- ИТ База знаний
- Полезно
- Навигация
- Серверные решения
- Телефония
- Корпоративные сети
- 16 полезных примеров grep
- Синтаксис grep
- 1. Поиск среди нескольких файлов
- 2. Регистронезависимый поиск
- 3. Поиск слова
- 4. Вывод количества совпадений
- 5. Поиск в поддиректориях
- 6. Инверсивный поиск
- 7. Вывод нумерации строк
- 8. Ограничение вывода
- 9. Вывод дополнительных строк
- 10. Вывод списка файлов
- 11. Вывод абсолютных совпадений
- 12. Поиск совпадения в начале строки
- 13. Поиск совпадения в конце строки
- 14. Использования файла шаблонов
- 15. Поиск по нескольким шаблонам
- 16. Указание расширенных регулярных выражений
- Заключение
- Регулярные выражения в Grep (Regex)
- Регулярное выражение Grep
- Буквальные совпадения
- Якорь
- Соответствующий одиночный символ
- Выражения в скобках
- Квантификаторы
- Чередование
- Группировка
- Специальные выражения обратной косой черты
- Выводы
ИТ База знаний
Курс по Asterisk
Полезно
— Узнать IP — адрес компьютера в интернете
— Онлайн генератор устойчивых паролей
— Онлайн калькулятор подсетей
— Калькулятор инсталляции IP — АТС Asterisk
— Руководство администратора FreePBX на русском языке
— Руководство администратора Cisco UCM/CME на русском языке
— Руководство администратора по Linux/Unix
Навигация
Серверные решения
Телефония
FreePBX и Asterisk
Настройка программных телефонов
Корпоративные сети
Протоколы и стандарты
16 полезных примеров grep
Полезно про grep
Изначально разработанный для Unix-систем grep, является одной из наиболее широко используемых утилит командной строки в среде Linux.
grep расшифровывается как «глобальный поиск строк, соответствующих регулярному выражению и их вывод» (globally search for a regular expression and print matching lines). grep в основном ищет на основе указанного посредством стандартного ввода или файла шаблона, или регулярного выражения и печатает строки, соответствующие заданным критериям. Часто используется для фильтрации ненужных деталей при печати только необходимой информации из больших файлов журнала.
Это возможно благодаря совместной работе регулярных выражений и поддерживаемых grep параметров.
Онлайн курс по Linux
Мы собрали концентрат самых востребованных знаний, которые позволят тебе начать карьеру администратора Linux, расширить текущие знания и сделать уверенный шаг к DevOps

Здесь мы рассмотрим некоторые из часто используемых сисадминами или разработчиками команд grep в различных сценариях.
Синтаксис grep
Команда grep принимает шаблон и необязательные аргументы вместе со перечислять файлов, если используется без трубопровода.
1. Поиск среди нескольких файлов
grep позволяет выполнять поиск заданного шаблона не только в одном, но и среди нескольких файлах. Для этого можно использовать подстановочный символ * .
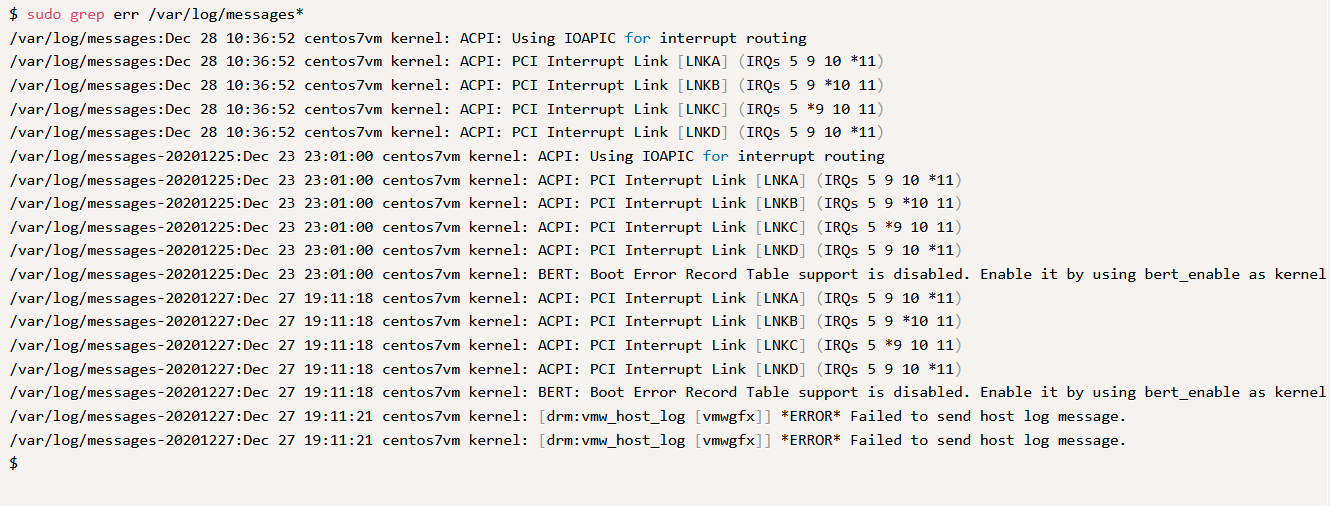
Как видно из вывода, утилита перед результатом искомого шаблона выводит также название файла, что позволяет определить где именно было найдено совпадение.
2. Регистронезависимый поиск
grep позволяет искать шаблон без учета регистра. Чтобы указать grep игнорировать регистр используется флаг –i .

