- Как найти несколько строк и шаблонов с помощью Grep
- Grep несколько шаблонов
- Grep несколько строк
- Выводы
- ИТ База знаний
- Полезно
- Навигация
- Серверные решения
- Телефония
- Корпоративные сети
- Руководство по команде grep в Linux
- Про Linux за 5 минут | Что это или как финский студент перевернул мир?
- Для чего мы пользуемся grep-ом?
- Поиск строк
- Поиск по нескольким параметрам
- Разница между grep, egrep fgrep, pgrep, zgrep
- Разница между find и grep
- Рекурсивный поиск
- Найти пробелы и табуляцию
- Использование регулярных выражений
- Grep вывести вторую строку
- Команда grep без опций и аргумента.
- Работа с файлами
- Параметры grep
- Опция -r
- Опция -i
- Опция -c
- Опция -n
- Опция -v
- Опция -w
- Опция -x
- Опция -l
- Опция -L
- Немного хитростей
- Хитрость первая
- Хитрость вторая
- Хитрость третья
- Хитрость четвертая
- Хитрость пятая
- Хитрость шестая
- Хитрость седьмая
- Опция -o
- Опция -q
- Опция -s
- Опции — расширения GNU
- Опция -D ДЕЙСТВИЕ
- Опция -d ДЕЙСТВИЕ
- Опция -H
- Опция -h
- Опция -I
- Опция —include=ОБРАЗЕЦ_имени_файла
- Опция —exclude=ОБРАЗЕЦ_имени_файла
- Опция -m ЧИСЛО_СТРОК
- Опция -y
- Опция —mmap
- Опция -Z
- Опция -z
- Команда grep и регулярные выражения
- Опция -G
- Опция -E
- Опция -P
- Опция -F
- Команда grep и символы кириллицы.
- Резюме команды grep
Как найти несколько строк и шаблонов с помощью Grep
grep — это мощный инструмент командной строки, который позволяет вам искать в одном или нескольких входных файлах строки, соответствующие регулярному выражению, и записывать каждую совпадающую строку в стандартный вывод.
В этой статье мы покажем вам, как использовать GNU grep для поиска нескольких строк или шаблонов.
Grep несколько шаблонов
GNU grep поддерживает три синтаксиса регулярных выражений: базовый, расширенный и Perl-совместимый. Если тип регулярного выражения не указан, grep интерпретирует шаблоны поиска как базовые регулярные выражения.
Для поиска нескольких шаблонов используйте оператор OR (чередование).
Оператор чередования | (pipe) позволяет вам указать различные возможные совпадения, которые могут быть буквальными строками или наборами выражений. Этот оператор имеет самый низкий приоритет среди всех операторов регулярных выражений.
Синтаксис поиска нескольких шаблонов с использованием базовых регулярных выражений grep следующий:
Всегда заключайте регулярное выражение в одинарные кавычки, чтобы избежать интерпретации и расширения метасимволов оболочкой.
При использовании основных регулярных выражений метасимволы интерпретируются как буквальные символы. Чтобы сохранить особые значения метасимволов, они должны быть экранированы обратной косой чертой ( ). Вот почему мы избегаем оператора ИЛИ ( | ) косой чертой.
Чтобы интерпретировать шаблон как расширенное регулярное выражение, вызовите grep с параметром -E (или —extended-regexp ). При использовании расширенного регулярного выражения не избегайте символа | оператор:
Для получения дополнительной информации о том, как создавать регулярные выражения, ознакомьтесь с нашей статьей Grep regex .
Grep несколько строк
Буквальные строки — это самые простые шаблоны.
В следующем примере мы ищем все вхождения слов fatal , error и critical в файле ошибок журнала Nginx :
Если искомая строка содержит пробелы, заключите ее в двойные кавычки.
Вот тот же пример с использованием расширенного регулярного выражения, которое избавляет от необходимости экранировать оператор |
По умолчанию grep чувствителен к регистру. Это означает, что символы верхнего и нижнего регистра рассматриваются как разные.
Чтобы игнорировать регистр при поиске, вызовите grep with параметром -i (или —ignore-case ):
При поиске строки grep отобразит все строки, в которых строка встроена в строки большего размера. Поэтому, если вы искали «error», grep также напечатает строки, где «error» встроено в слова большего размера, например, «errorless» или «antiterrorists».
