- Паскаль — Урок 18: Символьный тип данных CHAR
- Как вывести номер char
- Комментарии
- 4.11 – Символы
- Инициализация переменных char
- Печать переменных типа char
- Печать переменных char как целых чисел через приведение типов
- Ввод символов
- Размер, диапазон и символ по умолчанию у переменных char
- Экранированные последовательности
- Новая строка ( \n ) против std::endl
- В чем разница между заключением символов в одинарные и двойные кавычки?
- А как насчет других типов символов, wchar_t , char16_t и char32_t ?
Паскаль — Урок 18: Символьный тип данных CHAR

Итак, продолжаем наши уроки Паскаль для начинающих. В прошлом уроке мы разобрали строковый тип данных, но там мы упомянули про символы, поэтому прежде чем глубоко изучать тип данных String, мы узнаем о типе Char. Символьный тип данных Char — тип данных, значениями которого являются одиночные символы. Данный тип может содержать всего один любой символ (Например: «*», «/», «.», «!» и другие). Каждый такой символ занимает 8 бит памяти, всего существует 256 восьмибитовых символов. Все символы, используемые символьным типом Char записаны в таблице символов ASCII (American Standart Code for Information Interchange) или Американский стандарт кода для обмена информацией.
Символьные константы заключаются в апострофы, например ‘.’, ‘*’, ‘7’, ‘s’. Также символьную константу можно записать с помощью символа — «решетки», например #185 — выведет символ под номером 185 из таблицы ASCII (это символ ‘№’).
К символьному типу применимы 5 функций: Ord, Chr, Pred, Succ и Upcase.
Функция Ord преобразовывает символ в её числовой код из таблицы ASCII. Например для символа ‘№’ она возвратит значение 185. Функция Chr обратна функции Ord. Функция Chr преобразует числовой код символа в сам символ, например, если взять числовой код 64, то функция Chr (64) возвратит символ ‘@’.
Пример программы на Паскаль с использованием функции Ord:
Пример программы на Паскаль с использованием функции Chr:
