- Множества: Set, HashSet, LinkedHashSet, TreeSet
- HashSet
- Методы
- Преобразовать в массив и вывести в ListView
- LinkedHashSet
- TreeSet
- SortedSet
- Набор данных интерфейса Set
- Набор данных HashSet
- Конструкторы HashSet :
- Методы HashSet
- Набор данных LinkedHashSet
- Набор данных TreeSet
- Конструкторы TreeSet :
- Методы TreeSet
- Руководство по HashSet в Java
- 1. Обзор
- 2. Введение в HashSet
- 3. API
- 3.1. добавить()
- 3.2. содержит()
- 3.3. удалить()
- 3.4. очистить()
- 3.5. размер()
- 3.6. isEmpty()
- 3.7. итератор()
- 4. Как HashSet Поддерживает Уникальность?
- 5. Производительность HashSet
- 6. Заключение
Множества: Set, HashSet, LinkedHashSet, TreeSet
HashSet, TreeSet и LinkedHashSet относятся к семейству Set. В множествах Set каждый элемент хранится только в одном экземпляре, а разные реализации Set используют разный порядок хранения элементов. В HashSet порядок элементов определяется по сложному алгоритму. Если порядок хранения для вас важен, используйте контейнер TreeSet, в котором объекты хранятся отсортированными по возрастанию в порядке сравнения или LinkedHashSet с хранением элементов в порядке добавления.
Множества часто используются для проверки принадлежности, чтобы вы могли легко проверить, принадлежит ли объект заданному множеству, поэтому на практике обычно выбирается реализация HashSet, оптимизированная для быстрого поиска.
В Android 11 (R) обещают добавить несколько перегруженных версий метода of(), которые являются частью Java 8.
HashSet
Название Hash. происходит от понятия хэш-функция. Хэш-функция — это функция, сужающая множество значений объекта до некоторого подмножества целых чисел. Класс Object имеет метод hashCode(), который используется классом HashSet для эффективного размещения объектов, заносимых в коллекцию. В классах объектов, заносимых в HashSet, этот метод должен быть переопределен (override).
Имеет два основных конструктора (аналогично ArrayList):
Методы
- public Iterator iterator()
- public int size()
- public boolean isEmpty()
- public boolean contains(Object o)
- public boolean add(Object o)
- public boolean addAll(Collection c)
- public Object[] toArray()
- public boolean remove(Object o)
- public boolean removeAll(Collection c)
- public boolean retainAll(Collection c) — (retain — сохранить). Выполняет операцию «пересечение множеств».
- public void clear()
- public Object clone()
Методы аналогичны методам ArrayList за исключением того, что метод add(Object o) добавляет объект в множество только в том случае, если его там нет. Возвращаемое методом значение — true, если объект добавлен, и false, если нет.
Перейдём к практике. Как это ни странно, но в жизни встречаются несколько Барсиков, Мурзиков и прочих Рыжиков. Несмотря на одинаковые имена, каждый кот неповторим. Надеюсь, с этим никто не спорит. Но пихать имена котов в множество HashSet не стоит, так как в множестве может храниться только одно имя и двух Мурзиков тут не записать. Другое дело — страны. Не может быть двух Франций, двух Англий, двух Россий (даже партия такая есть Единая Россия, впрочем мы отвлеклись).
Итак, создадим множество стран.
Нажав на кнопку, вы получите результат Размер HashSet = 4.
Даже если вы попытаетесь схитрить и дополнительно вставить строку countryHashSet.add(«Кот-Д’Ивуар»); после России, то всё-равно размер останется прежним.
Убедиться в этом можно, если вызвать метод iterator(), который позволяет получить всё множество элементов:
Несмотря на наше упрямство, мы видим только четыре добавленных элемента.
Стоит отметить, что порядок добавления стран во множество будет непредсказуемым. HashSet использует хэширование для ускорения выборки. Если вам нужно, чтобы результат был отсортирован, то пользуйтесь TreeSet.
Преобразовать в массив и вывести в ListView
Следующий пример — задел на будущее. Когда вы узнаете, что такое ListView, то вернитесь к этому уроку и узнайте, как сконвертировать множество в массив и вывести результат в компонент ListView (Список):
Продолжим опыты. Поработаем теперь с числами.
Здесь мы ещё раз убеждаемся, что повторное добавление числа не происходит. В цикле случайным образом выбирается число от 0 до 9 тысячу раз. Естественно, многие числа должны были повториться при таком сценарии, но во множество каждое число попадёт один раз.