Чтобы вернуть только те строки, в которых указанная строка представляет собой целое слово (заключенное в символы, отличные от слов), используйте параметр -w (или —word-regexp ):
Символы слова включают буквенно-цифровые символы (az, AZ и 0–9) и символы подчеркивания (_). Все остальные символы считаются несловесными символами.
Чтобы узнать больше о параметрах grep , посетите нашу статью Команда Grep .
Выводы
Мы показали вам, как использовать grep для поиска нескольких шаблонов, строк и слов.
Если у вас есть какие-либо вопросы или отзывы, не стесняйтесь оставлять комментарии.
Источник
ИТ База знаний
Курс по Asterisk
Полезно
— Узнать IP — адрес компьютера в интернете
— Онлайн генератор устойчивых паролей
— Онлайн калькулятор подсетей
— Калькулятор инсталляции IP — АТС Asterisk
— Руководство администратора FreePBX на русском языке
— Руководство администратора Cisco UCM/CME на русском языке
— Руководство администратора по Linux/Unix
Навигация
Серверные решения
Телефония
FreePBX и Asterisk
Настройка программных телефонов
Корпоративные сети
Протоколы и стандарты
Руководство по команде grep в Linux
Читать между строк
10 минут чтения
То, что система Linux предоставляет пользователю большое многообразие разного функционала уже не секрет. На одном из прошлых материалов мы рассмотрели, как и где можно использовать команду find. В этой же статье мы на примерах разберём команду grep, мощный инструмент системных администраторов.
Мини — курс по виртуализации
Знакомство с VMware vSphere 7 и технологией виртуализации в авторском мини — курсе от Михаила Якобсена

Про Linux за 5 минут | Что это или как финский студент перевернул мир?

Для чего мы пользуемся grep-ом?
Grep это утилита командной строки Linux, который даёт пользователям возможность вести поиск строки. С его помощью можно даже искать конкретные слова в файле. Также можно передать вывод любой команды в grep, что сильно упрощает работу во время поиска и траблшутинга.
Возьмём команду ls. Сама по себе она выводит список всех файлов и папок.
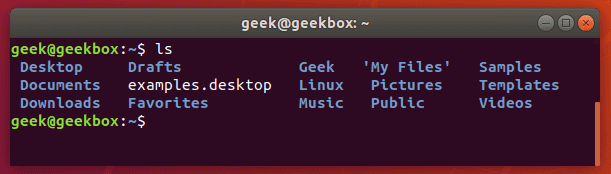
Но если нужно найти конкретную папку или один файл среди сотни других, то мы можем передать вывод команды ls в grep через вертикальную черту (|), а уже grep-у параметром передать нужное слово.
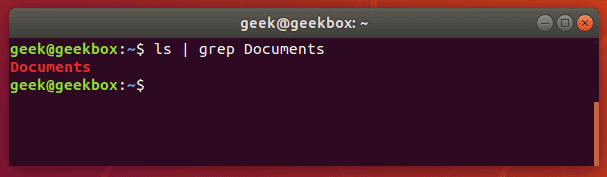
Если команда grep ничего не вернула, значит искомого файла/папки не существует в данной директории.
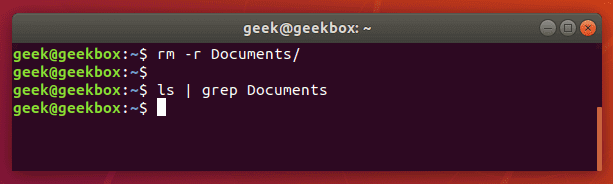
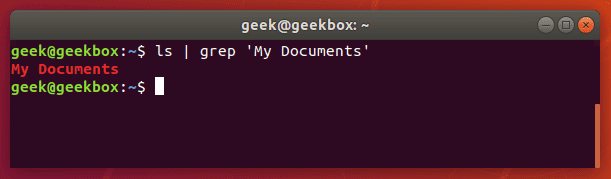
Поиск строк
Если же нужно найти не одно слово, а словосочетание или целое предложение, то параметр команды grep должно быть выделено кавычками. Grep поддерживает как одинарные, так и двойные кавычки.
Несмотря на то, что команда grep чаще используется как своего рода фильтр для других команд, но её также можно использовать отдельно как на примере ниже.
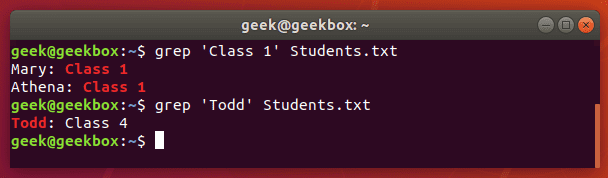
В этом примере мы вели поиск указанных в кавычках слов в файле Students.txt и команда grep успешно справилась со своей задачей.
