- 6 способов создать список уникальных значений в Excel
- Создать список уникальных значений с помощью специальной функции
- Создать список уникальных значений с помощью расширенного фильтра
- Создать список уникальных значений с помощью формул
- Отбор уникальных СТРОК в EXCEL
- Отбор уникальных значений (убираем повторы из списка) в EXCEL
- Задача
- Решение
- Решение для списков с пустыми ячейками
- Решение без формул массива
6 способов создать список уникальных значений в Excel
 Здравствуй уважаемый пользователь!
Здравствуй уважаемый пользователь!
В этой статье я хочу рассказать о возможности создать список уникальных значений в таблицах Excel. Эта возможность очень часто используется при работе с таблицами, так как часто возникает потребность с большого массива данных выбрать уникальные данные, которые не повторяются. Это может быть нужно для разнообразных целей, и уже вам решать каким способом и как произвести отбор нужных вам уникальных значений.
Список уникальных значений возможно создать 6-ю способами:
Создать список уникальных значений с помощью специальной функции
Это очень простой способ для владельцев Excel выше 2007 версии как произвести отбор уникальных значений. Вам нужно на вкладке «Данные», в разделе «Работа с данными», использовать специальную команду «Удалить дубликаты».
В появившемся диалоговом окне «Удалить дубликаты», вы выделяете те столбики, где необходимо произвести отсев уникальных значений и нажимаете «Ок». В случае, когда в выделенном диапазоне размещается и заголовок таблицы, то поставьте галочку на пункте «Мои данные содержат заголовки», что бы вы случайно не удалили данные.  Внимание! Когда вы будете производить отсев уникальных значений в таблице, где столбиков больше 2 и они взаимосвязаны информацией, Excel предложит вам расширить диапазон выбора, с чем вы должны, согласится, иначе будет нарушена логическая связь с другими столбиками.
Внимание! Когда вы будете производить отсев уникальных значений в таблице, где столбиков больше 2 и они взаимосвязаны информацией, Excel предложит вам расширить диапазон выбора, с чем вы должны, согласится, иначе будет нарушена логическая связь с другими столбиками.
Создать список уникальных значений с помощью расширенного фильтра
Это также не сложный способ произвести отбор уникальных значений в таблице. Использовать этот инструмент возможно на вкладке «Данные», потом выбрать «Фильтр», и наконец «Расширенный фильтр», этот путь подходит для Excel 2003, а вот владельцы более юных версий, от 2007 и выше стоит пройти по пути: «Данные» — «Сортировка и фильтр» — «Дополнительно». Огромный плюс этого способа в том, что вы можете создать новый список уникальных значений в другом месте.  После появления диалогового окна «Расширенный фильтр», устанавливаем галочку напротив пункта «Скопировать результат в другое место», потом указываем диапазон с вашими данными в поле «Исходный диапазон», при необходимости указываем критерий отбора, но для общего отсева поле оставляем пустым «Диапазон критериев», в третьем поле «Поместить результат в диапазон» указываем первую ячейку куда будут помещаться наши данные, отмечаем галочкой пункт «Только уникальные записи» и нажимаем «Ок».
После появления диалогового окна «Расширенный фильтр», устанавливаем галочку напротив пункта «Скопировать результат в другое место», потом указываем диапазон с вашими данными в поле «Исходный диапазон», при необходимости указываем критерий отбора, но для общего отсева поле оставляем пустым «Диапазон критериев», в третьем поле «Поместить результат в диапазон» указываем первую ячейку куда будут помещаться наши данные, отмечаем галочкой пункт «Только уникальные записи» и нажимаем «Ок».  Если же вам не нужно никуда переносить ваши данные, то просто установите флажок для пункта «Фильтровать список на месте», данные не пострадают, произойдет наложение обыкновенного фильтра.
Если же вам не нужно никуда переносить ваши данные, то просто установите флажок для пункта «Фильтровать список на месте», данные не пострадают, произойдет наложение обыкновенного фильтра.
Внимание! Если программа запрещает вам переносить отфильтрованные данные на другой лист, вы просто запустите «Расширенный фильтр» на том листе, куда вам надо перенести отобранные уникальные значения.