При этом данные не сортируются, так как расположены как попало.
Специально для Android был разработан новый класс ArraySet, который более эффективен.
LinkedHashSet
Класс LinkedHashSet расширяет класс HashSet, не добавляя никаких новых методов. Класс поддерживает связный список элементов набора в том порядке, в котором они вставлялись. Это позволяет организовать упорядоченную итерацию вставки в набор.
TreeSet
Переделанный пример для вывода случайных чисел в отсортированном порядке. HashSet не может гарантировать, что данные будут отсортированы, так как работает по другому алгоритму. Если сортировка для вас важна, то используйте TreeSet.
Со строками это выглядит нагляднее:
Названия стран выведутся в алфавитном порядке.
Класс TreeSet создаёт коллекцию, которая для хранения элементов применяет дерево. Объекты сохраняются в отсортированном порядке по возрастанию.
SortedSet
В примере с TreeSet использовался интерфейс SortedSet, который позволяет сортировать элементы множества. По умолчанию сортировка производится привычным способом, но можно изменить это поведение через интерфейс Comparable.
Кроме стандартных методов Set у интерфейса есть свои методы.
- Comparator comparator()
- subSet(Object fromElement, Object toElement)
- tailSet(Object fromElement)
- headSet(Object toElement)
- Object first()
- Object last()
Источник
Набор данных интерфейса Set
Реализация интерфейса Set представляет собой неупорядоченную коллекцию, которая не может содержать дублирующие данные.
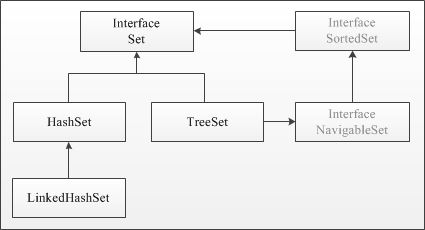
Интерфейс Set включает следующие методы :
| Метод | Описание |
|---|---|
| add(Object o) | Добавление элемента в коллекцию, если он отсутствует. Возвращает true, если элемент добавлен. |
| addAll(Collection c) | Добавление элементов коллекции, если они отсутствуют. |
| clear() | Очистка коллекции. |
| contains(Object o) | Проверка присутствия элемента в наборе. Возвращает true, если элемент найден. |
| containsAll(Collection c) | Проверка присутсвия коллекции в наборе. Возвращает true, если все элементы содержатся в наборе. |
| equals(Object o) | Проверка на равенство. |
| hashCode() | Получение hashCode набора. |
| isEmpty() | Проверка наличия элементов. Возвращает true если в коллекции нет ни одного элемента. |
| iterator() | Функция получения итератора коллекции. |
| remove(Object o) | Удаление элемента из набора. |
| removeAll(Collection c) | Удаление из набора всех элементов переданной коллекции. |
| retainAll(Collection c) | Удаление элементов, не принадлежащих переданной коллекции. |
| size() | Количество элементов коллекции |
| toArray() | Преобразование набора в массив элементов. |
| toArray(T[] a) | Преобразование набора в массив элементов. В отличии от предыдущего метода, который возвращает массив объектов типа Object, данный метод возвращает массив объектов типа, переданного в параметре. |
К семейству интерфейса Set относятся HashSet, TreeSet и LinkedHashSet. В множествах Set разные реализации используют разный порядок хранения элементов. В HashSet порядок элементов оптимизирован для быстрого поиска. В контейнере TreeSet объекты хранятся отсортированными по возрастанию. LinkedHashSet хранит элементы в порядке добавления.
Набор данных HashSet
Конструкторы HashSet :
Методы HashSet
- public int size()
- public boolean isEmpty()
- public boolean add(Object o)
- public boolean addAll(Collection c)
- public boolean remove(Object o)
- public boolean removeAll(Collection c)
- public boolean contains(Object o)
- public void clear()
- public Object clone()
- public Iterator iterator()
- public Object[] toArray()
- public boolean retainAll(Collection c)
HashSet содержит методы аналогично ArrayList. Исключением является метод add(Object o), который добавляет объект только в том случае, если он отсутствует. Если объект добавлен, то метод add возвращает значение — true, в противном случае false.
Пример использования HashSet :
В консоли мы должны увидеть только 4 записи. Следует отметить, что порядок добавления записей в набор будет непредсказуемым. HashSet использует хэширование для ускорения выборки.