3. Поиск слова
Иногда появляется необходимость поиска не части, а целого слова. В таких случаях утилита запускается с флагом -w .

4. Вывод количества совпадений
Не всегда нужно выводить результат совпадения. Иногда достаточно только количества совпадений с заданным шаблоном. Эту информацию мы можем получить с помощью параметра -c .

5. Поиск в поддиректориях
Часто необходимо искать файлы не только в текущей директории, но и в подкаталогах. grep позволяет легко сделать это с флагом -r .

6. Инверсивный поиск
Если вы хотите найти что-то, что не соответствует заданному шаблону, grep позволяет сделать только это с флагом -v .

Можно сравнить выходные резултаты grep для одного и того же шаблона и файла с флагом -v и без него. С параметром -v выводятся любые строки, которые не соответствуют образцу.
7. Вывод нумерации строк
grep позволяет нумеровать совпавшие строки, что позволяет легко определить, где строка находится в файле. Чтобы получить номера строк в выходных данных. используйте параметр –n :

8. Ограничение вывода
Результат вывода grep для файлов вроде журналов событий и т.д. может быть длинным, и вам может просто понадобиться фиксированное количество строк. Мы можем использовать -m [num] , чтобы ограничить выводимые строки.
Обратите внимание, как использование флага -m влияет на вывод grep для одного и того же набора условий в примере ниже:

9. Вывод дополнительных строк
Часто нам нужны не только строки, которые совпали с шаблоном, но некоторые строки выше или ниже их для понимания контекста.
С помощью флагов -A , -B или -C со значением num можно выводить строки выше или ниже (или и то, и другое) совпавшей строки. Здесь число обозначает количество дополнительных печатаемых строк, которое находится чуть выше или ниже соответствующей строки. Это применимо ко всем совпадениям, найденным grep в указанном файле или списке файлов.
Ниже показан обычный вывод grep, а также вывод с флагом -A , -B и -C один за другим. Обратите внимание, как grep интерпретирует флаги и их значения, а также изменения в соответствующих выходных данных. С флагом -A1 grep печатает 1 строку, которая следует сразу после соответствующей строки.
Аналогично, с флагом -B1 он печатает 1 строку непосредственно перед соответствующей строкой. С флагом -C1 он печатает 1 строку, которая находится до и после соответствующей строки.

10. Вывод списка файлов
Чтобы напечатать только имя файлов, в которых найден образец, а не сами совпадающие строки, используйте флаг -l .

