- Внутренняя работа HashMap в Java
- Хэширование
- Метод hashCode()
- Метод equals()
- Корзины (Buckets)
- Вычисление индекса в HashMap
- Изменения в Java 8
- Подробно про HashMap в Java
- Реализации HashMap в Java Collections Framework
- HashMap против LinkedHashMap и TreeMap
- Объявление HashMap
- Создание и инициализация
- Итерация HashMap
- Получение и фильтрация
- Добавление, обновление и удаление
- Сравнение объектов в HashMap
- Сортировка HashMap
Внутренняя работа HashMap в Java
[примечание от автора перевода] Перевод был выполнен для собственных нужд, но если кому -то это окажется полезным, значит мир стал хоть немного, но лучше! Оригинальная статья — Internal Working of HashMap in Java
В этой статье мы увидим, как изнутри работают методы get и put в коллекции HashMap. Какие операции выполняются. Как происходит хеширование. Как значение извлекается по ключу. Как хранятся пары ключ-значение.
Как и в предыдущей статье, HashMap содержит массив Node и Node может представлять класс, содержащий следующие объекты:
- int — хэш
- K — ключ
- V — значение
- Node — следующий элемент
Теперь мы увидим, как все это работает. Для начала мы рассмотрим процесс хеширования.
Хэширование
Хэширование -это процесс преобразования объекта в целочисленную форму, выполняется с помощью метода hashCode(). Очень важно правильно реализовать метод hashCode() для обеспечения лучшей производительности класса HashMap.
Здесь я использую свой собственный класс Key и таким образом могу переопределить метод hashCode() для демонстрации различных сценариев. Мой класс Key:
Здесь переопределенный метод hashCode() возвращает ASCII код первого символа строки. Таким образом, если первые символы строки одинаковые, то и хэш коды будут одинаковыми. Не стоит использовать подобную логику в своих программах.
Этот код создан исключительно для демонстрации. Поскольку HashCode допускает ключ типа null, хэш код null всегда будет равен 0.
Метод hashCode()
Метод hashCode() используется для получения хэш кода объекта. Метод hashCode() класса Object возвращает ссылку памяти объекта в целочисленной форме (идентификационный хеш (identity hash code)). Сигнатура метода public native hashCode() . Это говорит о том, что метод реализован как нативный, поскольку в java нет какого -то метода позволяющего получить ссылку на объект. Допускается определять собственную реализацию метода hashCode(). В классе HashMap метод hashCode() используется для вычисления корзины (bucket) и следовательно вычисления индекса.
Метод equals()
Метод equals используется для проверки двух объектов на равенство. Метод реализованн в классе Object. Вы можете переопределить его в своем собственном классе. В классе HashMap метод equals() используется для проверки равенства ключей. В случае, если ключи равны, метод equals() возвращает true, иначе false.
Корзины (Buckets)
Bucket -это единственный элемент массива HashMap. Он используется для хранения узлов (Nodes). Два или более узла могут иметь один и тот -же bucket. В этом случае для связи узлов используется структура данных связанный список. Bucket -ы различаются по ёмкости (свойство capacity). Отношение между bucket и capacity выглядит следующим образом:
Один bucket может иметь более, чем один узел, это зависит от реализации метода hashCode(). Чем лучше реализованн ваш метод hashCode(), тем лучше будут использоваться ваши bucket -ы.
Вычисление индекса в HashMap
Хэш код ключа может быть достаточно большим для создания массива. Сгенерированный хэш код может быть в диапазоне целочисленного типа и если мы создадим массив такого размера, то легко получим исключение outOfMemoryException. Потому мы генерируем индекс для минимизации размера массива. По сути для вычисления индекса выполняется следующая операция:
где n равна числу bucket или значению длины массива. В нашем примере я рассматриваю n, как значение по умолчанию равное 16.
