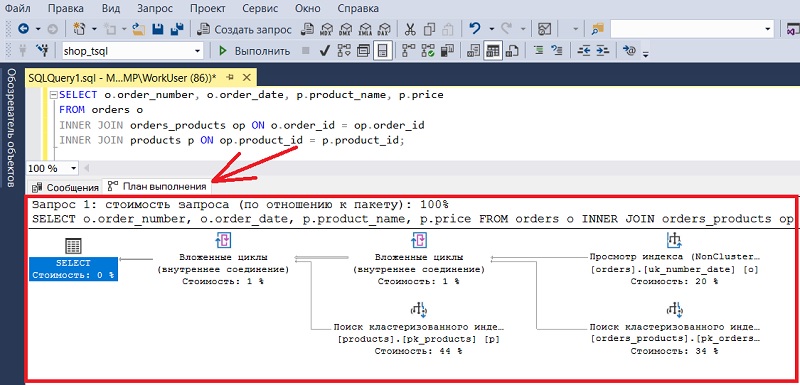
С помощью инструкции Transact-SQL
Тот же самый план выполнения можно получить с помощью следующей инструкции языка T-SQL
В результате, когда Вы будете запускать запрос на выполнение, вместо результирующего набора данных Вам будет возвращен XML документ, и если на него щелкнуть, т.е. открыть, то план выполнения запроса будет отображен графически, также как с помощью иконки на панели инструментов.
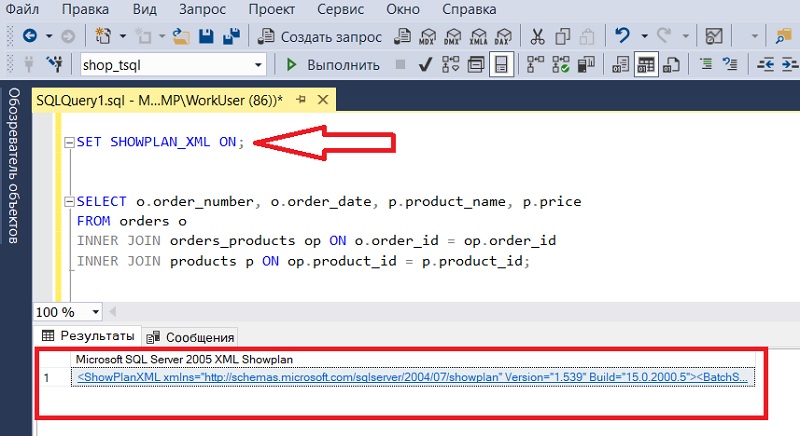
Чтобы выключить отображение плана необходимо установить данному параметру значение OFF.
Отображение действительного плана выполнения запроса
Фактический план выполнения запроса можно также посмотреть нескольким способами:
- С помощью интерфейса SQL Server Management Studio
- С помощью инструкции языка Transact-SQL
С помощью интерфейса SSMS
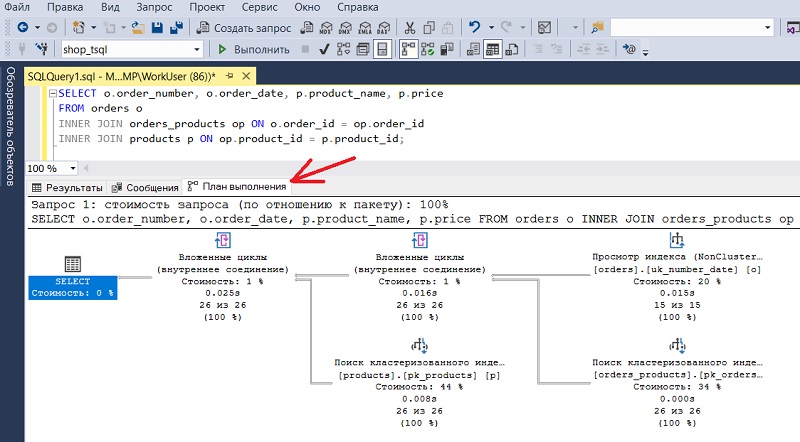
В окне создания запроса на панели инструментов нажмите кнопку «Включить действительный план выполнения» (Include Actual Execution Plan).