Поиск по нескольким параметрам
Команде grep можно передавать не один параметр, а несколько. Для этого перед каждым аргументом пишется ключ e. Эту команду система понимает, как «или-или» и выводит все вхождения указанных слов. Заметьте, что кавычками выделена только строка, которая содержит пробел.

Разница между grep, egrep fgrep, pgrep, zgrep
Исторически разные версии Linux-а включали разновидности команды grep. Хотя в современных версия систем базовая команда grep поддерживает все возможности, которыми обладают egrep fgrep, pgrep, zgrep, но все же их тоже стоит рассмотреть.
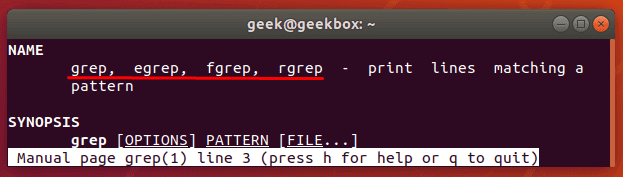
Как видно из вывода man grep (мануал по команде grep), все эти версии всего лишь разные названия основной команды. Например, egrep это тоже самое, что и grep E (помните, командная строка Linux регистрозависимая и команды grep e и grep E интерпретируются по разному). Этой команде в качестве шаблона передается расширенное регулярное выражение. Существует очень много разных ситуаций, где можно воспользоваться этой командой. Например, две команды ниже эквивалентны и выводят все строки, в которых есть две подряд идущих буквы «p».
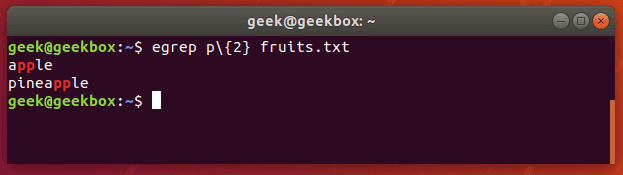
Fgrep это команда grep F, которая обрабатывает переданный шаблон как список фиксированных данных строкового типа. Эта команда полезна, когда в шаблоне используются зарезервированные для регулярных выражений символы, которые при обычно grep пришлось бы экранировать.
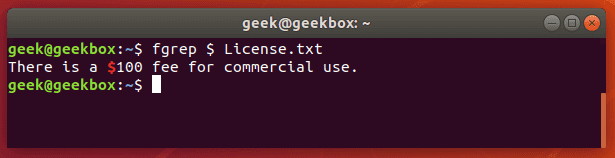
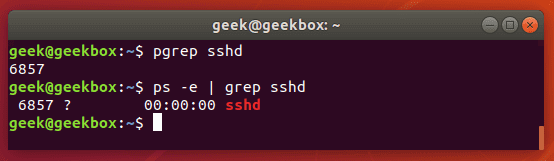
Команда pgrep используется для поиска конкретного процесса, запущенного в системе и возвращает идентификатор указанного процесса (PID). Команда ниже выводит PID процесса sshd. Почти такого же результата можно достичь если запустить команду ps e | grep sshd.
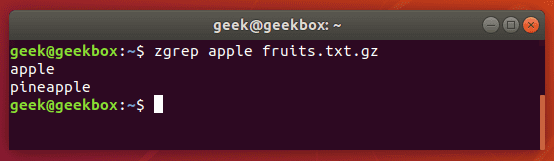
Команда zgrep используется для поиска указанного шаблона в заархивированных файлах, что очень удобно так как не приходится сначала разархивировать файл, а потом уже вести поиск.
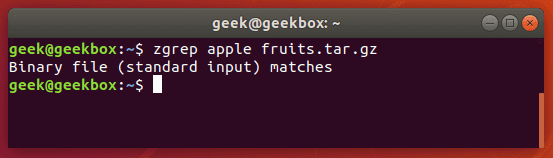
Zgrep также работает с tar архивами, но ограничивается лишь выводом информации о том, нашла ли она соответствие или нет. Это замечание мы сделали потому, что чаще всего gzip-ом архивируются tar файлы.