Создать список уникальных значений с помощью формул
Этот способ более сложен, нежели те, что мы рассматривали ранее, но его преимущество в том, что он более динамичен и работает на постоянной основе. В разных случаях вам будут нужны разные формулы, вот и рассмотрим несколько вариантов и примеров.
Пример 1. Вам нужно пронумеровать, уникальные, значение в списке значений, для этого нужно использовать функцию ЕСЛИ в формуле следующего вида:
=ЕСЛИ(СЧЁТЕСЛИ(B$1:B2;B2)=1;МАКС(A$1:A1)+1;»«)
Суть формулы в том, что она проверяет сколько раз, текущее значение встречается в вашем диапазоне (начиная с начала), и если это значение равно 1, то есть это первое уникальное значение, формула ставит последовательно возвращающий номер по порядку.  Теперь можно произвести отбор уникальных значений, которые были ранее пронумерованы. Сделать это возможно в любом из соседних столбиков используя функцию ВПР и копируя ее вниз:
Теперь можно произвести отбор уникальных значений, которые были ранее пронумерованы. Сделать это возможно в любом из соседних столбиков используя функцию ВПР и копируя ее вниз:
=ЕСЛИ(МАКС(A1:A100)
С ростом богатства растут и заботы. Гораций
Источник
Отбор уникальных СТРОК в EXCEL
history 22 апреля 2013 г.
Для извлечения из таблицы только уникальных строк (строк без повтора) можно использовать формулы.
Под «отбором уникальных строк» в статье понимается фильтрация таблицы для исключения всех повторных вхождений строк (одинаковых строк может быть, к примеру 3, но в отфильтрованную таблицу войдет только одна).
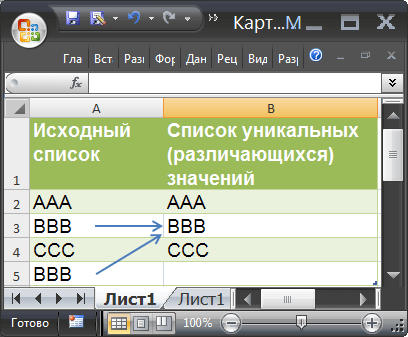
Создайте таблицу состоящую из 2-х столбцов (полей): Номер_заказа и КодТовара (см. файл примера ).
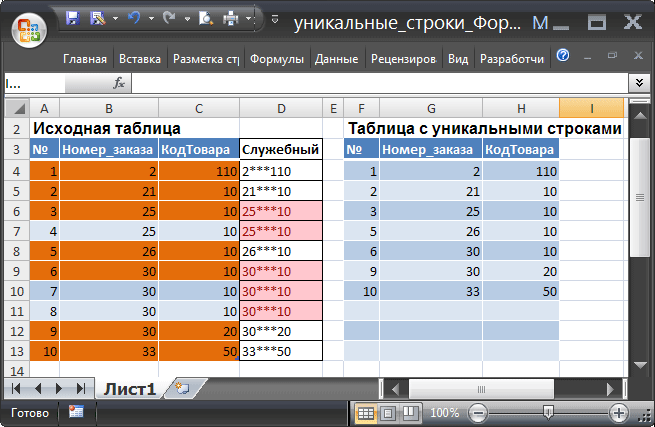
Строки таблицы 3 и 4 , а также 6, 7, 8 считаются одинаковыми строками, т.к. в них значения полей Номер_заказа и КодТовара совпадают. По этим строкам будет производиться группировка. В итоге, будет сформирована новая таблица, содержащая только уникальные строки, например, вместо трех строк 6, 7 и 8 получим одну строку.
Отбор строк по 2-м полям можно свести к задаче отбора строк по одному полю. Для этого сформируем из 2-х столбцов один Служебный (столбец D ) с помощью операции конкатенации ( Номер_заказа&КодТовара ).
В ситуации, когда две строки в полях Номер_заказа и КодТовара содержат соответственно 21; 10 и 2; 110 (см. рис. строки 1 и 2), то есть являются разными строками; объединение столбцов посредством обычной конкатенации ( Номер_заказа&КодТовара ) приводит к тому, что в столбце Служебный для двух строк будет одинаковое значение 2110. А такие строки будут считаться одинаковыми. Поэтому для конкатенации дополнительно используем набор символов *** (предполагаем, что *** заведомо не могут встретиться в этих строках): Номер_заказа&»***»&КодТовара.