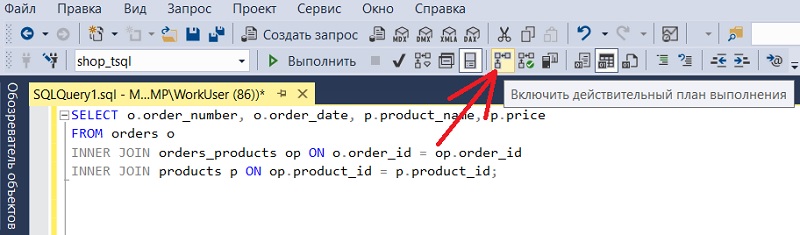
В результате, когда Вы выполните запрос, у Вас дополнительно к результатам добавится вкладка «План выполнения». В данном случае, как Вы понимаете, сам запрос будет выполнен, так как результирующий набор будет сформирован.
С помощью инструкции Transact-SQL
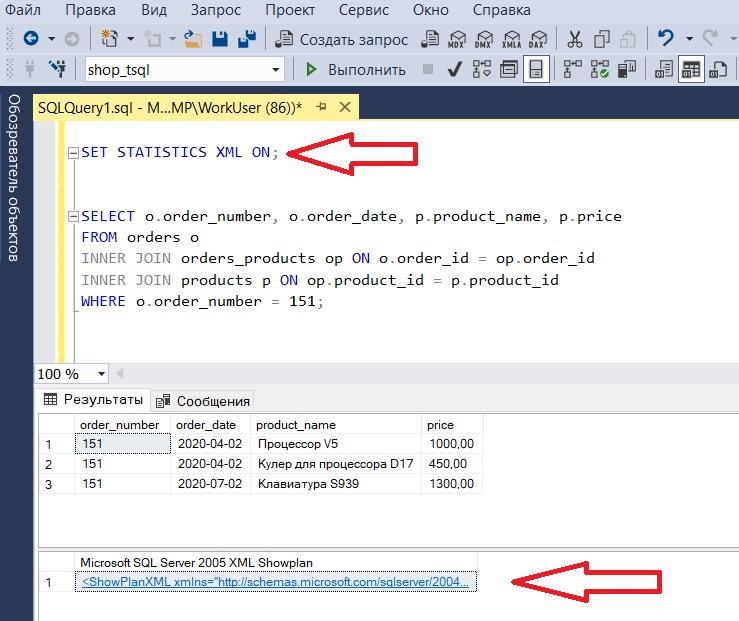
Тот же самый план выполнения можно получить с помощью следующей инструкции языка T-SQL
В результате, после выполнения запроса у Вас отобразится дополнительное окно с планом запроса формате XML. Если кликнуть на этот документ, то план выполнения запроса будет отображен графически.
Чтобы выключить отображение плана, необходимо установить данному параметру значение OFF.
Просмотр динамической статистики запросов
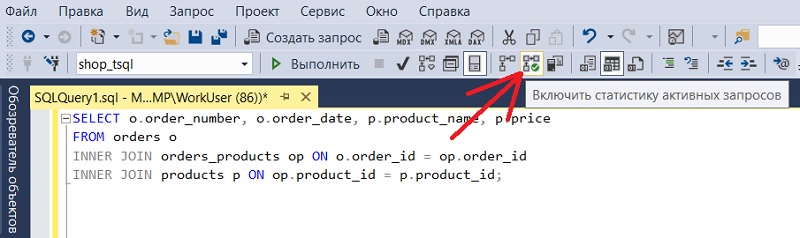
В окне создания запроса на панели инструментов нажмите кнопку «Включить статистику активных запросов» (Include Live Query Statistics).
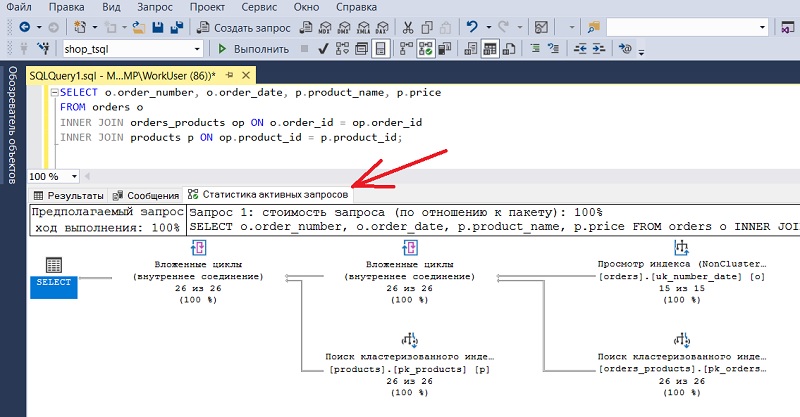
В итоге в момент выполнения запроса откроется вкладка «Статистика активных запросов», на которой в режиме реального времени можно будет наблюдать ход выполнения запроса в формате плана запроса.