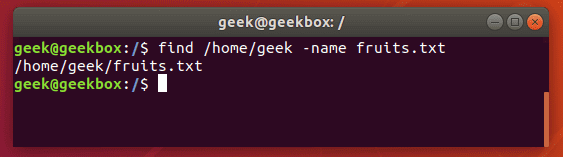
Разница между find и grep
Те, кто только начинает пользоваться командной строкой Linux должны понимать, что find и grep это две разные команды, которые имеют совсем разные функции, даже если оба используются для «поиска» чего-либо.
При поиске файлов grep-ом удобно пользоваться для фильтрации вывода команды find, как и было показано в начале материала. Но если нужно найти какой-то файл в системе по его названию или части названия (при этом используется маска *), то лучше всего обратиться к find. Она выведёт точно расположение искомого файла.
Рекурсивный поиск
Чтобы вести поиск по указанному шаблону среди всех файлов во всех папках и подпапках, команду grep нужно запустить с ключом r. Команда выведет все файлы, где найдено совпадение с указанным шаблоном, а также путь к ним. По умолчанию поиск ведется по текущей директории и поддиректориях.

Найти пробелы и табуляцию
Как и было отмечено ранее, если в шаблоне поиска содержится пробел, то мы должны выделять строку кавычками. Это мы можем использовать для поиска пробелов и знаков табуляции в файле. О том как вставить табуляцию чуть позже.

Есть несколько путей вставки табуляции, но некоторые дистрибутивы могут не поддерживать их. Как известно, в командной строке Linux клавиша TAB сама по себе дополняет введённую команду. Но если комбинировать клавиши ctrl+v, а затем нажать TAB, то система воспримет это как знак табуляции. $ grep » » sample.txt
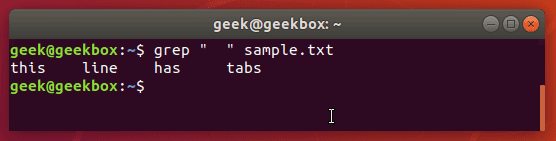
Эта фишка очень помогает при поиске среди конфигурационных файлов системы, так как значения от параметров отделяются табуляцией.
Использование регулярных выражений
Регулярные выражения сильно расширяют возможности команды grep, что позволяет нам вести более гибкий поиск. Далее мы рассмотрим несколько вариантов использования регулярных выражений.
[квадратные скобки] они используются чтобы проверить на соответствие одному из указанных символов.
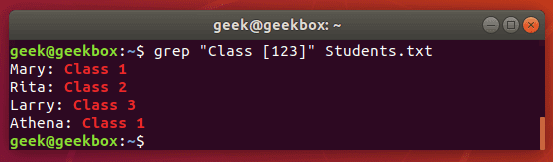
[-] знак дефиса означает диапазон значений. Это могут быть как буквы, так и цифры.
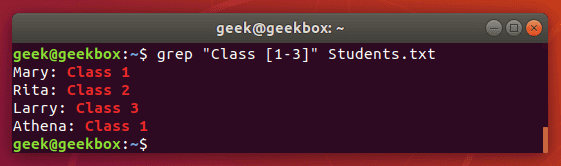
Вторая команда вывела то же, что и первая, но здесь мы обошлись знаком диапазона.
^ каретка используется для поиска строк, которые начинаются с указанного шаблона. Команда ниже выведет все строки, которые начинаются с буквы «А».
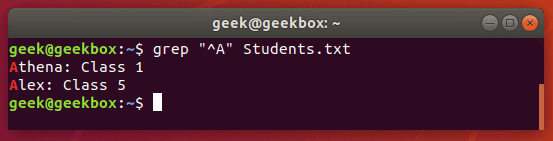
[^] но между квадратными скобками смысл каретки меняется. Здесь он исключает из поиска следующие за ней символы или диапазон символов.
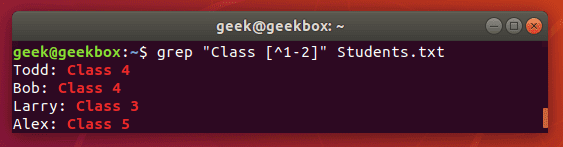
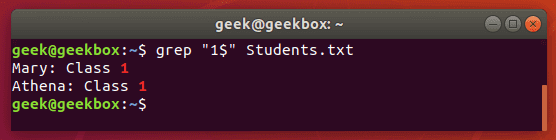
$ знак доллара означает конец строки. Команда выведет только те строки, в конце которых встречает указанный шаблон.
.точка обозначает один любой символ. Чтобы указать несколько любых символов, можно написать символ точку нужное количество раз.