Теперь начнем создавать новую таблицу. В столбце Номер_заказа ( G ) введем формулу массива : =ЕСЛИОШИБКА(ИНДЕКС($B$4:$B$13;НАИМЕНЬШИЙ( ЕСЛИ(ПОИСКПОЗ($D$4:$D$13;$D$4:$D$13;0)<>СТРОКА($D$4:$D$13) -СТРОКА($D$3);»повтор»;СТРОКА($D$4:$D$13)-СТРОКА($D$3));СТРОКА(1:1)));»»)
- Выделим часть формулы ПОИСКПОЗ($D$4:$D$13;$D$4:$D$13;0) и нажмем клавишу F9 , получим массив<1:2:3:3:5:6:6:6:9:10>с позициями первых вхождений значений в столбце Служебный ;
Если номер позиции не совпадает с текущей позицией ( ПОИСКПОЗ($D$4:$D$13;$D$4:$D$13;0)<>СТРОКА($D$4:$D$13)-СТРОКА($D$3) ), то значит это значение — повтор , и его не нужно включать в новую таблицу. Результатом функции ЕСЛИ() является массив с номерами позиций уникальных значений и словами « повтор »;
- Функция НАИМЕНЬШИЙ() сортирует массив и поэлементно выводит его;
- Функция ИНДЕКС() выбирает из столбца исходной таблицы ( Номер_заказа ) соответствующее значение.
В столбцах F и H запишем формулу массива подобную вышерассмотренной.
В итоге, получим таблицу (столбцы F , G , H ) без повторов (см. рисунок выше).
СОВЕТ: Список уникальных строк можно создать разными способами, например, с использованием Расширенного фильтра (см. статью Отбор уникальных строк с помощью Расширенного фильтра ) или Сводных таблиц .
Источник
Отбор уникальных значений (убираем повторы из списка) в EXCEL
history 22 апреля 2013 г.
Имея список с повторяющимися значениями, создадим список, состоящий только из уникальных значений. При добавлении новых значений в исходный список, список уникальных значений должен автоматически обновляться.
Пусть в столбце А имеется список с повторяющимися значениями, например список с названиями компаний.
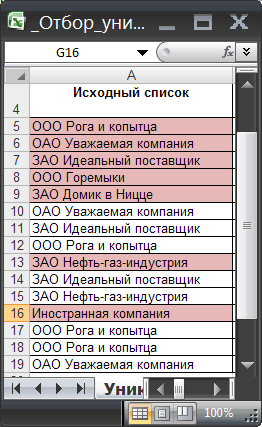
Задача
В некоторых ячейках исходного списка имеются повторы — новый список уникальных значений не должен их содержать.
Для наглядности уникальные значения в исходном списке выделены цветом с помощью Условного форматирования .
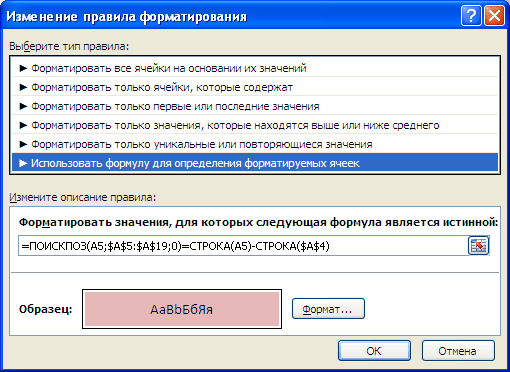
Решение
Для начала создадим Динамический диапазон , представляющий собой исходный список. Если в исходный список будет добавлено новое значение, то оно будет автоматически включено в Динамический диапазон и нижеследующие формулы не придется модифицировать.
Для создания Динамического диапазона :
- на вкладке Формулы в группе Определенные имена выберите команду Присвоить имя ;
- в поле Имя введите: Исходный_список ;
- в поле Диапазон введите формулу =СМЕЩ(УникальныеЗначения!$A$5;;; СЧЁТЗ(УникальныеЗначения!$A$5:$A$30))
- нажмите ОК.
