- Эффективно извлечь значения из HashMap в List
- 1 ответ 1
- Структуры данных в картинках. HashMap
- Создание объекта
- Добавление элементов
- Resize и Transfer
- Удаление элементов
- Итераторы
- Итоги
- Ссылки
- Внутренняя работа HashMap в Java
- Хэширование
- Метод hashCode()
- Метод equals()
- Корзины (Buckets)
- Вычисление индекса в HashMap
- Изменения в Java 8
Эффективно извлечь значения из HashMap в List
Какой способ более быстрый и эффективный для получения всех значений из HashMap в List ?
- С помощью метода map.values()
- С помощью stream().collect()
- С помощью iterator()
1 ответ 1
Проведем эксперимент: возьмем мапу HashMap из 10 млн различных строк и замерим скорость выполнения методов получения листа из этой мапы.
Коротко о результатах: в большинстве случаев разница не велика (время в миллисекундах)
Первые два метода: конструктор класса ArrayList и метод из него же addAll работают примерно одинаково, т.к. оба внутри используют нативный метод System.arraycopy . То же самое с методом iterator и циклом for , который при компиляции в байт-код превращается в тот же iterator .
Со стримами другая история: метод forEach работает медленнее всего, особенно в параллельном варианте, оптимизация получается в обратную сторону — такой код лучше не писать, а вот метод collect очень хорошо отрабатывает в параллельном режиме.
Лучший показатель: parallelStream().collect()
Можно упростить чуть-чуть эту строку:
И еще чуть-чуть (работает одинаково):
Подробнее:
Сперва подготавливаем мапу, заполняем различными значениями UUID :
Для замера производительности каждого метода будем выполнять по 20 итераций и считать средний показатель:
Источник
Структуры данных в картинках. HashMap
Приветствую вас, хабрачитатели!
Продолжаю попытки визуализировать структуры данных в Java. В предыдущих сериях мы уже ознакомились с ArrayList и LinkedList, сегодня же рассмотрим HashMap.

HashMap — основан на хэш-таблицах, реализует интерфейс Map (что подразумевает хранение данных в виде пар ключ/значение). Ключи и значения могут быть любых типов, в том числе и null. Данная реализация не дает гарантий относительно порядка элементов с течением времени. Разрешение коллизий осуществляется с помощью метода цепочек.
Создание объекта
Новоявленный объект hashmap, содержит ряд свойств:
- table — Массив типа Entry[], который является хранилищем ссылок на списки (цепочки) значений;
- loadFactor — Коэффициент загрузки. Значение по умолчанию 0.75 является хорошим компромиссом между временем доступа и объемом хранимых данных;
- threshold — Предельное количество элементов, при достижении которого, размер хэш-таблицы увеличивается вдвое. Рассчитывается по формуле (capacity * loadFactor);
- size — Количество элементов HashMap-а;
В конструкторе, выполняется проверка валидности переданных параметров и установка значений в соответствующие свойства класса. Словом, ничего необычного.
Вы можете указать свои емкость и коэффициент загрузки, используя конструкторы HashMap(capacity) и HashMap(capacity, loadFactor). Максимальная емкость, которую вы сможете установить, равна половине максимального значения int (1073741824).
Добавление элементов
При добавлении элемента, последовательность шагов следующая:
- Сначала ключ проверяется на равенство null. Если это проверка вернула true, будет вызван метод putForNullKey(value) (вариант с добавлением null-ключа рассмотрим чуть позже).
Далее генерируется хэш на основе ключа. Для генерации используется метод hash(hashCode), в который передается key.hashCode().
Комментарий из исходников объясняет, каких результатов стоит ожидать — метод hash(key) гарантирует что полученные хэш-коды, будут иметь только ограниченное количество коллизий (примерно 8, при дефолтном значении коэффициента загрузки).
В моем случае, для ключа со значением »0» метод hashCode() вернул значение 48, в итоге:
С помощью метода indexFor(hash, tableLength), определяется позиция в массиве, куда будет помещен элемент.