- изначально пустой hashMap: здесь размер hashmap равен 16:
HashMap: 
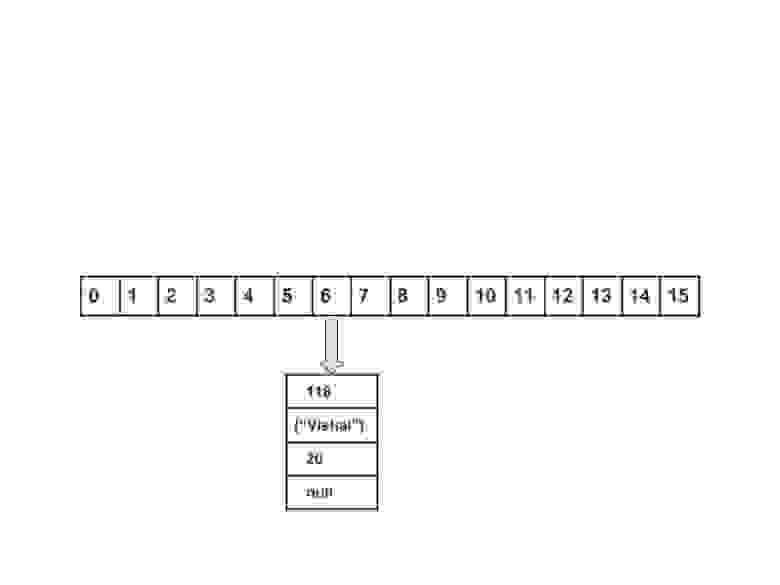
- вставка пар Ключ — Значение: добавить одну пару ключ — значение в конец HashMap
Вычислить значение ключа <"vishal">. Оно будет сгенерированно, как 118.
Вычислить индекс с помощью метода index , который будет равен 6.
Создать объект node.
Поместить объект в позицию с индексом 6, если место свободно.
Теперь HashMap выглядит примерно так:
- добавление другой пары ключ — значение: теперь добавим другую пару
Вычислить значение ключа <"sachin">. Оно будет сгенерированно, как 115.
Вычислить индекс с помощью метода index , который будет равен 3.
Создать объект node.
Поместить объект в позицию с индексом 3, если место свободно.
Теперь HashMap выглядит примерно так:

- в случае возникновения коллизий: теперь добавим другую пару
Вычислить значение ключа <"vaibhav">. Оно будет сгенерированно, как 118.
Вычислить индекс с помощью метода index , который будет равен 6.
Создать объект node.
Поместить объект в позицию с индексом 6, если место свободно.
В данном случае в позиции с индексом 6 уже существует другой объект, этот случай называется коллизией.
В таком случае проверям с помощью методов hashCode() и equals(), что оба ключа одинаковы.
Если ключи одинаковы, заменить текущее значение новым.
Иначе связать новый и старый объекты с помощью структуры данных «связанный список», указав ссылку на следующий объект в текущем и сохранить оба под индексом 6.
Теперь HashMap выглядит примерно так:

[примечание от автора перевода] Изображение взято из оригинальной статьи и изначально содержит ошибку. Ссылка на следующий объект в объекте vishal с индексом 6 не равна null, в ней содержится указатель на объект vaibhav.
- получаем значение по ключу sachin:
Вычислить хэш код объекта <“sachin”>. Он был сгенерирован, как 115.
Вычислить индекс с помощью метода index , который будет равен 3.
Перейти по индексу 3 и сравнить ключ первого элемента с имеющемся значением. Если они равны -вернуть значение, иначе выполнить проверку для следующего элемента, если он существует.
В нашем случае элемент найден и возвращаемое значение равно 30.
Вычислить хэш код объекта <"vaibhav">. Он был сгенерирован, как 118.
Вычислить индекс с помощью метода index , который будет равен 6.
Перейти по индексу 6 и сравнить ключ первого элемента с имеющемся значением. Если они равны -вернуть значение, иначе выполнить проверку для следующего элемента, если он существует.
В данном случае он не найден и следующий объект node не равен null.
Если следующий объект node равен null, возвращаем null.
Если следующий объект node не равен null, переходим к нему и повторяем первые три шага до тех пор, пока элемент не будет найден или следующий объект node не будет равен null.
Изменения в Java 8
Как мы уже знаем в случае возникновения коллизий объект node сохраняется в структуре данных «связанный список» и метод equals() используется для сравнения ключей. Это сравнения для поиска верного ключа в связанном списке -линейная операция и в худшем случае сложность равнa O(n).