Функция Pred возвращает значение предыдущего символа из таблицы ASCII, например для символа ‘P’ (Pred (P)) эта функция возвратит символ ‘O’. Функция Succ обратная функции Pred. Для символа ‘P’ функция Succ (P) возвратит символ ‘Q’, то есть следующий символ из вышеописанной таблицы ASCII.
Пример программы на Паскаль с использованием функций Pred и Succ:
Функция UpCase применима только для строчных букв английского алфавита. Данная функция преобразует строчные английские буквы в заглавные.
Пример программы на Паскаль с использованием функции UpCase:
P.S. В данном уроке описаны исключительно функции, применимые к символьному типу, про отличие функций от процедур можно узнать в Уроке №7 — Подпрограммы.
Приложение к уроку — таблицы символов ASCII:
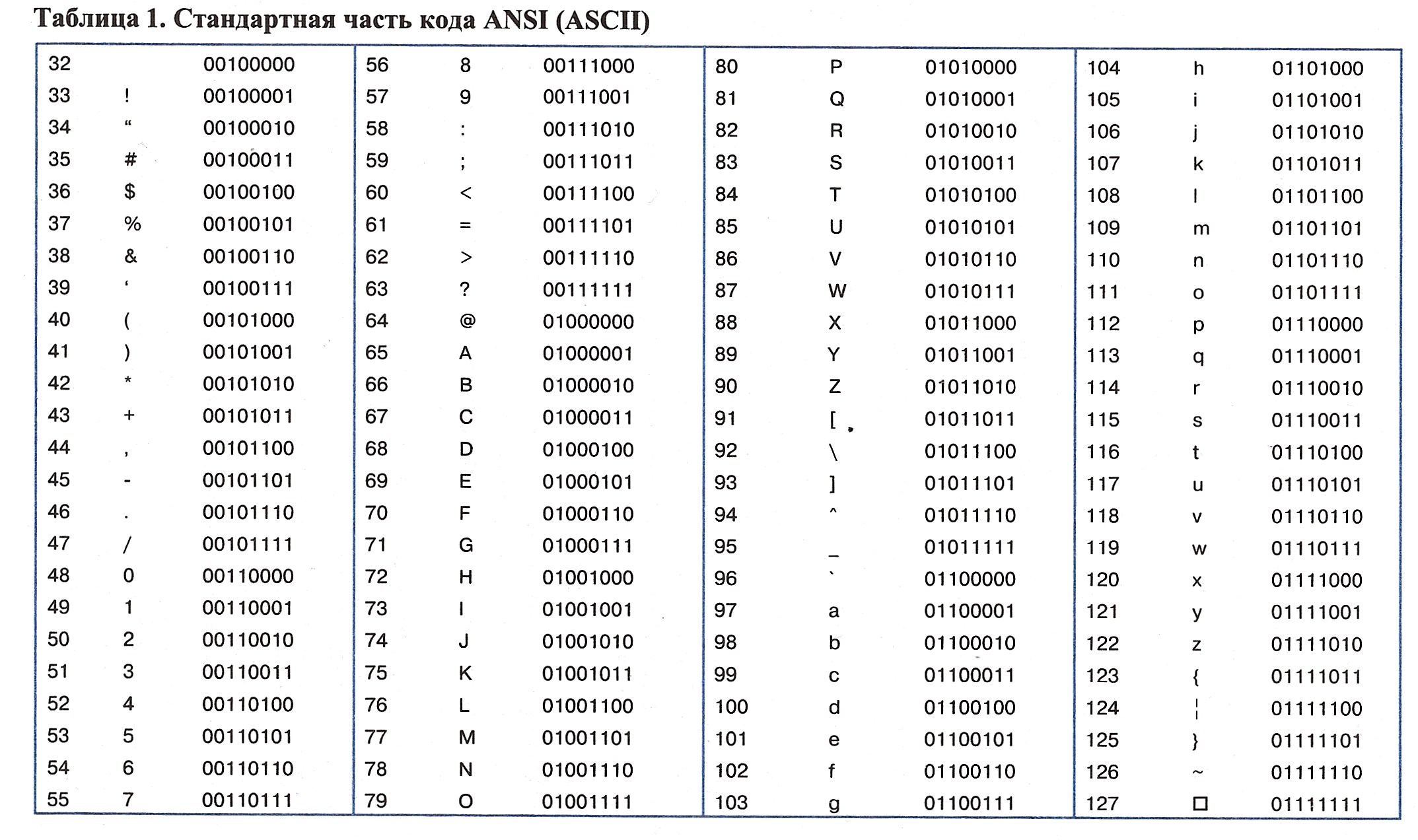
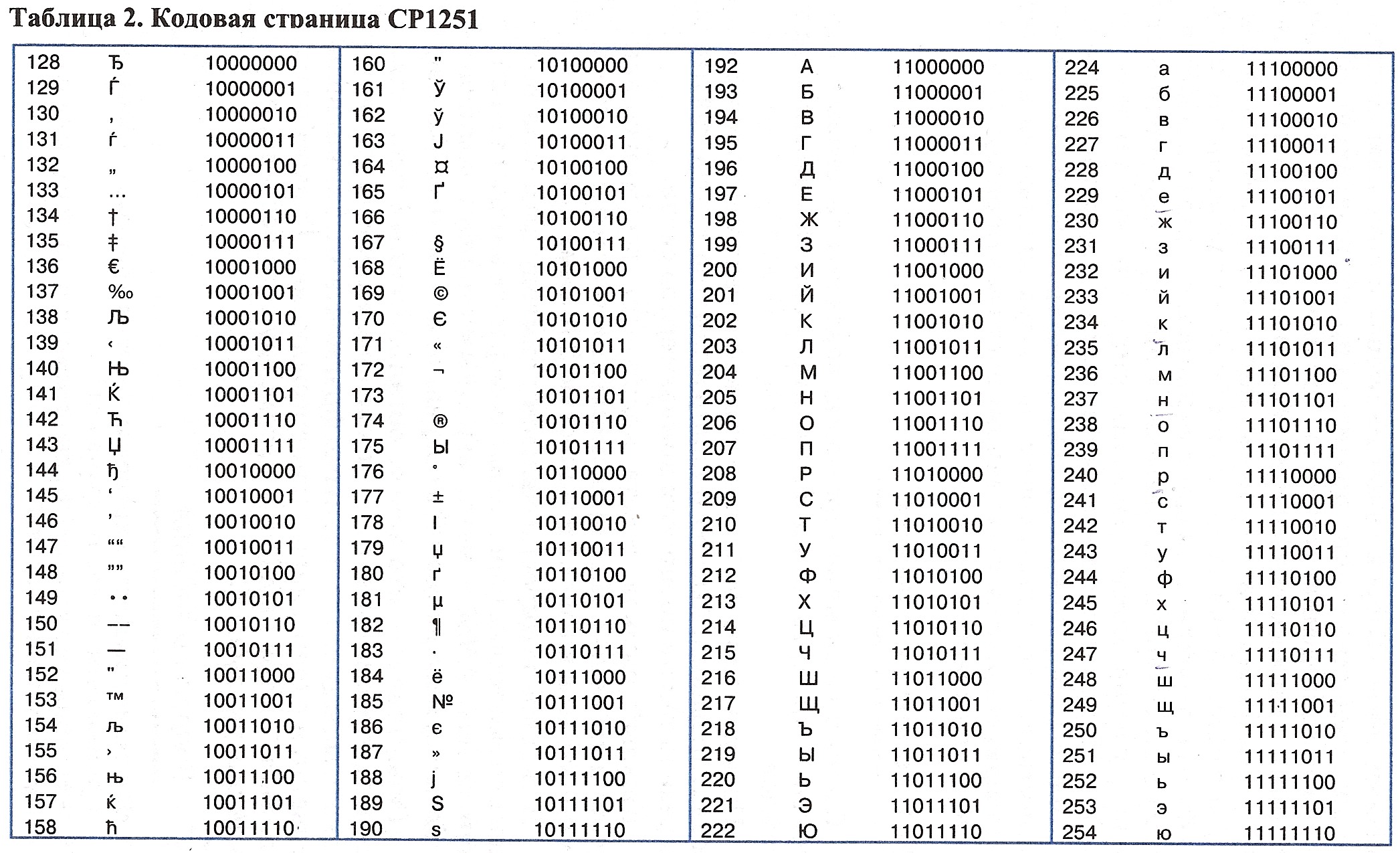
На сегодня урок окончен. Помните, что программирование на паскале просто и является основой для многих языков программирования.
Источник
Как вывести номер char
Как получить ASCII код символа на C++.
Простейшая функция, заберет символ CHAR и вернет в INT его ASCII символ. Это открытие я сделал на 1 курсе универа, когда учился программировать.