Заметка! Всем тем, кто только начинает свое знакомство с языком SQL, рекомендую прочитать книгу «SQL код» – это самоучитель по языку SQL для начинающих программистов. В ней очень подробно рассмотрены основные конструкции языка.
На сегодня это все, надеюсь, материал был Вам полезен, пока!
Источник
SQL-Ex blog
Новости сайта «Упражнения SQL», статьи и переводы
Получение плана выполнения запроса в PostgreSQL
Введение
Сгенерировать план выполнения запроса позволяет ключевое слово EXPLAIN в PostgreSQL. Синтаксис создания плана в PostgreSQL имеет вид:
Для этой команды OPTION имеется много вариантов. Множественный выбор осуществляется перечислением через запятую. Вот эти варианты:
Значение Boolean может быть TRUE или FALSE. Вместо TRUE можно использовать ON или 1. Аналогично для FALSE используются OFF или 0.
Очень простой план выполнения запроса выглядит так:
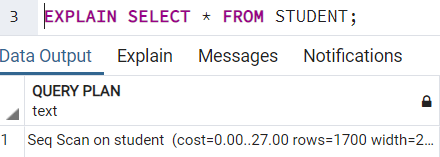
Объяснение синтаксиса
Прежде чем использовать EXPLAIN для генерации плана выполнения запроса, необходимо узнать об особенностях синтаксиса.
ANALYZE
Когда вы используете ключевое слово EXPLAIN, сначала выполняется ваш запрос PostgreSQL. После успешного выполнения запроса возвращается вся статистика времени выполнения, включая полное время на каждый узел плана и общее число строк, прочитанных запросом. Ключевое слово ANALYZE будет фактически выполнять запрос в реальном времени для сбора и подготовки плана выполнения. Поэтому, если вы выполняете следующий запрос:
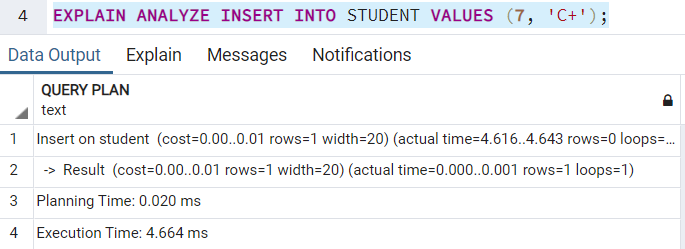
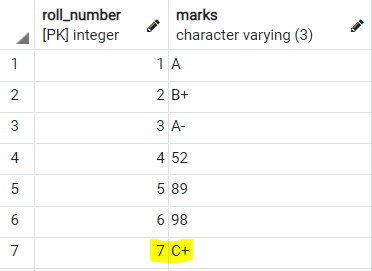
то строки на самом деле вставляются в таблицу:
VERBOSE
Это ключевое слово покажет дополнительную информацию, связанную с планом выполнения запроса. Эта опция по умолчанию имеет значение FALSE. Чтобы установить её в TRUE, можно написать:
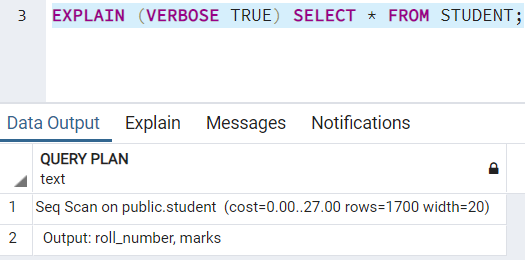
COSTS
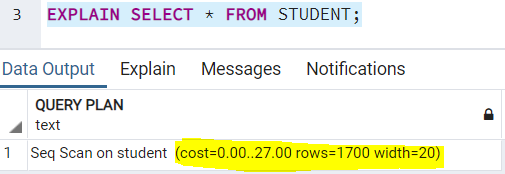
Опция COSTS вернет значение стоимости каждого шага в запросе. Сделанные оценки представляют собой произвольные значения, которые присваиваются каждому шагу при выполнении любого запроса на основе ожидаемой нагрузки на ресурсы, которую он может создать. Значение по умолчанию всегда установлено в TRUE. Вы можете использовать это ключевое слово в плане выполнения своего запроса так:
BUFFERS
BUFFERS является одним из наиболее интересных ключевых слов для проверки в плане выполнения запроса. Она в основном состоит из 2 частей — разделяемых чтений (shared read) и разделяемых обращений (shared hit). Разделяемые чтения — это число блоков, которые PostgreSQL читает с диска. Разделяемые обращения — это число блоков, которые PostgreSQL читает из кэша. PostgreSQL поддерживает свой собственный кэш. Это вид памяти для запросов, которые выполнялись ранее. Всякий раз, когда вы выполняете запрос, PostgreSQL сначала смотрит в свой кэш и, если необходимо, читает данные с диска.