Для исправления этой проблемы в Java 8 после достижения определенного порога вместо связанных списков используются сбалансированные деревья. Это означает, что HashMap в начале сохраняет объекты в связанном списке, но после того, как колличество элементов в хэше достигает определенного порога происходит переход к сбалансированным деревьям. Что улучшает производительность в худшем случае с O(n) до O(log n).
Источник
Подробно про HashMap в Java
HashMap в Java – это реализация структуры данных хэш-таблицы (пары ключ-значение, словарь) интерфейса Map, являющейся частью структуры Java Collections.
Реализации HashMap в Java Collections Framework
HashMap имеет следующие особенности:
- Коэффициент загрузки по умолчанию и начальная мощность 0,75 и 16 соответственно. Их значения важны для производительности HashMap, поскольку они могут оптимизировать производительность итераций и количество операций изменения размера и повторного хеширования.
- Нет гарантий порядка итераций.
- Производительность итерации зависит от начальной емкости (количества сегментов) плюс количества записей. Таким образом, очень важно не устанавливать слишком высокую начальную мощность (или слишком низкий коэффициент загрузки).
- Никаких повторяющихся ключей. Разрешает один нулевой ключ и несколько нулевых значений.
- Проблема коллизии хэша решена за счет использования древовидной структуры данных, начиная с Java 8, для обеспечения отдельной цепочки.
- Предлагает постоянное время O (1) в среднем и линейное время O (n) в худшем случае производительность для основных операций, таких как получение, размещение и удаление.
- Чем меньше повторяющихся хэш-кодов, тем выше прирост производительности для вышеуказанных операций.
- Ключевые объекты сравниваются на основе их равенства и реализации hashCode.
- Объекты значений сравниваются на основе реализации их метода равенства.
- HashMap не является потокобезопасным, поскольку это несинхронизированная реализация.
- В многопоточном окружении хотя бы один поток изменяет карту, она должна быть синхронизирована извне.
Давайте пройдемся по этому руководству, чтобы изучить их более подробно.
HashMap против LinkedHashMap и TreeMap
HashMap не имеет гарантий упорядочивания и работает быстрее, чем TreeMap (постоянное время по сравнению с временем журнала для большинства операций)
LinkedHashMap обеспечивает итерацию с упорядоченной вставкой и работает почти так же быстро, как HashMap.
TreeMap обеспечивает итерацию по порядку значений. TreeMap можно использовать для сортировки HashMap или LinkedHashMap
Объявление HashMap
В результате иерархии классов вы можете объявить HashMap следующими способами:
Создание и инициализация
Предоставьте фабричный метод Map.of или Map.ofEntries, начиная с Java 9, в конструктор HashMap (Map) для создания и инициализации HashMap в одной строке во время создания.
Вы также можете инициализировать HashMap после времени создания, используя put, Java 8+ putIfAbsent, putAll.
Итерация HashMap
Вы можете перебирать пары ключ-значение HashMap, используя Java 8+ forEach (BiConsumer).
Итерировать по HashMap keySet() или values() с Java 8+ forEach(Consumer).
Получение и фильтрация
Используйте entrySet(), keySet(), values(), чтобы получить набор записей сопоставления ключ-значение, набор ключей и набор значений соответственно.
Получить значение по указанному ключу с помощью get(key).
Фильтрация ключей или значений HashMap с помощью Java 8+ Stream API.
Добавление, обновление и удаление
HashMap предоставляет методы containsKey (ключ), containsValue (значение), put (ключ, значение), replace (ключ, значение) и remove (ключ), чтобы проверить, содержит ли HashMap указанный ключ или значение, чтобы добавить новый ключ. пара значений, обновить значение по ключу, удалить запись по ключу соответственно.
Сравнение объектов в HashMap
Внутренне основные операции HashMap, такие как containsKey, containsValue, put, putIfAbsent, replace и remove, работают на основе сравнения объектов элементов, которые зависят от их равенства и реализации hashCode.
В следующем примере ожидаемые результаты не достигаются из-за отсутствия реализации equals и hashCode для определенных пользователем объектов.