Пример использования HashSet с целочисленными значениями. В набор добавляем значения от 0 до 9 из 25 возможных случайным образом выбранных значений — дублирование не будет.
Следует отметить, что реализация HashSet не синхронизируется. Если многократные потоки получают доступ к набору хеша одновременно, а один или несколько потоков должны изменять набор, то он должен быть синхронизирован внешне. Это лучше всего выполнить во время создания, чтобы предотвратить случайный несинхронизируемый доступ к набору :
Набор данных LinkedHashSet
Класс LinkedHashSet наследует HashSet, не добавляя никаких новых методов, и поддерживает связный список элементов набора в том порядке, в котором они вставлялись. Это позволяет организовать упорядоченную итерацию вставки в набор.
Также, как и HashSet, LinkedHashSet не синхронизируется. Поэтому при использовании данной реализации в приложении с множеством потоков, часть из которых может вносить изменения в набор, следует на этапе создания выполнить синхронизацию :
Набор данных TreeSet
Класс TreeSet создаёт коллекцию, которая для хранения элементов использует дерево. Объекты хранятся в отсортированном порядке по возрастанию.
Конструкторы TreeSet :
Методы TreeSet
- boolean add(Object o)
- boolean addAll(Collection c)
- Object ceiling(Object o)
- void clear()
- TreeSet clone()
- Comparator comparator()
- boolean contains(Object o)
- Iterator descendingIterator()
- NavigableSet descendingSet()
- Object first()
- Object floor(Object o)
- SortedSet headSet(E e)
- NavigableSet headSet(E e, boolean inclusive)
- Object higher(Object o)
- boolean isEmpty()
- Iterator iterator()
- E last()
- E lower(E e)
- E pollFirst()
- E pollLast()
- boolean remove(Object o)
- int size()
- Spliterator spliterator()
- NavigableSet subSet(E fromElement, boolean fromInclusive, E toElement, boolean toInclusive)
- SortedSet subSet(E fromElement, E toElement)
- SortedSet tailSet(E fromElement)
- NavigableSet tailSet(E fromElement, boolean inclusive)
В следующем измененном примере с использования TreeSet в консоль будут выведены значения в упорядоченном виде.
Источник
Руководство по HashSet в Java
Краткое, но всестороннее введение в HashSet на Java.
Автор: baeldung
Дата записи
1. Обзор
В этой статье мы погрузимся в HashSet. Это одна из самых популярных реализаций Set , а также неотъемлемая часть фреймворка Java Collections.
2. Введение в HashSet
HashSet – это одна из фундаментальных структур данных в Java Collections API .
Давайте вспомним наиболее важные аспекты этой реализации:
- Он хранит уникальные элементы и допускает нули
- Он поддерживается хэш-картой
- Он не поддерживает порядок вставки
- Это не потокобезопасно
Обратите внимание, что этот внутренний HashMap инициализируется при создании экземпляра HashSet :
Если вы хотите углубиться в то, как работает HashMap , вы можете прочитать статью, посвященную ему здесь .
3. API
В этом разделе мы рассмотрим наиболее часто используемые методы и рассмотрим несколько простых примеров.
3.1. добавить()
Метод add() можно использовать для добавления элементов в набор. Контракт метода гласит, что элемент будет добавлен только тогда, когда он еще не присутствует в наборе. Если элемент был добавлен, метод возвращает true, в противном случае – false.
Мы можем добавить элемент в HashSet like:
С точки зрения реализации метод add является чрезвычайно важным. Детали реализации иллюстрируют, как HashSet работает внутренне и использует метод Hashmap /put :
Переменная map является ссылкой на внутреннюю, резервную HashMap:
Было бы неплохо сначала ознакомиться с хэш-кодом, чтобы получить детальное представление о том, как элементы организованы в структурах данных на основе хэша.
- A HashMap – это массив buckets с емкостью по умолчанию 16 элементов-каждый bucket соответствует другому значению hashcode
- Если различные объекты имеют одинаковое значение хэш-кода, они хранятся в одном ведре
- При достижении коэффициента загрузки создается новый массив в два раза больше предыдущего, а все элементы перефразируются и перераспределяются между новыми соответствующими ведрами Чтобы получить значение, мы хэшируем ключ, модифицируем его, а затем переходим к соответствующему ведру и ищем в потенциальном связанном списке, если существует более одного объекта
3.2. содержит()
Цель метода contains состоит в том, чтобы проверить, присутствует ли элемент в данном HashSet . Он возвращает true если элемент найден, в противном случае false.