Это ключевое слово имеет зависимость от ключевого слова ANALYZE, и может использоваться только вместе с ним. Значением по умолчанию является FALSE. Вы можете использовать его в плане выполнения своего запроса таки образом:
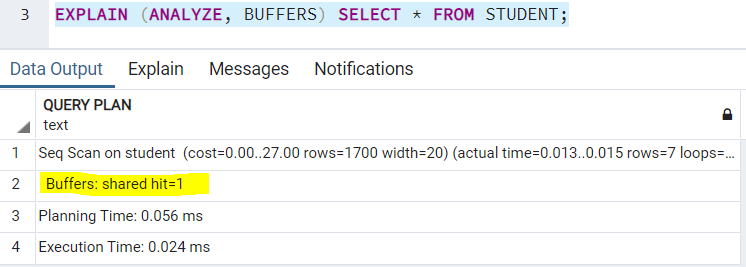
Замечание. Так как мы ранее выполняли этот запрос многократно (обсуждая другие ключевые слова), буферы показывают только разделяемые обращения, т.к. результаты находились в кэше. Если выполнить запрос с новым предложением WHERE, появятся также и разделяемые чтения.
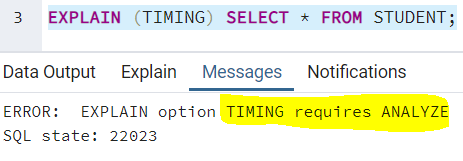
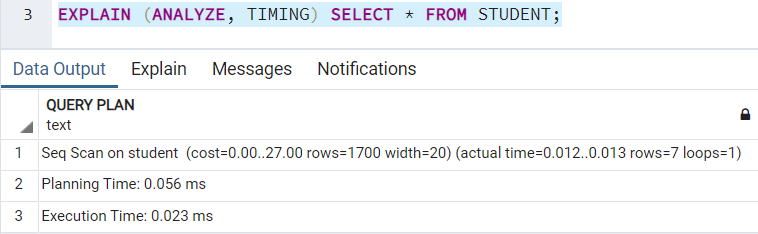
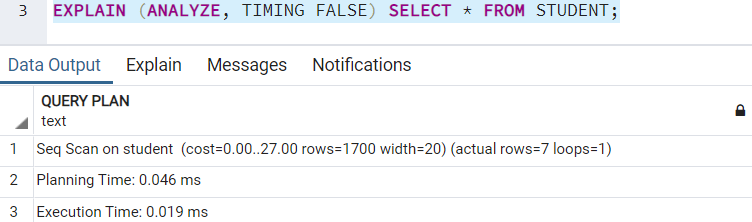
TIMING
TIMING детализирует время запуска и время выполнения на каждом узле. Значением по умолчанию является TRUE. Для его использования должно применяться ключевое слово ANALYZE. Если вы попытаетесь использовать ключевое слово TIMING без ANALYZE, то получите следующую ошибку:
План выполнения с включенным TIMING будет выглядеть так:
План выполнения с выключенным TIMING имеет вид:
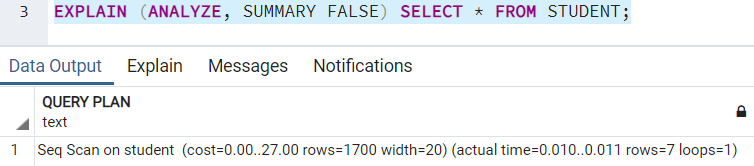
SUMMARY
Это ключевое слово добавляет итоговую информацию в план выполнения запроса. Вы можете использовать его вместе с ключевым словом ANALYZE. По умолчанию план запроса включает его. Если вы захотите выключить эту опцию, сделайте так:
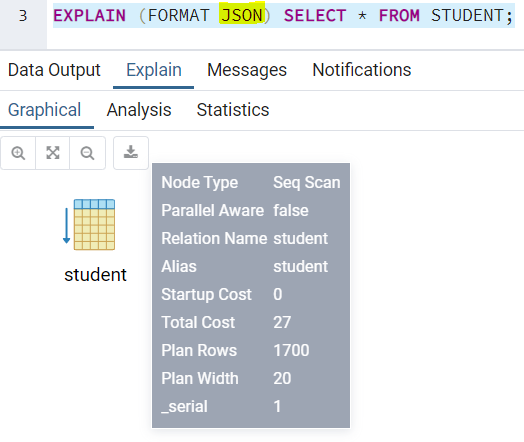
FORMAT
Это ключевое слово представляет большой интерес, если вам требуется подготовить отчет о производительности запроса или сохранить детали плана выполнения запроса для последующих ссылок. Вам потребуется указать формат для представления результата. TEXT — это значение по умолчанию. Другими вариантами являются XML, JSON и YAML. Для генерации вывода в JSON можно написать так:
Примеры
Мы уже представили много примеров выше. При этом использовался очень простой запрос. Давайте воспользуемся более близкими к реальным запросами, как те, которые используют предложение WHERE или JOIN.