При значении хэша 51 и размере таблице 16, мы получаем индекс в массиве:
Теперь, зная индекс в массиве, мы получаем список (цепочку) элементов, привязанных к этой ячейке. Хэш и ключ нового элемента поочередно сравниваются с хэшами и ключами элементов из списка и, при совпадении этих параметров, значение элемента перезаписывается.
Если же предыдущий шаг не выявил совпадений, будет вызван метод addEntry(hash, key, value, index) для добавления нового элемента.
Для того чтобы продемонстрировать, как заполняется HashMap, добавим еще несколько элементов.
- Пропускается, ключ не равен null
Определение позиции в массиве
Подобные элементы не найдены
Footprint
Object size: 376 bytes
Как было сказано выше, если при добавлении элемента в качестве ключа был передан null, действия будут отличаться. Будет вызван метод putForNullKey(value), внутри которого нет вызова методов hash() и indexFor() (потому как все элементы с null-ключами всегда помещаются в table[0]), но есть такие действия:
- Все элементы цепочки, привязанные к table[0], поочередно просматриваются в поисках элемента с ключом null. Если такой элемент в цепочке существует, его значение перезаписывается.
Если элемент с ключом null не был найден, будет вызван уже знакомый метод addEntry().
Footprint
Object size: 496 bytes
Теперь рассмотрим случай, когда при добавлении элемента возникает коллизия.
- Пропускается, ключ не равен null
Определение позиции в массиве
Подобные элементы не найдены
Resize и Transfer
Когда массив table[] заполняется до предельного значения, его размер увеличивается вдвое и происходит перераспределение элементов. Как вы сами можете убедиться, ничего сложного в методах resize(capacity) и transfer(newTable) нет.
Метод transfer() перебирает все элементы текущего хранилища, пересчитывает их индексы (с учетом нового размера) и перераспределяет элементы по новому массиву.
Если в исходный hashmap добавить, скажем, еще 15 элементов, то в результате размер будет увеличен и распределение элементов изменится.
Удаление элементов
У HashMap есть такая же «проблема» как и у ArrayList — при удалении элементов размер массива table[] не уменьшается. И если в ArrayList предусмотрен метод trimToSize(), то в HashMap таких методов нет (хотя, как сказал один мой коллега — «А может оно и не надо?«).
Небольшой тест, для демонстрации того что написано выше. Исходный объект занимает 496 байт. Добавим, например, 150 элементов.
Теперь удалим те же 150 элементов, и снова замерим.
Как видно, размер даже близко не вернулся к исходному. Если есть желание/потребность исправить ситуацию, можно, например, воспользоваться конструктором HashMap(Map).
Итераторы
HashMap имеет встроенные итераторы, такие, что вы можете получить список всех ключей keySet(), всех значений values() или же все пары ключ/значение entrySet(). Ниже представлены некоторые варианты для перебора элементов:
Стоит помнить, что если в ходе работы итератора HashMap был изменен (без использования собственным методов итератора), то результат перебора элементов будет непредсказуемым.
Итоги
— Добавление элемента выполняется за время O(1), потому как новые элементы вставляются в начало цепочки;
— Операции получения и удаления элемента могут выполняться за время O(1), если хэш-функция равномерно распределяет элементы и отсутствуют коллизии. Среднее же время работы будет Θ(1 + α), где α — коэффициент загрузки. В самом худшем случае, время выполнения может составить Θ(n) (все элементы в одной цепочке);
— Ключи и значения могут быть любых типов, в том числе и null. Для хранения примитивных типов используются соответствующие классы-оберки;
— Не синхронизирован.
Ссылки
Инструменты для замеров — memory-measurer и Guava (Google Core Libraries).
Источник
Внутренняя работа HashMap в Java
[примечание от автора перевода] Перевод был выполнен для собственных нужд, но если кому -то это окажется полезным, значит мир стал хоть немного, но лучше! Оригинальная статья — Internal Working of HashMap in Java
В этой статье мы увидим, как изнутри работают методы get и put в коллекции HashMap. Какие операции выполняются. Как происходит хеширование. Как значение извлекается по ключу. Как хранятся пары ключ-значение.