Вы можете решить указанную выше проблему, переопределив equals и hashCode, как показано в примере ниже.
Сортировка HashMap
В Java нет прямого API для сортировки HashMap. Однако вы можете сделать это через TreeMap, TreeSet и ArrayList вместе с Comparable и Comparator.
В следующем примере используются статические методы comparingByKey (Comparator) и comparingByValue (Comparator) для Map.Entry для сортировки ArrayList по ключам и по значениям соответственно. Этот ArrayList создается и инициализируется из entrySet() HashMap.
@Test
public void sortByKeysAndByValues_WithArrayListAndComparator() <
Map.Entry e1 = Map.entry(«k1», 1);
Map.Entry e2 = Map.entry(«k2», 20);
Map.Entry e3 = Map.entry(«k3», 3);
Map map = new HashMap<>(Map.ofEntries(e3, e1, e2));
List > arrayList1 = new ArrayList<>(map.entrySet());
arrayList1.sort(comparingByKey(Comparator.naturalOrder()));
assertThat(arrayList1).containsExactly(e1, e2, e3);
List > arrayList2 = new ArrayList<>(map.entrySet());
arrayList2.sort(comparingByValue(Comparator.reverseOrder()));
assertThat(arrayList2).containsExactly(e2, e3, e1);
>
Ниже представлен полный пример исходного кода.
import static java.util.Map.Entry.comparingByKey;
import static java.util.Map.Entry.comparingByValue;
import static org.assertj.core.api.Assertions.assertThat;
public class HashMapTest <
@Test
public void declare() <
Map map1 = new HashMap<>();
assertThat(map1).isInstanceOf(HashMap.class);
HashMap map2 = new HashMap<>();
>
@Test
public void initInOneLineWithFactoryMethods() <
// create and initialize a HashMap from Java 9+ Map.of
Map map1 = new HashMap<>((Map.of(«k1», 1, «k3», 2, «k2», 3)));
assertThat(map1).hasSize(3);
// create and initialize a HashMap from Java 9+ Map.ofEntries
Map map2 = new HashMap<>(Map.ofEntries(Map.entry(«k4», 4), Map.entry(«k5», 5)));
assertThat(map2).hasSize(2);
>
@Test
public void initializeWithPutIfAbsent() <
// Create a new HashMap
Map map = new HashMap<>();
// Add elements to HashMap
map.putIfAbsent(«k1», 1);
map.putIfAbsent(«k2», 2);
map.putIfAbsent(«k3», 3);
// Can add null key and value
map.putIfAbsent(null, 4);
map.putIfAbsent(«k4», null);
// Duplicate key will be ignored
map.putIfAbsent(«k1», 10);
assertThat(map).hasSize(5);
// The output ordering will be vary as HashMap is not reserved the insertion order
System.out.println(map);
>
@Test
public void iterateOverKeyValuePairs() <
Map map = new HashMap<>(Map.of(«k1», 1, «k2», 2));
map.forEach((k, v) -> System.out.printf(«%s=%d «, k, v));
>
@Test
public void iterateOverKeySet() <
Map map = new HashMap<>(Map.of(«k1», 1, «k2», 2));
map.values().forEach(k -> System.out.printf(«%s «, k));
>
@Test
public void retrieve() <
Map hashMap = new HashMap<>(Map.of(«k1», 1, «k2», 2));
Set > entrySet = hashMap.entrySet();
assertThat(entrySet).contains(Map.entry(«k1», 1), Map.entry(«k2», 2));
Set keySet = hashMap.keySet();
assertThat(keySet).contains(«k1», «k2»);
Collection values = hashMap.values();
assertThat(values).contains(1, 2);
>
@Test
public void getValueByKey() <
Map map = new HashMap<>(Map.of(«k1», 1, «k2», 2));
int value = map.get(«k1»);
@Test
public void filter() <
Map map = new HashMap<>(Map.of(«k1», 1, «k2», 2));
Integer[] arr = map.values().stream().filter(v -> v > 1).toArray(Integer[]::new);
assertThat(arr).contains(2);
>
@Test
public void containsPutReplaceRemove() <
Map map = new HashMap<>(Map.of(«k1», 1, «k2», 2));
boolean containedKey = map.containsKey(«k1»);