Предположим, что нам нужно посмотреть план выполнения для запроса, который выводит информацию о студенте с номером 5. План выглядит так:
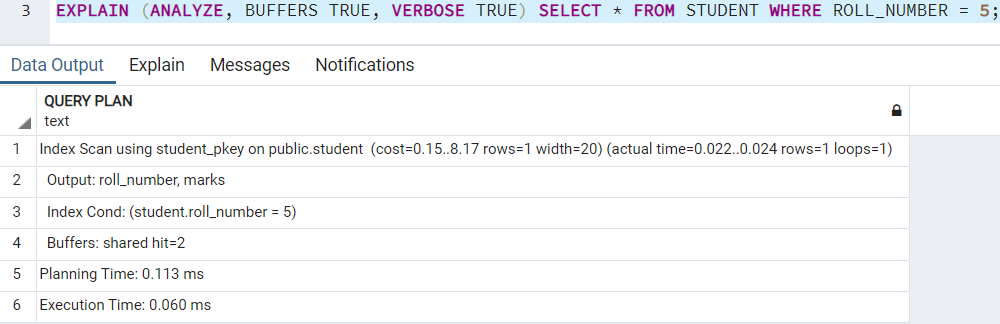
Выясним, нужны ли вам VERBOSE и BUFFERS в плане выполнения. Если необходимо проверить выходные столбцы, вы можете использовать VERBOSE. Если требуется проверить, сколько блоков было прочитано с диска, а сколько из кэша, можно использовать BUFFERS.
Теперь предположим, что нам требуется соединить 2 таблицы (например, student [содержащую номер и оценки] и home [содержащую номер, город проживания и штат]) и вернуть информацию пользователю. Тогда план выполнения будет такой:
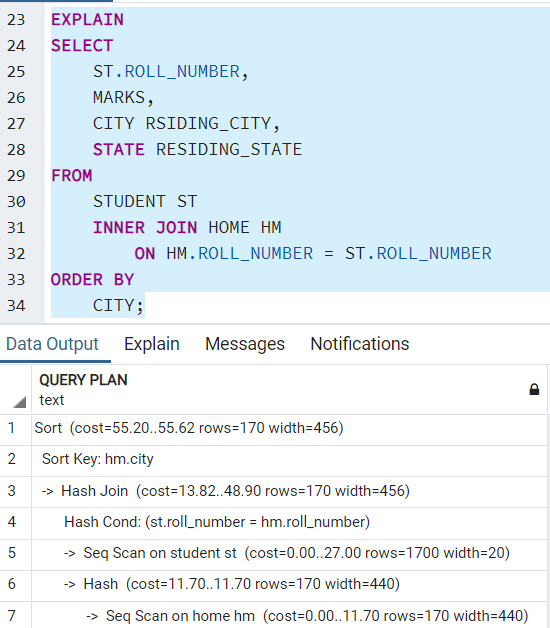
Заключение
Обратные ссылки
Нет обратных ссылок
Комментарии
Показывать комментарии Как список | Древовидной структурой
Автор не разрешил комментировать эту запись
Источник
SQL-Ex blog
Новости сайта «Упражнения SQL», статьи и переводы
Изучение плана запроса в SQL
SQL Server сохраняет наиболее часто используемые планы выполнения в кэше, поэтому их не требуется перекомпилировать при каждом выполнении запроса. Как мы можем воспользоваться этим, чтобы найти потенциальные проблемы производительности в планах выполнения? Давайте попытаемся отыскать некоторые возможности для оптимизации, используя информацию, содержащуюся в кэше планов SQL Server.