Далее полноценный пример дла Borland C++
#pragma hdrstop
#include
#include
#pragma argsused
ascii_cod(char x);
int main(int argc, char* argv[])
<
char c;
cout >c;
int b = ascii_cod(c);
cout Автор: admin | 17.03.2008 | Камменты: 13
Комментарии
| Комментарий от Barmaley [ 4 мая, 2008, 17:10 ] | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Комментарий от kas [ 4 мая, 2008, 17:27 ] | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Комментарий от Масрур [ 24 февраля, 2009, 18:56 ] | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Комментарий от Aivos [ 23 мая, 2009, 00:45 ] | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Комментарий от Areal [ 7 марта, 2011, 17:20 ] | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Комментарий от DjSirko [ 9 апреля, 2011, 19:14 ] | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Комментарий от MrSuperVisor [ 13 июня, 2011, 13:07 ] | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Code | Symbol | Code | Symbol | Code | Symbol | Code | Symbol |
|---|---|---|---|---|---|---|---|
| 0 | NUL (null) | 32 | (space) | 64 | @ | 96 | ` |
| 1 | SOH (start of header, начало «заголовка») | 33 | ! | 65 | A | 97 | a |
| 2 | STX (start of text, начало «текста») | 34 | ” | 66 | B | 98 | b |
| 3 | ETX (end of text, конец «текста») | 35 | # | 67 | C | 99 | c |
| 4 | EOT (end of transmission, конец передачи) | 36 | $ | 68 | D | 100 | d |
| 5 | ENQ (enquiry, «Прошу подтверждения!») | 37 | % | 69 | E | 101 | e |
| 6 | ACK (acknowledge, «Подтверждаю!») | 38 | & | 70 | F | 102 | f |
| 7 | BEL (bell, звуковой сигнал: звонок) | 39 | ’ | 71 | G | 103 | g |
| 8 | BS (backspace, возврат на один символ) | 40 | ( | 72 | H | 104 | h |
| 9 | HT (horizontal tab, горизонтальная табуляция) | 41 | ) | 73 | I | 105 | i |
| 10 | LF (line feed/new line, перевод строки) | 42 | * | 74 | J | 106 | j |
| 11 | VT (vertical tab, вертикальная табуляция) | 43 | + | 75 | K | 107 | k |
| 12 | FF (form feed / new page, «прогон страницы», новая страница) | 44 | , | 76 | L | 108 | l |
| 13 | CR (carriage return, возврат каретки) | 45 | — | 77 | M | 109 | m |
| 14 | SO (shift out, «Переключиться на другую ленту (кодировку)») | 46 | . | 78 | N | 110 | n |
| 15 | SI (shift in, «Переключиться на исходную ленту (кодировку)») | 47 | / | 79 | O | 111 | o |
| 16 | DLE (data link escape, «Экранирование канала данных») | 48 | 0 | 80 | P | 112 | p |
| 17 | DC1 (data control 1, первый символ управления устройством) | 49 | 1 | 81 | Q | 113 | q |
| 18 | DC2 (data control 2, второй символ управления устройством) | 50 | 2 | 82 | R | 114 | r |
| 19 | DC3 (data control 3, третий символ управления устройством) | 51 | 3 | 83 | S | 115 | s |
| 20 | DC4 (data control 4, четвертый символ управления устройством) | 52 | 4 | 84 | T | 116 | t |
| 21 | NAK (negative acknowledge, «Не подтверждаю!») | 53 | 5 | 85 | U | 117 | u |
| 22 | SYN (synchronous idle) | 54 | 6 | 86 | V | 118 | v |
| 23 | ETB (end of transmission block, конец текстового блока) | 55 | 7 | 87 | W | 119 | w |
| 24 | CAN (cancel, «Отмена») | 56 | 8 | 88 | X | 120 | x |
| 25 | EM (end of medium, «Конец носителя») | 57 | 9 | 89 | Y | 121 | y |
| 26 | SUB (substitute, «Подставить») | 58 | : | 90 | Z | 122 | z |
| 27 | ESC (escape) | 59 | ; | 91 | [ | 123 | < |
| 28 | FS (file separator, разделитель файлов) | 60 | 94 | ^ | 126 | ||
| 31 | US (unit separator, разделитель юнитов) | 63 | ? | 95 | _ | 127 | DEL (delete, стереть последний символ) |
Коды 0–31 называются непечатаемыми символами и в основном используются для форматирования и управления принтерами. Большинство из них сейчас устарели.
Коды 32–127 называются печатными символами и представляют собой буквы, цифры и знаки препинания, которые большинство компьютеров используют для отображения основного английского текста.
Инициализация переменных char
Вы можете инициализировать переменные типа char , используя символьные литералы:
Вы также можете инициализировать переменные типа char целыми числами, но этого, если возможно, следует избегать.
Предупреждение
Будьте осторожны, чтобы не перепутать символы чисел с целыми числами. Следующие две инициализации не эквивалентны:
Символы чисел предназначены для использования, когда мы хотим представить числа в виде текста, а не в виде чисел и применения к ним математических операций.