Источник
Grep вывести вторую строку
Команда grep, одна из самых известных и употребительных команд Юниксовидных ОС, ведет свое начало от первого текстового редактора Юникс — ed. В этом редакторе была команда g/re/p (global/regular expression/print), которая и дала свое название новой программе.
Команда grep служит для поиска строк, содержащих заданный пользователем образец.
Причем обязательным для ввода является только ОБРАЗЕЦ, можно обойтись даже без имени файла (аргумента).
Команда grep без опций и аргумента.
Если не указано имени файла, то команда обрабатывает стандартный ввод, например строки, набранные на клавиатуре:
В скобках показано, когда я нажимал клавишу Enter, чтобы перейти на новую строку. Одновременно, при нажатии Enter, программа выводила строки, содержащие ОБРАЗЕЦ (кот), отсюда и удвоение этих строк. Видно, что команда реагировала просто на сочетание букв, а не на слово «кот», иначе строка со словом «который» не попала бы в вывод.
Тут мы подошли к очень важному определению строки. Строкой команда grep (как и все остальные команды Юникс) считает все символы, находящиеся между двумя символами новой строки. Эти невидимые на экране символы возникают в тексте каждый раз, когда пользователь нажимает клавишу Enter. В Юниксовидных системах символ новой строки обозначается обратным слэшем с буквой n (\n). Таким образом, строка может быть любого размера, начиная с одного символа и до многомегабайтного текста. И команда grep честно выведет эту строку, при условии, что она содержит ОБРАЗЕЦ.
Работа с файлами
Команда grep может обрабатывать любое количество файлов одновременно. Создадим три файла:
И дадим команду:
В выводе перечислены файлы, и указано, в каком из них какая строка содержит символ астериска. ОБРАЗЕЦ (*) пришлось взять в кавычки, чтобы командный интерпретатор понял, что имеется в виду символ, а не условный знак. Попробуйте без кавычек, увидите — ничего не получится.
Команда grep вовсе не ограничена одним выражением в качестве ОБРАЗЦА, можно задавать хоть целые фразы. Только их нужно заключать в кавычки (одинарные или двойные):
Возможности поиска при помощи команды grep могут быть значительно расширены применением групповых символов. Например, уже упоминавшийся астериск (звездочка) используется для представления любого символа или группы символов, если речь идет о тексте, и любого файла или группы файлов, если речь идет о директории.
Создадим директорию /example, в которую поместим файлы наших примеров: 123.txt, ast.txt, alice.txt и дадим команду:
То есть мы приказали просмотреть все файлы директории /example. Таким способом можно обследовать такие огромные директории как /usr, /dev, и любые другие.
Параметры grep
Опция -r
Еще больше увеличит зону поисков опция -r, которая заставит команду grep рекурсивно обследовать все дерево указанной директории, то есть субдиректории, субдиректории субдиректорий, и так далее вплоть до файлов. Например:
/boot/grub/grub.txt:Press the [Esc] key to return to the GRUB menu. /boot/grub/menu.lst:# GRUB configuration file ‘/boot/grub/menu.lst’. /boot/grub/menu.lst:gfxmenu (hd0,3)/boot/message
Опция -i
Приказывает команде игнорировать регистр символов, таким образом, поиск будет производиться как среди заглавных, так и среди строчных букв.
Опция -c
Эта опция не выводит строки, а подсчитывает количество строк, в которых обнаружен ОБРАЗЕЦ. Например:
То есть в восьми строках файла /etc/group встречается сочетание символов root.
Опция -n
При использовании этой опции вывод команды grep будет указывать номера строк, содержащих ОБРАЗЕЦ:
Опция -v
Выполняет работу, обратную обычной — выводит строки, в которых ОБРАЗЕЦ не встречается:
Опция -w
Заставит команду grep искать только строки, содержащие все слово или фразу, составляющую ОБРАЗЕЦ. Например:
Не дает вывода, то есть не находит строк, содержащих выражение «длинная ко». А вот команда:
находит точное соответствие в файле alice.txt.
Опция -x
Еще более строгая. Она отберет только те строки исследуемого файла или файлов, которые полностью совпадают с ОБРАЗЦОМ.
Внимание: Мне попадались (на собственном компьютере) версии grep (например, GNU 2.5), в которых опция -x работала неадекватно. В то же время, другие версии (GNU 2.5.1) работали прекрасно. Если что-то не ладится с этой опцией, попробуйте другую версию, или обновите свою.