11. Вывод абсолютных совпадений
Иногда нам нужно печатать строки, которые точно соответствуют заданному образцу, а не какой-то его части. Флаг -x grep позволяет делать именно это.
В приведенном ниже примере файл file.txt содержит строку только с одним словом «support», что соответствует требованию grep с флагом –x . При этом игнорируются строки, которые могут содержать слова «support» с сопутствующим текстом.

12. Поиск совпадения в начале строки
С помощью регулярных выражений можно найти последовательность в начале строки. Вот как это сделать.

Обратите внимание, как с помощью символ каретки ^ изменяет выходные данные. Символ каретки указывает grep выводить результат, только если искомое слово находится в начале строки. Если в шаблоне есть пробелы, то можно заключить весь образец в кавычки.
13. Поиск совпадения в конце строки
Другим распространенным регулярным выражением является поиск шаблона в конце строки.

В данном примере мы искали точку в конце строки. Поскольку точка . является значимым символом, нужно её экранировать, чтобы среда интерпретировала точку как команду. Обратите внимание, как изменяется вывод, когда мы просто ищем совпадения . и когда мы используем $ для указания grep искать только те строки, которые заканчиваются на . (не те, которые могут содержать его где-либо между ними).
14. Использования файла шаблонов
Могут возникнуть ситуации, когда у вас есть сложный список шаблонов, которые вы часто используете. Вместо записи его каждый раз можно указать список этих образцов в файле и использовать с флагом -f . Файл должен содержать по одному образцу на каждой строке.
В нашем примере мы создали файла шаблона с названием pattern.txt со следующим содержимым:

Для его использования используйте флаг -f .

15. Поиск по нескольким шаблонам
grep позволяет задать несколько шаблонов с помощью флага -e .