Печать переменных типа char
При использовании std::cout для печати переменной типа char , std::cout выводит переменную char как символ ASCII:
Данная программа дает следующий результат:
Мы также можем напрямую выводить символьные литералы:
В результате это дает:
Напоминание
В C++ целочисленный тип фиксированной ширины int8_t обычно обрабатывается так же, как signed char , поэтому он обычно печатается как символ ( char ) вместо целого числа.
Печать переменных char как целых чисел через приведение типов
Если мы хотим вывести char как число вместо символа, мы должны указать std::cout , чтобы он печатал переменную char , как если бы она была целочисленного типа. Один (плохой) способ сделать это – присвоить значение переменной char другой переменной целочисленного типа и напечатать эту переменную:
Однако это довольно коряво. Лучше использовать приведение типа. Приведение типа создает значение одного типа из значения другого типа. Для преобразования между базовыми типами данных (например, из char в int или наоборот) мы используем приведение типа, называемое статическим приведением.
Синтаксис статического приведения выглядит немного забавным:
static_cast принимает значение из выражения в качестве входных данных и преобразует его в любой базовый тип, который представляет новый_тип (например, int , bool , char , double ).
Ключевые выводы
Всякий раз, когда вы видите синтаксис C++ (за исключением препроцессора), в котором используются угловые скобки, то, что между угловыми скобками, скорее всего, будет типом. Обычно C++ работает с концепциями, которым нужен параметризуемый тип.
Ниже показан пример использования статического приведения для создания целочисленного значения из нашего значения char :
Эта программа дает следующий вывод:
Важно отметить, что параметр static_cast вычисляется как выражение. Когда мы передаем переменную, эта переменная вычисляется для получения ее значения, которое затем преобразуется в новый тип. На переменную не влияет приведение ее значения к новому типу. В приведенном выше случае переменная ch по-прежнему является char и сохраняет то же значение.
Также обратите внимание, что статическое приведение не выполняет никакой проверки диапазона значений, поэтому, если вы приведете большое целое число в char , вы вызовете переполнение своей переменной char .
О статическом приведении типов и других типах приведения мы поговорим подробнее в следующем уроке (8.5 – Явное преобразование типов (приведение) и static_cast ).
Ввод символов
Следующая программа просит пользователя ввести символ, а затем печатает его как символ и его код ASCII:
Ниже показан результат одного запуска:
Обратите внимание, что std::cin позволяет вводить несколько символов. Однако переменная ch может содержать только 1 символ. Следовательно, в переменную ch извлекается только первый входной символ. Остальная часть пользовательского ввода остается во входном буфере, который использует std::cin , и может быть извлечена с помощью последующих вызовов std::cin .
Вы можете увидеть это поведение в следующем примере:
Размер, диапазон и символ по умолчанию у переменных char
char определяется C++ всегда размером 1 байт. По умолчанию char может быть со знаком или без знака (хотя обычно он со знаком). Если вы используете переменные char для хранения символов ASCII, вам не нужно указывать знак (поскольку переменные char со знаком и без знака могут содержать значения от 0 до 127).
Если вы используете char для хранения небольших целых чисел (чего не следует делать, если вы явно не оптимизируете используемую память), вы всегда должны указывать, со знаком переменная или нет. signed char (со знаком) может содержать число от -128 до 127. unsigned char (без знака) может содержать число от 0 до 255.
Экранированные последовательности
В C++ есть некоторые символы, которые имеют особое значение. Эти символы называются экранированными последовательностями (управляющими последовательностями, escape-последовательностями). Экранированная последовательность начинается с символа ‘\’ (обратный слеш), за которым следует буква или цифра.
Вы уже видели наиболее распространенную экранированную последовательность: ‘ \n ‘, которую можно использовать для вставки символа новой строки в текстовую строку:
Эта программа выдает:
Еще одна часто используемая экранированная последовательность – ‘ \t ‘, которая включает горизонтальную табуляцию:
Три других примечательных экранированных последовательности:
- \’ – печатает одинарную кавычку;
- \» – печатает двойную кавычку;
- \\ – печатает обратный слеш.