Опция -l
Команда grep с этой опцией не возвращает строки, содержащие ОБРАЗЕЦ, но сообщает лишь имена файлов, в которых данный образец найден:
Замечу, что сканирование каждого из заданных файлов продолжается только до первого совпадения с ОБРАЗЦОМ.
Опция -L
Наоборот, сообщает имена тех файлов, где не встретился ОБРАЗЕЦ:
Как мы имели случай заметить, команда grep, в поисках соответствия ОБРАЗЦУ, просматривает только содержимое файлов, но не их имена. А так часто нужно найти файл по его имени или другим параметрам, например времени модификации! Тут нам придет на помощь простейший программный канал (pipe). При помощи знака программного канала — вертикальной черты (|) мы можем направить вывод команды ls, то есть список файлов в текущей директории, на ввод команды grep, не забыв указать, что мы, собственно, ищем (ОБРАЗЕЦ). Например:
Находясь в директории Desktop, мы «попросили» найти на Рабочем столе все файлы, в названии которых есть выражение «grep». И нашли одну директорию grep/ и текстовой файл grep-ru.txt, который я в данный момент и пишу.
Если мы хотим искать по другим параметрам файла, а не по его имени, то следует применить команду ls -l, которая выводит файлы со всеми параметрами:
И вот мы получили список всех файлов, модифицированных 30 декабря 2008 года.
Команда grep незаменима при просмотре логов и конфигурационных файлов. Классически примером использования команды grep стал программный канал с командой dmesg. Команда dmesg выводит те самые сообщения ядра, которые мы не успеваем прочесть во время загрузки компьютера. Допустим, мы подключили через USB порт новый принтер, и теперь хотим узнать, как ядро «окрестило» его. Дадим такую команду:
Опция -i необходима, так как usb часто пишется заглавными буквами. Проделайте этот пример самостоятельно — у него длинный вывод, который не укладывается в рамки данной статьи.
Немного хитростей
Если продолжить описание множества опций команды grep, то статья станет утомительной и нечитаемой. Поэтому, рассмотрев необходимый минимум опций, можно развлечься всякими хитростями при применении этой замечательной команды.
Хитрость первая
Как заставить grep указать в выводе имя файла, где найдено соответствие ОБРАЗЦУ? Например, мы хотим найти строку, содержащую выражение «красивая девочка» в файле alice.txt, да так, чтобы в выводе фигурировало имя файла (для отчета). Если просто дать команду:
То никакого имени файла там не будет. Но стоит добавить в аргументы еще один файл, как все заработает. Обычно, чтобы избежать неожиданностей, указывают файл /dev/null:
Хитрость вторая
Используя «чистые» опции команды grep, мы можем получить все строки, содержащие ОБРАЗЕЦ либо в составе других слов (без опций), либо в виде заданного слова (опция -w). А как найти слова, которые заканчиваются на -ОБРАЗЕЦ или начинаются с ОБРАЗЕЦ-? Для этого существуют специальные значки: \ , означающий, что ОБРАЗЕЦ будет концом слова.
Это был файл kot.txt целиком.
А это были слова, оканчивающиеся на -kot.
Эти начинаются на kot-.
А вот был «чистый» кот.
Прошу простить за транслитерацию, но с нашими буквами эта хитрость как-то не срабатывает, а с английскими словами не все поймут.
Хитрость третья
Как быть, если ОБРАЗЕЦ начинается с дефиса, ведь команда примет его за опцию?
Так и есть — принимает за опцию. Ну так дадим ей опцию -e, которая означает: «Воспринимать ОБРАЗЕЦ только как образец».
Совсем другое дело.
Хитрость четвертая
Как посмотреть соседние строчки?
Требуется соблюсти следующие условия:
Просмотр вверх и вниз на две строки.
Просмотр вниз на одну строку.
Требуется соблюсти следующие условия:
Просмотр вверх на одну строку.
Хитрость пятая
Что означают сообщения в первых двух строках вывода?
Сообщение «Бинарный файл совпадает» («Binary file matches») появляется, когда совпадение с образцом встречается в бинарных файлах. Если бы grep вывел строки из таких файлов на дисплей, толку было бы немного, а на дисплее могла возникнуть неразбериха (а может быть, и чего похуже, если драйвер терминала воспримет какие-либо фрагменты бинарного файла как команды). Если вы хотите все-таки увидеть эти строки, то применяйте опцию -a или —binary-files=text. Если хотите подавить вывод сообщений «Бинарный файл совпадает», то применяйте опцию -I или —binary-files=without-match.