Динамическое административное представление (DMV) sys.dm_db_index_usage_stats создает отчет об использовании индексов, и мы можем использовать это DMV для обнаружения индексов, которые могут вызывать проблемы. DMV могут предоставить итоги по некоторым видам использования индексов, например, число сканирований, поисков и переходов по закладкам, на основании чего мы можем выявить не только индексы, но также базы данных, которые требуют внимания.
Вот, в частности, та важная информация, которую мы можем извлечь с помощью DMV:
- Scans: Сканирование обычно худший вариант с точки зрения производительности, поскольку в поисках нужной информации просматривается весь индекс. Вероятно, вам потребуется оптимизировать те запросы, которые приводят к интенсивному сканированию, перерабатывая сами запросы или индекс.
- Seeks: Поиск в отличие от сканирования — лучший вариант использования индекса, поэтому мы можем сравнить отношение поиска к сканированию, чтобы обнаружить те индексы, которые чаще сканируются, чем используется поиск, что может являться потенциальным источником проблем.
- Lookups: Поиск закладки происходит тогда, когда операции, выполняемой на некластеризованном индексе, требуются дополнительные столбцы для запроса, обычно использующего кластеризованный индекс. Это дорогая операция, поэтому оптимизатор запросов в отдельных случаях может принять решение о сканировании кластеризованного индекса вместо поиска закладок. В последнем случае, конечно, это даст количество сканирований, а не поиска закладок. Поэтому число поиска закладок включается только тогда, когда сканирование становится слишком дорогим, что также плохо для производительности.
Я упрощаю методы оптимизации, но в этой статье внимание сфокусировано только на том, где искать возможности для оптимизации.
DMV sys.dm_db_index_usage_stats включает информацию о действиях пользователей и системы, т.е. user_scans и system_scans, но мы можем игнорировать системную информацию.
Первым шагом является обнаружение базы данных, которая в наибольшей мере подвержена этим проблемам. Нам нужен запрос для проблем каждого типа, будь-то сканирование или поиск закладки (поиск — seek — не является проблемой, однако отношение поиска к сканированию является той информацией, которая поможет нам идентифицировать проблемы, вызванные сканированием).
Идентификация проблем сканирования
Вот запрос для поиска баз данных, которые испытывают наибольшие проблемы сканирования:
Суммирование user_scans для различных индексов большого смысла не имеет, поэтому мы вычисляем максимум и среднее значение пользовательского сканирования, чтобы найти базы данных, требующих нашего внимания.
Вот результат выполнения запроса на моем SQL Server:
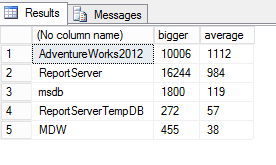
Видим, что больше всего операций сканирования происходит в базе данных adventureworks2012.
Только после выбора конкретной базы данных мы может продолжить и получить имена индексов, которые могут вызывать проблемы. Чтобы это сделать, требуется соединить эту информацию из DMV с информацией из sys.indexes и получить имя индекса.
Следующий запрос необходимо запустить на выбранной базе данных (естественно, вы измените имя базы в запросе):
Эти примеры были созданы с использованием базы данных Adventureworks2012 , которую вы можете загрузить с https://msftdbprodsamples.codeplex.com/releases/view/55330. При этом таблицы ‘bigproduct’ and ‘bigtransactionhistory’ были созданы Адамом Мачаником, и вы можете найти их скрипт на http://sqlblog.com/blogs/adam_machanic/archive/2011/10/17/thinking-big-adventure.aspx. Активность сканирования генерировалась при помощи инструмента SQL Query Stress, также разработанного Адамом, и вы можете взять его отсюда: http://dataeducation.com/sqlquerystress-the-source-code/.
Замечу, что я также использовал index_id для идентификации индекса как кластеризованного или некластеризованного. Я также включил информацию о поиске, чтобы мы могли сравнить отношение числа сканирований к поискам и решить, какой индекс требует пристального внимания.
В результате мы можем выяснить, что таблица bigproduct и её кластеризованный индекс имеют множество сканирований, поэтому мы должны сосредоточиться на них.