Ниже приведена таблица всех экранированных последовательностей:
| Название | Символ | Назначение |
|---|---|---|
| Предупреждение | \a | Выдает предупреждение, например звуковой сигнал |
| Backspace | \b | Перемещает курсор на одну позицию назад |
| Перевод страницы | \f | Перемещает курсор на следующую логическую страницу |
| Новая строка | \n | Перемещает курсор на следующую строку |
| Возврат каретки | \r | Перемещает курсор в начало строки |
| Горизонтальная табуляция | \t | Печать горизонтальной табуляции |
| Вертикальная табуляция | \v | Печатает вертикальную табуляцию |
| Одинарная кавычка | \’ | Печать одинарной кавычки |
| Двойная кавычка | \» | Печать двойной кавычки |
| Обратная косая черта | \\ | Печатает обратный слеш |
| Вопросительный знак | \? | Печатает вопросительный знак Больше не актуально. Вы можете использовать вопросительные знаки без экранирования. |
| Восьмеричное число | \(число) | Преобразуется в символ, представленный восьмеричным числом |
| Шестнадцатеричное число | \x(число) | Преобразуется в символ, представленный шестнадцатеричным числом |
Вот несколько примеров:
Эта программа напечатает:
Новая строка ( \n ) против std::endl
В чем разница между заключением символов в одинарные и двойные кавычки?
Отдельные символы всегда заключаются в одинарные кавычки (например, ‘a’, ‘+’, ‘5’). char может представлять только один символ (например, букву а, знак плюса, цифру 5). Что-то вроде этого некорректно:
Текст, заключенный в двойные кавычки (например, «Hello, world!»), называется строкой. Строка – это набор последовательных символов (и, таким образом, строка может содержать несколько символов).
Пока вы можете использовать строковые литералы в своем коде:
Мы обсудим строки в следующем уроке (4.12 – Знакомство с std::string ).
Правило
Всегда помещайте отдельные символы в одинарные кавычки (например, ‘ t ‘ или ‘ \n ‘, а не » t » или » \n «). Это помогает компилятору более эффективно выполнять оптимизацию.
А как насчет других типов символов, wchar_t , char16_t и char32_t ?
wchar_t следует избегать почти во всех случаях (за исключением взаимодействия с Windows API). Его размер определяется реализацией и не является надежным. Он не рекомендуется для использования.
В качестве отступления.
Англоязычный термин «deprecated» (не рекомендуется) означает «всё еще поддерживается, но больше не рекомендуется для использования, потому что он был заменен чем-то лучшим или больше не считается безопасным».
Подобно тому, как ASCII сопоставляет целые числа 0–127 с символами английского алфавита, существуют и другие стандарты кодировки символов для сопоставления целых чисел (разного размера) с символами других языков. Наиболее известной кодировкой за пределами диапазона ASCII является стандарт Unicode (Юникод), который сопоставляет более 110 000 целых чисел с символами на многих языках. Поскольку Unicode содержит очень много кодовых обозначений, то для одного кодового обозначения, чтобы представить один символ, Unicode требуется 32 бита (кодировка UTF-32). Однако символы Unicode также могут быть закодированы с использованием 16-ти или 8-ми битов (кодировки UTF-16 и UTF-8 соответственно).
char16_t и char32_t были добавлены в C++11 для обеспечения явной поддержки 16-битных и 32-битных символов Unicode. char8_t был добавлен в C++20.
Если вы не планируете сделать свою программу совместимой с Unicode, вам не нужно использовать char8_t , char16_t или char32_t . Юникод и локализация в основном выходят за рамки этих руководств, поэтому мы не будем рассматривать их дальше.
А пока при работе с символами (и строками) вы должны использовать только символы ASCII. Использование символов из других наборов символов может привести к неправильному отображению ваших символов.
Источник