Хитрость шестая
Как искать строки, содержащие несколько ОБРАЗЦОВ?
Применить программный канал, канализируя вывод одной команды grep с вводом следующей команды grep.
Первый grep ищет у нас «у», а второй — «*» и оба находят искомое в одной строке: «у нее такая ******». Можно сделать эту цепочку команд grep любой длины, было бы чего искать, да строчки достаточно длинные 🙂
Хитрость седьмая
Можно ли искать одновременно в стандартном вводе и в файле?. Можно, если перед именем файла поставить дефис:
Внимание: Если перед дефисом и после него не будет пробелов, то команда не сработает.
Но настало время вернуться к опциям команды grep.
Пока я занимался хитростями, успел позабыть, какие из опций уже описал, а какие нет. Поэтому я дал команду:
и получил файл option.txt, в котором перечислены все фигурирующие в файле grep-ru.txt опции.
Общее количество опций программы подавляет, поэтому пойдем по алфавиту, пропуская те, что я уже описал.
Весьма полезная опция, когда нужно искать несколько ОБРАЗЦОВ, причем не в одной строке, как мы делали в шестой Хитрости, а в разных. Для того чтобы воспользоваться этой опцией, нужно составить файл, в котором поместить искомые ОБРАЗЦЫ по одному на строчке:
А затем дать команду:
Предупреждение: Эта полезная опция, к сожалению, работает не на всех версиях grep. На версии GNU grep 2.5 работает неадекватно, а на GNU grep 2.5.1 — прекрасно. Так что обновляйтесь, господа. Текущая стабильная версия GNU grep — 2.5.3.
Опция -o
Возвращает не всю строку, где найдено соответствие ОБРАЗЦУ, а только совпадающую с ОБРАЗЦОМ часть строки.
$ grep ‘английскими’ grep-ru.txt
Прошу простить за транслитерацию, но с нашими буквами как-то эта хитрость не срабатывает, а с английскими словами не все поймут.
А вот с опцией -o:
Опция -q
Ничего не выдает на стандартный вывод. В случае нахождения соответствия с ОБРАЗЦОМ немедленно отключается с нулевым статусом. Отключается также при обнаружении ошибки. Для чего это — не знаю. У меня получалось, что программа мгновенно прекращает работу, есть ли совпадения, нет ли, без всяких сообщений, в том числе и о нулевом статусе. Опробовал обе доступные версии grep.
Опция -s
Подавляет сообщения о несуществующих или нечитаемых файлах.
Предупреждение: традиционные версии последних двух опции (-q и -s) не соответствуют стандарту POSIX.2 и не совпадают с GNU версиями. Поэтому их нельзя применять в скриптах для командной оболочки. Просто перенаправляйте вывод на /dev/null.
Опции — расширения GNU
Опции -A —after-context=ЧИСЛО_СТРОК
С этими тремя опциями мы уже познакомились в четвертой Хитрости, они позволяют посмотреть соседние строки. -A: количество строк после совпадения с ОБРАЗЦОМ,
-B: количество строк перед совпадением, и -C: количество строк вокруг совпадения.
Выделяет найденные строки цветом. Значения КОГДА могут быть: never (никогда), always (всегда), или auto. Пример:
Опция -D ДЕЙСТВИЕ
Если исследуемый файл является файлом устройства, FIFO (именованным каналом) или сокетом, то следует применять эту опцию. ДЕЙСТВИЙ всего два: read (прочесть), и skip (пропустить). Если вы указываете ДЕЙСТВИЕ read (используется по умолчанию), то программа попытается прочесть специальный файл, как если бы он был обычным файлом; если указываете ДЕЙСТВИЕ skip, то файлы устройств, FIFO и сокеты будут молча проигнорированы.
Опция -d ДЕЙСТВИЕ
Если входной файл является директорией, то используйте эту опцию. ДЕЙСТВИЕ read (прочесть) попытается прочесть директорию как обычный файл (некоторые ОС и файловые системы запрещают это; тогда появятся соответствующие сообщения, либо директории молча пропустят). Если ДЕЙСТВИЕ skip (пропустить), то директории будут молча проигнорированы. Если ДЕЙСТВИЕ recurse (рекурсивно), то grep будет просматривать все файлы и субдиректории внутри заданного каталога рекурсивно. Это эквивалент опции -r, с которой мы уже познакомились.