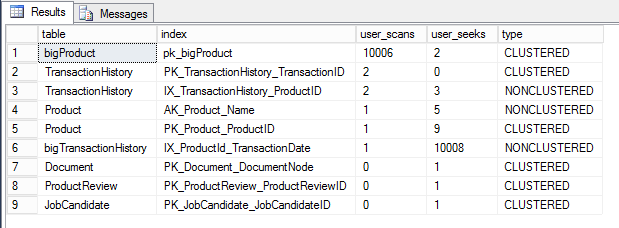
Оба запроса, которые я использовал до сих пор, были созданы для того, чтобы изучать проблемы сканирования, однако вы можете использовать эти же запросы и для проблем поиска закладок: вам просто нужно изменить поле user_scans на поле user_looups.
Поиск планов запросов, вызывающих сканирование
При помощи рассмотренных запросов мы находим, какие базы данных и индексы требуют внимания, но как обнаружить те планы запросов, с помощью которых мы найдем сами запросы, вызывающие эти проблемы?
На втором шаге мы можем использовать SQL для обнаружения проблемных планов запросов в кэше с последующим переходом к запросам, требующим оптимизации.
Используя DMV sys.dm_exec_query_stats, мы можем выбрать все запросы в кэше и идентифицировать проблемные планы.
Это DMV имеет дескриптор, который мы можем использовать для получения плана запроса, и дескриптор, который мы можем использовать для получения текста запроса. Для их получения мы будем использовать динамические административные функции (DMF) sys.dm_exec_query_plan и sys.dm_exec_sql_text соответственно. Нам потребуется CROSS APPLY.
Поле query_plan представлен в виде XML, однако, если вы наблюдаете результат в сетке (result to grid), окно запроса в SSMS распознает схему и показывает графический план при щелчке по ссылке. Это удобно для изучения отдельных планов, но не для систематического поиска по множеству планов, отвечающих конктерному критерию. Если мы не сможем фильтровать результаты на основе XML, нам придется просматривать их по одному. Поэтому лучшим вариантом является использование Xquery.
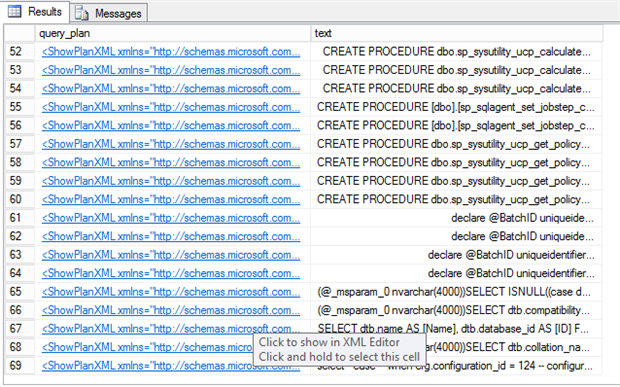
Если щелкнуть по полю query_plan, мы увидим графический план запроса
Для того, чтобы использовать XQuery не вслепую для поиска в XML, нам потребуется информация об используемой XML-схеме.
Схема этого документа XML опубликована на http://schemas.microsoft.com/sqlserver/2004/07/showplan
Существует множество возможностей для обнаружения проблем выполнения с помощью этого метода, но я смогу показать лишь несколько. А для выполнения различных исследований, вам потребуется изучить схему.
Просматривая схему, мы обнаружим, что имеется элемент RelOp с атрибутом LogicalOp, который мы можем использовать для нахождения всех планов, которые включают сканирование индекса или сканирование таблицы. Давайте рассмотрим запрос:
XML плана запроса является типизированным, поэтому нам нужно определить пространство имен для того, чтобы использовать Xquery. Схема несколько сложна, и вам нужно быть внимательными при написании собственных запросов. Например, возможны ошибки при запросе элемента IndexScan, поскольку элемент IndexScan используется во всех операциях с индексами, включая поиск и поиск закладок.
Следующий шаг — фильтрация результатов по указанному индексу. Мы уже обнаружили индексы с наибольшим числом сканирований, теперь мы можем выяснить, какие планы их порождают. Следуя схеме, имя индекса является атрибутом элемента Object внутри элемента IndexScan, который находится внутри элемента RelOp.
Поэтому запрос будет таким:
Если запрос выдает слишком много планов, мы можем использовать другие поля в sys.dm_exec_query_Stats, чтобы найти планы, требующие оптимизации. Например, мы можем использовать поле total_worker_time, чтобы упорядочить результаты по времени CPU, например:
В моей ситуации результатом является только один план запроса. Мы имеем текст соответствующего запроса и можем посмотреть графический план в SSMS. SSMS моказывает даже информацию о «недостающих индексах», позволяя легко решить проблему, создав их.