Как и в предыдущей статье, HashMap содержит массив Node и Node может представлять класс, содержащий следующие объекты:
- int — хэш
- K — ключ
- V — значение
- Node — следующий элемент
Теперь мы увидим, как все это работает. Для начала мы рассмотрим процесс хеширования.
Хэширование
Хэширование -это процесс преобразования объекта в целочисленную форму, выполняется с помощью метода hashCode(). Очень важно правильно реализовать метод hashCode() для обеспечения лучшей производительности класса HashMap.
Здесь я использую свой собственный класс Key и таким образом могу переопределить метод hashCode() для демонстрации различных сценариев. Мой класс Key:
Здесь переопределенный метод hashCode() возвращает ASCII код первого символа строки. Таким образом, если первые символы строки одинаковые, то и хэш коды будут одинаковыми. Не стоит использовать подобную логику в своих программах.
Этот код создан исключительно для демонстрации. Поскольку HashCode допускает ключ типа null, хэш код null всегда будет равен 0.
Метод hashCode()
Метод hashCode() используется для получения хэш кода объекта. Метод hashCode() класса Object возвращает ссылку памяти объекта в целочисленной форме (идентификационный хеш (identity hash code)). Сигнатура метода public native hashCode() . Это говорит о том, что метод реализован как нативный, поскольку в java нет какого -то метода позволяющего получить ссылку на объект. Допускается определять собственную реализацию метода hashCode(). В классе HashMap метод hashCode() используется для вычисления корзины (bucket) и следовательно вычисления индекса.
Метод equals()
Метод equals используется для проверки двух объектов на равенство. Метод реализованн в классе Object. Вы можете переопределить его в своем собственном классе. В классе HashMap метод equals() используется для проверки равенства ключей. В случае, если ключи равны, метод equals() возвращает true, иначе false.
Корзины (Buckets)
Bucket -это единственный элемент массива HashMap. Он используется для хранения узлов (Nodes). Два или более узла могут иметь один и тот -же bucket. В этом случае для связи узлов используется структура данных связанный список. Bucket -ы различаются по ёмкости (свойство capacity). Отношение между bucket и capacity выглядит следующим образом:
Один bucket может иметь более, чем один узел, это зависит от реализации метода hashCode(). Чем лучше реализованн ваш метод hashCode(), тем лучше будут использоваться ваши bucket -ы.
Вычисление индекса в HashMap
Хэш код ключа может быть достаточно большим для создания массива. Сгенерированный хэш код может быть в диапазоне целочисленного типа и если мы создадим массив такого размера, то легко получим исключение outOfMemoryException. Потому мы генерируем индекс для минимизации размера массива. По сути для вычисления индекса выполняется следующая операция:
где n равна числу bucket или значению длины массива. В нашем примере я рассматриваю n, как значение по умолчанию равное 16.
- изначально пустой hashMap: здесь размер hashmap равен 16:
HashMap: 
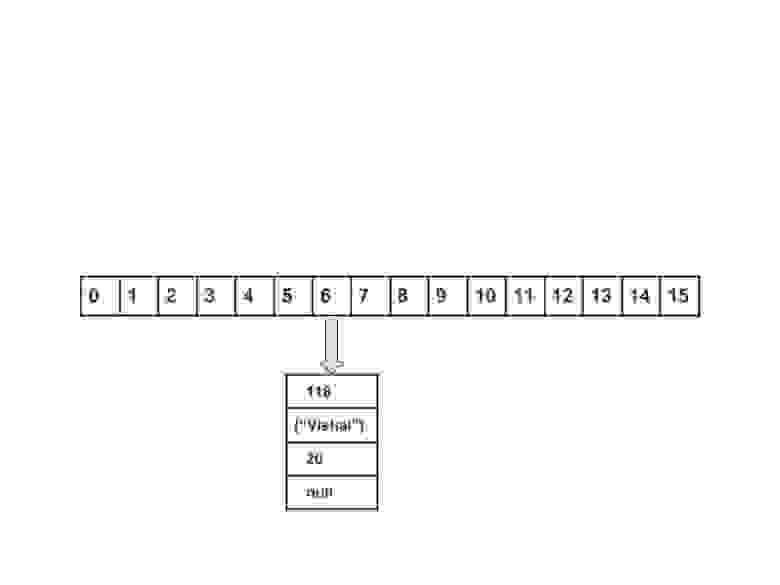
- вставка пар Ключ — Значение: добавить одну пару ключ — значение в конец HashMap
Вычислить значение ключа <"vishal">. Оно будет сгенерированно, как 118.