Опция -H
Выдает имя файла для каждого совпадения с ОБРАЗЦОМ. Мы успешно делали это без всяких опций в Хитрости второй.
Опция -h
Подавляет вывод имен файлов, когда задано несколько файлов для исследования.
Опция -I
Обрабатывает бинарные файлы как не содержащие совпадений с ОБРАЗЦОМ; эквивалент опции —binary-files=without-match.
Опция —include=ОБРАЗЕЦ_имени_файла
При рекурсивном исследовании директорий обследовать только файлы, содержащие в своем имени ОБРАЗЕЦ_имени_файла.
Опция —exclude=ОБРАЗЕЦ_имени_файла
При рекурсивном исследовании директорий пропускать файлы, содержащие в своем имени ОБРАЗЕЦ_имени_файла.
Опция -m ЧИСЛО_СТРОК
Прекратить обработку файла после того, как количество совпадений с ОБРАЗЦОМ достигнет ЧИСЛА_СТРОК:
Опция -y
Синоним опции -i (не различать верхний и нижний регистр символов).
Опции -U и -u применяются только под MS-DOS и MS-Windows, тут нечего о них говорить.
Опция —mmap
Использует системный вызов mmap вместо системного вызова read. Может дать лучшую производительность, а может привести к ошибкам. Это для продвинутых пользователей.
Опция -Z
Если в выводе программы имена файлов (например при опции -l), то опция -Z после каждого имени файла выводит нулевой байт вместо символа новой строки (как обычно происходит). Это делает вывод однозначным, даже если имена файлов содержат символы новой строки. Эта опция может быть использована совместно с такими командами как: find -print0, perl -0, sort -z, xargs -0 для обработки файловых имен, составленных необычно, даже содержащих символы новой строки. (Хотел бы я знать, как можно включить символ новой строки в имя файла. Если кто знает, не поленитесь — сообщите мне.)
Опция -z
Рассматривает ввод как набор строк, каждая из которых заканчивается не символом новой строки, а нулевым байтом. Как и предыдущая опция, используется совместно с вышеперечисленными командами для обработки экзотических имен файлов.
Команда grep и регулярные выражения
Регулярные выражения (Regular Expressions) это система синтаксического разбора текстовых фрагментов по формализованному шаблону, основанная на системе записи ОБРАЗЦОВ для поиска. Проще говоря, регулярное выражение — тот же, уже привычный нам ОБРАЗЕЦ для поиска, только составленный по определенным правилам. Как математические формулы составляются при помощи набора операторов (плюс, минус, степень, корень и прочее), так и регулярные выражения конструируются при помощи различных операторов (?, *, +,
Тема регулярных выражений настолько обширна, что требует для своего освещения отдельной статьи; в данной статье мы не будем ее подробно разбирать. Скажу лишь, что существует несколько версий синтаксиса регулярных выражений: Базовый (basic) BRE, Расширенный (extended) ERE и регулярные выражения языка Perl.
Опция -G
Рассматривает ОБРАЗЕЦ как базовое регулярное выражение. Эта опция используется по умолчанию.
Опция -E
Рассматривает ОБРАЗЕЦ как расширенное регулярное выражение.
Опция -P
Рассматривает ОБРАЗЕЦ как регулярное выражение языка Perl.
Опция -F
Рассматривает ОБРАЗЕЦ как список «фиксированных выражений» (fixed strings — термин из области регулярных выражений), разделенных символами новой строки. Будет искать соответствия любому из них.
Кроме того, существуют две альтернативные команды EGREP и FGREP. Обе они соответствуют опциям -E и -F соответственно.
Опции —help и —version (-V) общеизвестны, и я не буду на них останавливаться.
Команда grep и символы кириллицы.
Читая эту статью, вы не могли не заметить, что большинство примеров составлено на русском языке. Я еще не встречал консольных команд, столь хорошо «владеющих русским». Теперь, когда я разобрался с этой командой, то уже не понимаю, как мог обходиться без нее при написании статей (по-русски, разумеется). Лишь некоторые опции «дают прокол» при обработке символов кириллицы.
Резюме команды grep
Команда grep настолько полезна, многофункциональна и проста в употреблении, что, однажды познакомившись с ней, невозможно представить себе работы без нее. Особенно полезна эта команда в качестве фильтра в составе программных каналов (pipes).
Источник