16. Указание расширенных регулярных выражений
grep также поддерживает расширенные регулярные выражения (Extended Regular Expressions – ERE) или с использованием флага -E . Это похоже на команду egrep в Linux.
Использование ERE имеет преимущество, когда вы хотите рассматривать метасимволы как есть и не хотите экранировать их. При этом использование -E с grep эквивалентно команде egrep .
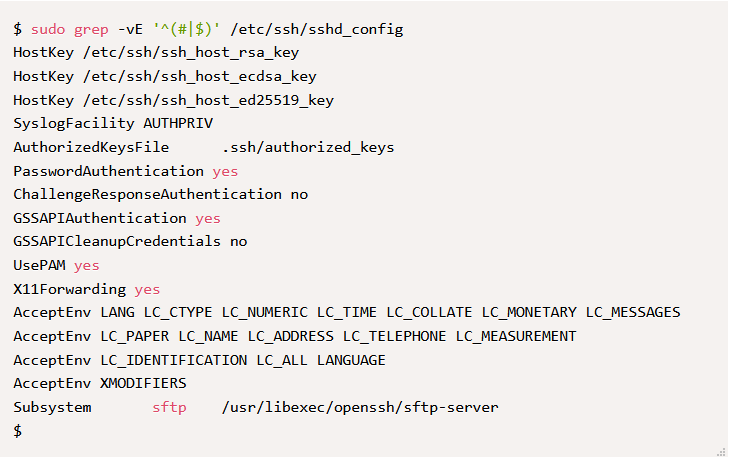
Ниже приведён пример использование ERE, для вывода не пустых и не закомментированных строк. Это особенно полезно для поиска чего-то в больших конфигурационных файлах. Здесь дополнительно использован флаг –v , чтобы НЕ выводить строки, соответствующих шаблону ‘^ (# | $)’ .
Заключение
Приведенные выше примеры являются лишь верхушкой айсберга. grep поддерживает ряд вариантов и может быть очень полезным инструментом в руке человека, который знает, как его эффективно использовать. Мы можем не только использовать приведенные выше примеры, но и комбинировать их различными способами, чтобы получить то, что нам нужно. Для получения дополнительной информации можно воспользоваться встроенной системой справки Linux – man .
Мини — курс по виртуализации
Знакомство с VMware vSphere 7 и технологией виртуализации в авторском мини — курсе от Михаила Якобсена
Источник
Регулярные выражения в Grep (Regex)
grep — одна из самых полезных и мощных команд Linux для обработки текста. grep ищет в одном или нескольких входных файлах строки, соответствующие регулярному выражению, и записывает каждую совпадающую строку в стандартный вывод.
В этой статье мы собираемся изучить основы использования регулярных выражений в GNU-версии grep , которая по умолчанию доступна в большинстве операционных систем Linux.
Регулярное выражение Grep
Регулярное выражение или регулярное выражение — это шаблон, который соответствует набору строк. Шаблон состоит из операторов, конструирует буквальные символы и метасимволы, которые имеют особое значение. GNU grep поддерживает три синтаксиса регулярных выражений: базовый, расширенный и Perl-совместимый.
В своей простейшей форме, когда тип регулярного выражения не указан, grep интерпретирует шаблоны поиска как базовые регулярные выражения. Чтобы интерпретировать шаблон как расширенное регулярное выражение, используйте параметр -E (или —extended-regexp ).
Как правило, вы всегда должны заключать регулярное выражение в одинарные кавычки, чтобы избежать интерпретации и расширения метасимволов оболочкой.
Буквальные совпадения
Наиболее простое использование команды grep — поиск буквального символа или серии символов в файле. Например, чтобы отобразить все строки, содержащие строку «bash» в /etc/passwd , вы должны выполнить следующую команду:
Результат должен выглядеть примерно так:
В этом примере строка «bash» представляет собой базовое регулярное выражение, состоящее из четырех буквальных символов. Это указывает grep искать строку, в которой сразу после grep «b» идут «a», «s» и «h».
По умолчанию команда grep чувствительна к регистру. Это означает, что символы верхнего и нижнего регистра рассматриваются как разные.
Чтобы игнорировать регистр при поиске, используйте параметр -i (или —ignore-case ).
Важно отметить, что grep ищет шаблон поиска как строку, а не слово. Итак, если вы искали «gnu», grep также напечатает строки, в которых «gnu» встроено в слова большего размера, например, «cygnus» или «magnum».
Если в строке поиска есть пробелы, вам нужно заключить ее в одинарные или двойные кавычки:
Якорь
Якоря — это метасимволы, которые позволяют указать, где в строке должно быть найдено совпадение.
Символ ^ (каретка) соответствует пустой строке в начале строки. В следующем примере строка «linux» будет соответствовать только в том случае, если она встречается в самом начале строки.
Символ $ (доллар) соответствует пустой строке в начале строки. Чтобы найти строку, заканчивающуюся строкой «linux», вы должны использовать:
Вы также можете создать регулярное выражение, используя оба якоря. Например, чтобы найти строки, содержащие только «linux», выполните:
Еще один полезный пример — шаблон ^$ , который соответствует всем пустым строкам.
Соответствующий одиночный символ
Файл . (точка) символ — это метасимвол, который соответствует любому одиночному символу. Например, чтобы сопоставить все, что начинается с «кан», затем имеет два символа и заканчивается строкой «ру», вы должны использовать следующий шаблон:
Выражения в скобках
Выражения в квадратных скобках позволяют сопоставить группу символов, заключив их в квадратные скобки [] . Например, найдите строки, содержащие «принять» или «акцент», вы можете использовать следующее выражение:
Если первый символ внутри скобок — это курсор ^ , то он соответствует любому одиночному символу, не заключенному в скобки. Следующий шаблон будет соответствовать любой комбинации строк, начинающихся с «co», за которыми следует любая буква, кроме «l», за которой следует «la», например «coca», «cobalt» и т. Д., Но не будет соответствовать строкам, содержащим «cola». ”:
Вместо того, чтобы помещать символы по одному, вы можете указать диапазон символов внутри скобок. Выражение диапазона создается путем указания первого и последнего символов диапазона, разделенных дефисом. Например, [aa] эквивалентно [abcde] а 2 эквивалентно [123] .
Следующее выражение соответствует каждой строке, начинающейся с заглавной буквы:
grep также поддерживает предопределенные классы символов, заключенные в скобки. В следующей таблице показаны некоторые из наиболее распространенных классов символов:
| Квантификатор | Классы персонажей |
|---|---|
| [:alnum:] | Буквенно-цифровые символы. |
| [:alpha:] | Буквенные символы. |
| [:blank:] | Пробел и табуляция. |
| [:digit:] | Цифры. |
| [:lower:] | Строчные буквы. |
| [:upper:] | Заглавные буквы. |
Полный список всех классов персонажей можно найти в руководстве по Grep .
Квантификаторы
Квантификаторы позволяют указать количество вхождений элементов, которые должны присутствовать, чтобы совпадение произошло. В следующей таблице показаны квантификаторы, поддерживаемые GNU grep :
| Квантификатор | Описание |
|---|---|
| * | Сопоставьте предыдущий элемент ноль или более раз. |
| ? | Соответствует предыдущему элементу ноль или один раз. |
| + | Сопоставьте предыдущий элемент один или несколько раз. |
| Сравните предыдущий элемент ровно n раз. | |
| Сопоставьте предыдущий элемент не менее n раз. | |
| Соответствовать предыдущему элементу не более m раз. | |
| Сопоставьте предыдущий элемент от n до m раз. |
Символ * (звездочка) соответствует предыдущему элементу ноль или более раз. Следующее будет соответствовать «right», «sright», «ssright» и так далее:
Ниже представлен более сложный шаблон, который соответствует всем строкам, которые начинаются с заглавной буквы и заканчиваются точкой или запятой. Регулярное выражение .* Соответствует любому количеству любых символов:
? (знак вопроса) символ делает предыдущий элемент необязательным и может соответствовать только один раз. Следующие будут соответствовать как «ярким», так и «правильным». ? Символ экранирован обратной косой чертой, потому что мы используем базовые регулярные выражения:
Вот то же регулярное выражение с использованием расширенного регулярного выражения:
Символ + (плюс) соответствует предыдущему элементу один или несколько раз. Следующее будет соответствовать «sright» и «ssright», но не «right»:
Фигурные скобки <> позволяют указать точное число, верхнюю или нижнюю границу или диапазон вхождений, которые должны произойти, чтобы совпадение произошло.
Следующее соответствует всем целым числам, содержащим от 3 до 9 цифр:
Чередование
Термин «чередование» представляет собой простое «ИЛИ». Оператор чередования | (pipe) позволяет вам указать различные возможные совпадения, которые могут быть буквальными строками или наборами выражений. Этот оператор имеет самый низкий приоритет среди всех операторов регулярных выражений.
В приведенном ниже примере мы ищем все вхождения слов fatal , error и critical в файле ошибок журнала Nginx :
Если вы используете расширенное регулярное выражение, то оператор | не следует экранировать, как показано ниже:
Группировка
Группировка — это функция регулярных выражений, которая позволяет группировать шаблоны вместе и ссылаться на них как на один элемент. Группы создаются с помощью круглых скобок () .
При использовании основных регулярных выражений скобки должны быть экранированы обратной косой чертой ( ).
Следующий пример соответствует как «бесстрашный», так и «меньший». ? квантификатор делает группу (fear) необязательной:
Специальные выражения обратной косой черты
GNU grep включает несколько метасимволов, которые состоят из обратной косой черты, за которой следует обычный символ. В следующей таблице показаны некоторые из наиболее распространенных специальных выражений обратной косой черты:
| Выражение | Описание |
|---|---|
| b | Сопоставьте границу слова. |
| Соответствует пустой строке в начале слова. | |
| > | Соответствует пустой строке в конце слова. |
| w | Подберите слово. |
| s | Подберите пробел. |
Следующий шаблон будет соответствовать отдельным словам «abject» и «object». Он не будет соответствовать словам, если вложен в слова большего размера:
Выводы
Регулярные выражения используются в текстовых редакторах, языках программирования и инструментах командной строки, таких как grep , sed и awk . Знание того, как создавать регулярные выражения, может быть очень полезным при поиске текстовых файлов, написании сценариев или фильтрации вывода команд.
Если у вас есть какие-либо вопросы или отзывы, не стесняйтесь оставлять комментарии.
Источник