Мы можем проверить наличие элемента в HashSet :
Всякий раз, когда объект передается этому методу, вычисляется хэш-значение. Затем соответствующее местоположение ведра решается и пересекается.
3.3. удалить()
Метод удаляет указанный элемент из набора, если он присутствует. Этот метод возвращает true , если набор содержит указанный элемент.
Давайте рассмотрим рабочий пример:
3.4. очистить()
Мы используем этот метод, когда собираемся удалить все элементы из набора. Базовая реализация просто очищает все элементы из базовой HashMap.
Давайте посмотрим на это в действии:
3.5. размер()
Это один из фундаментальных методов в API. Он широко используется, поскольку помогает определить количество элементов, присутствующих в HashSet . Базовая реализация просто делегирует вычисление методу Hashmap size () .
Давайте посмотрим на это в действии:
3.6. isEmpty()
Мы можем использовать этот метод, чтобы выяснить, является ли данный экземпляр HashSet пустым или нет. Этот метод возвращает true , если набор не содержит элементов:
3.7. итератор()
Метод возвращает итератор по элементам в Set . Элементы посещаются в произвольном порядке, а итераторы быстро отказывают .
Здесь мы можем наблюдать случайный порядок итераций:
Если набор изменяется в любое время после создания итератора любым способом, кроме как с помощью собственного метода удаления итератора, то Итератор бросает а ConcurrentModificationException .
Давайте посмотрим на это в действии:
В качестве альтернативы, если бы мы использовали метод remove итератора, то не столкнулись бы с этим исключением:
Отказоустойчивое поведение итератора не может быть гарантировано, поскольку невозможно сделать какие-либо жесткие гарантии при наличии несинхронизированной параллельной модификации.
Отказоустойчивые итераторы бросают ConcurrentModificationException на основе наилучших усилий. Поэтому было бы неправильно писать программу, которая зависела бы от этого исключения в своей корректности.
4. Как HashSet Поддерживает Уникальность?
Когда мы помещаем объект в HashSet , он использует значение объекта hashcode , чтобы определить, нет ли элемента в наборе уже.
Каждое значение хэш-кода соответствует определенному местоположению корзины, которое может содержать различные элементы, для которых вычисленное хэш-значение одинаково. Но два объекта с одинаковым хэш-кодом могут быть не равны .
Таким образом, объекты в одном и том же ведре будут сравниваться с помощью метода equals () .
5. Производительность HashSet
На производительность HashSet влияют в основном два параметра – его Начальная емкость и Коэффициент загрузки .
Ожидаемая временная сложность добавления элемента в набор составляет O(1) , которая может упасть до O(n) в худшем случае (присутствует только одно ведро) – поэтому важно поддерживать правильную емкость хэш-набора.
Коэффициент загрузки описывает, каков максимальный уровень заполнения, выше которого необходимо будет изменить размер набора.
Мы также можем создать HashSet с пользовательскими значениями для начальной емкости и коэффициента загрузки :
В первом случае используются значения по умолчанию – начальная емкость 16 и коэффициент загрузки 0,75. Во втором случае мы переопределяем емкость по умолчанию, а в третьем – оба.
Низкая начальная емкость уменьшает сложность пространства, но увеличивает частоту повторной обработки, что является дорогостоящим процессом.
С другой стороны, высокая начальная емкость увеличивает стоимость итерации и начальное потребление памяти.
Как правило большого пальца:
- Высокая начальная емкость хороша для большого количества записей в сочетании с небольшим количеством итераций
- Низкая начальная емкость хороша для нескольких записей с большим количеством итераций
Поэтому очень важно найти правильный баланс между ними. Обычно реализация по умолчанию оптимизирована и работает просто отлично, если мы чувствуем необходимость настроить эти параметры в соответствии с требованиями, мы должны сделать это разумно.
6. Заключение
В этой статье мы описали полезность HashSet , его назначение , а также лежащую в его основе работу. Мы увидели, насколько он эффективен с точки зрения удобства использования, учитывая его постоянную временную производительность и способность избегать дубликатов.
Мы изучили некоторые важные методы из API, как они могут помочь нам как разработчику использовать HashSet в его потенциале.
Как всегда, фрагменты кода можно найти на GitHub .
Источник