Вычислить индекс с помощью метода index , который будет равен 6.
Создать объект node.
Поместить объект в позицию с индексом 6, если место свободно.
Теперь HashMap выглядит примерно так:
- добавление другой пары ключ — значение: теперь добавим другую пару
Вычислить значение ключа <"sachin">. Оно будет сгенерированно, как 115.
Вычислить индекс с помощью метода index , который будет равен 3.
Создать объект node.
Поместить объект в позицию с индексом 3, если место свободно.
Теперь HashMap выглядит примерно так:

- в случае возникновения коллизий: теперь добавим другую пару
Вычислить значение ключа <"vaibhav">. Оно будет сгенерированно, как 118.
Вычислить индекс с помощью метода index , который будет равен 6.
Создать объект node.
Поместить объект в позицию с индексом 6, если место свободно.
В данном случае в позиции с индексом 6 уже существует другой объект, этот случай называется коллизией.
В таком случае проверям с помощью методов hashCode() и equals(), что оба ключа одинаковы.
Если ключи одинаковы, заменить текущее значение новым.
Иначе связать новый и старый объекты с помощью структуры данных «связанный список», указав ссылку на следующий объект в текущем и сохранить оба под индексом 6.
Теперь HashMap выглядит примерно так:

[примечание от автора перевода] Изображение взято из оригинальной статьи и изначально содержит ошибку. Ссылка на следующий объект в объекте vishal с индексом 6 не равна null, в ней содержится указатель на объект vaibhav.
- получаем значение по ключу sachin:
Вычислить хэш код объекта <“sachin”>. Он был сгенерирован, как 115.
Вычислить индекс с помощью метода index , который будет равен 3.
Перейти по индексу 3 и сравнить ключ первого элемента с имеющемся значением. Если они равны -вернуть значение, иначе выполнить проверку для следующего элемента, если он существует.
В нашем случае элемент найден и возвращаемое значение равно 30.
Вычислить хэш код объекта <"vaibhav">. Он был сгенерирован, как 118.
Вычислить индекс с помощью метода index , который будет равен 6.
Перейти по индексу 6 и сравнить ключ первого элемента с имеющемся значением. Если они равны -вернуть значение, иначе выполнить проверку для следующего элемента, если он существует.
В данном случае он не найден и следующий объект node не равен null.
Если следующий объект node равен null, возвращаем null.
Если следующий объект node не равен null, переходим к нему и повторяем первые три шага до тех пор, пока элемент не будет найден или следующий объект node не будет равен null.
Изменения в Java 8
Как мы уже знаем в случае возникновения коллизий объект node сохраняется в структуре данных «связанный список» и метод equals() используется для сравнения ключей. Это сравнения для поиска верного ключа в связанном списке -линейная операция и в худшем случае сложность равнa O(n).
Для исправления этой проблемы в Java 8 после достижения определенного порога вместо связанных списков используются сбалансированные деревья. Это означает, что HashMap в начале сохраняет объекты в связанном списке, но после того, как колличество элементов в хэше достигает определенного порога происходит переход к сбалансированным деревьям. Что улучшает производительность в худшем случае с O(n) до O(log n).
Источник