Мы нашли тот самый запрос, который порождает проблему и.

. мы можем увидеть графический план и предположение об отсутствующем индексе.
Идентификация проблем поиска закладок
Другим примером использования DMV является поиск планов с поиском закладок в индексе. Если изменить первый запрос на вычисление количества закладок, мы обнаружим множество закладок в adventureworks2012:
Попробуем найти индекс, который их порождает, для дальнейшего исследования:
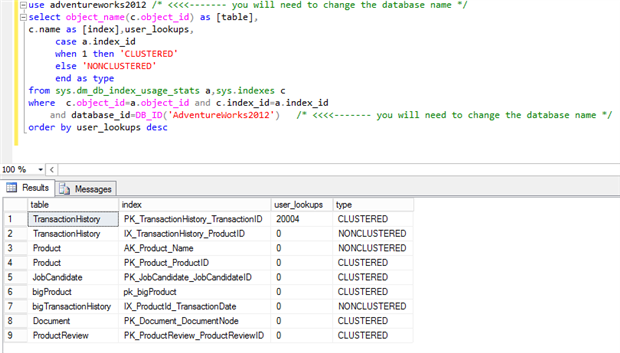 Adventureworks2012 также имеет проблемы с закладками
Adventureworks2012 также имеет проблемы с закладками
Наконец, чтобы найти планы запросов с закладками, нам нужно выполнить фильтрацию по атрибуту lookup в элементе IndexScan. Новый запрос:
В этом примере мы обнаружим, что если удалить два поля — quantity и actualcost из запроса, то lookup пропадет. Конечно, это невозможно, и в данном случае нам пришлось бы искать другое решение, но это тема не данной статьи.
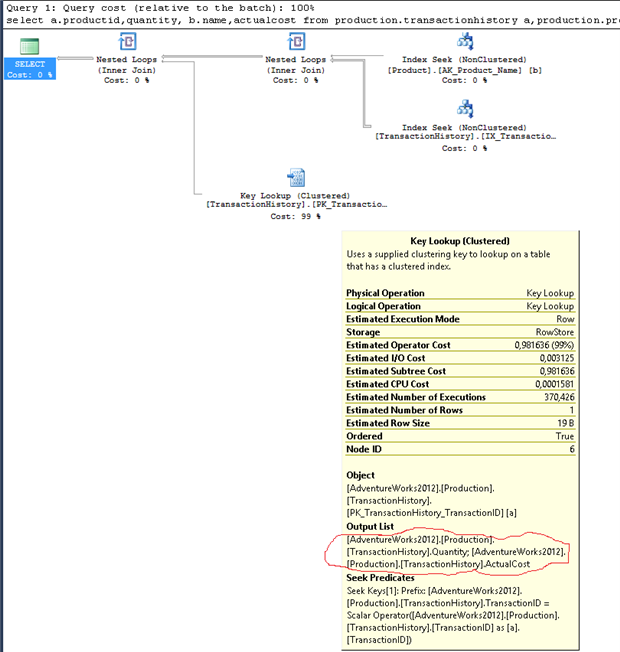
Мы видим причину закладки
Настройка исследовательских запросов на практические цели
Замечательно, что мы можем находить планы запросов в кэше для поиска проблем, однако непрактично использовать подобные запросы в процессе ежедневной оптимизации. Как сделать это более практичным? Просто: мы создаем функцию, и нам больше не нужно беспокоиться о сложном синтаксисе запросов. Итак, мы можем создать запросы для каждой из главных проблем в плане запросов, а затем создать одну функцию для каждого запроса.
Метод XQuery exists() принимает только константы в качестве параметров. Поэтому для доступа к переменной внутри выражения xquery мы можем только лишь преобразовав имя индекса в переменную при помощи выражения sql:variable.
Ниже приведена полученная таким образом функция:
Обратите внимание, что я включил функцию fn:lower-case, в противном случае функция стала бы чувствительна к регистру, как и XML.
Теперь для поиска планов в кэше, которые используют сканирование конкретного индекса, достаточно написать простой запрос:
Аналогично для проблем с закладками:
И последний штрих: поскольку мы создаем повторно исполняемые функции, будет полезно выводить больше полей из sys.dm_exec_query_stats, чтобы функции стали более гибкими.
Вот окончательный вид функций:
Заключение
Обратные ссылки
Нет обратных ссылок
Комментарии
Показывать комментарии Как список | Древовидной структурой
Автор не разрешил комментировать эту запись
Источник