assertThat(containedKey).isTrue();
boolean containedValue = map.containsValue(2);
assertThat(containedValue).isTrue();
map.put(«k3», 3);
assertThat(map).hasSize(3);
map.replace(«k1», 10);
assertThat(map).contains(Map.entry(«k1», 10), Map.entry(«k2», 2), Map.entry(«k3», 3));
map.remove(«k3»);
assertThat(map).contains(Map.entry(«k1», 10), Map.entry(«k2», 2));
>
@Test
public void objectsComparingProblem() <
Map hashMap = new HashMap<>();
hashMap.put(new Category(1, «c1»), new Book(1, «b1»));
boolean containedKey = hashMap.containsKey(new Category(1, «c1»));
assertThat(containedKey).isFalse();
boolean containedValue = hashMap.containsValue(new Book(1, «b1»));
assertThat(containedValue).isFalse();
hashMap.put(new Category(1, «c1»), new Book(1, «b1»));
assertThat(hashMap).hasSize(2);
Book previousValue = hashMap.replace(new Category(1, «c1»), new Book(2, «b1»));
assertThat(previousValue).isNull();
hashMap.remove(new Category(1, «c1»));
assertThat(hashMap).hasSize(2);
>
static class Category <
int id;
String name;
Category(int id, String name) <
this.id = id;
this.name = name;
>
>
static class Book <
int id;
String title;
Book(int id, String title) <
this.id = id;
this.title = title;
>
>
@Test
public void objectsComparingFixed() <
Map hashMap = new HashMap<>();
hashMap.put(new CategoryFixed(1, «c1»), new BookFixed(1, «b1»));
boolean containedKey = hashMap.containsKey(new CategoryFixed(1, «c1»));
assertThat(containedKey).isTrue();
boolean containedValue = hashMap.containsValue(new BookFixed(1, «b1»));
assertThat(containedValue).isTrue();
hashMap.put(new CategoryFixed(1, «c1»), new BookFixed(1, «b1»));
assertThat(hashMap).hasSize(1);
BookFixed previousValue = hashMap.replace(new CategoryFixed(1, «c1»), new BookFixed(2, «b1»));
assertThat(previousValue).isNotNull();
hashMap.remove(new CategoryFixed(1, «c1»));
assertThat(hashMap).hasSize(0);
>
static class CategoryFixed <
int id;
String name;
CategoryFixed(int id, String name) <
this.id = id;
this.name = name;
>
@Override
public boolean equals(Object o) <
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
CategoryFixed that = (CategoryFixed) o;
return that.id &&
Objects.equals(name, that.name);
>
@Override
public int hashCode() <
return Objects.hash(id, name);
>
>
static class BookFixed <
int id;
String title;
BookFixed(int id, String title) <
this.id = id;
this.title = title;
>
@Override
public boolean equals(Object o) <
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
BookFixed bookFixed = (BookFixed) o;
return bookFixed.id &&
Objects.equals(title, bookFixed.title);
>
@Override
public int hashCode() <
return Objects.hash(id, title);
>
>
@Test
public void sortByKeysAndByValues_WithArrayListAndComparator() <
Map.Entry e1 = Map.entry(«k1», 1);
Map.Entry e2 = Map.entry(«k2», 20);
Map.Entry e3 = Map.entry(«k3», 3);
Map map = new HashMap<>(Map.ofEntries(e3, e1, e2));
List > arrayList1 = new ArrayList<>(map.entrySet());
arrayList1.sort(comparingByKey(Comparator.naturalOrder()));
assertThat(arrayList1).containsExactly(e1, e2, e3);
List > arrayList2 = new ArrayList<>(map.entrySet());
arrayList2.sort(comparingByValue(Comparator.reverseOrder()));
assertThat(arrayList2).containsExactly(e2, e3, e1);
>
>
Средняя оценка / 5. Количество голосов:
Спасибо, помогите другим — напишите комментарий, добавьте информации к статье.
Или поделись статьей
Видим, что вы не нашли ответ на свой вопрос.
Источник