Список уникальных значений создадим в столбце B с помощью формулы массива (см. файл примера ). Для этого введите следующую формулу в ячейку B5 :
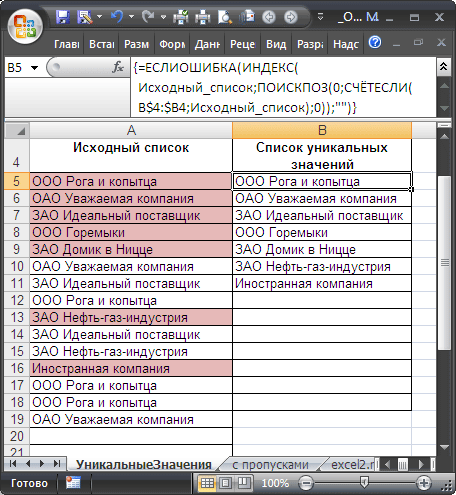
После ввода формулы вместо ENTER нужно нажать CTRL + SHIFT + ENTER . Затем нужно скопировать формулу вниз, например, с помощью Маркера заполнения . Чтобы все значения исходного списка были гарантировано отображены в списке уникальных значений, необходимо сделать размер списка уникальных значений равным размеру исходного списка (на тот случай, когда все значения исходного списка не повторяются). В случае наличия в исходном списке большого количества повторяющихся значений, список уникальных значений можно сделать меньшего размера, удалив лишние формулы, чтобы исключить ненужные вычисления, тормозящие пересчет листа.
Разберем работу формулу подробнее:
- Здесь использование функции СЧЁТЕСЛИ() не совсем обычно: в качестве критерия (второй аргумент) указано не одно значение, а целый массив Исходный_список , поэтому функция возвращает не одно значение, а целый массив нулей и единиц. Возвращается 0, если значение из исходного списка не найдено в диапазоне B4:B4( B4:B5 и т.д.), и 1 если найдено. Например, в ячейке B5 формулой СЧЁТЕСЛИ(B$4:B5;Исходный_список) возвращается массив <1:0:0:0:0:0:0:1:0:0:0:0:1:1:0>. Т.е. в исходном списке найдено 4 значения «ООО Рога и копытца» ( B5 ). Массив легко увидеть с помощью клавиши F9 (выделите в Строке формул выражение СЧЁТЕСЛИ(B$4:B5;Исходный_список) , нажмите F9 : вместо формулы отобразится ее результат);
- ПОИСКПОЗ() – возвращает позицию первого нуля в массиве из предыдущего шага. Первый нуль соответствует значению еще не найденному в исходном списке (т.е. значению «ОАО Уважаемая компания» для формулы в ячейке B5 );
- ИНДЕКС() – восстанавливает значение по его позиции в диапазоне Исходный_список ;
- ЕСЛИОШИБКА() подавляет ошибку, возникающую, когда функция ПОИСКПОЗ() пытается в массиве нулей и единиц, возвращенном СЧЁТЕСЛИ() , найти 0, которого нет (ситуация возникает в ячейке B12 , когда все уникальные значения уже извлечены из исходного списка).
Формула будет работать и в случае если исходный список содержит числовые значения.
Примечание . Функция ЕСЛИОШИБКА() будет работать начиная с версии MS EXCEL 2007, чтобы обойти это ограничение читайте статью про функцию ЕСЛИОШИБКА() . В файле примера имеется лист Для 2003 , где эта функция не используется.
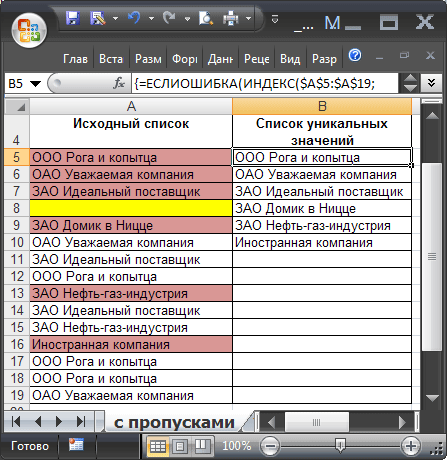
Решение для списков с пустыми ячейками
Если исходная таблица содержит пропуски, то нужно использовать другую формулу массива (см. лист с пропусками файла примера ): =ЕСЛИОШИБКА(ИНДЕКС($A$5:$A$19; ПОИСКПОЗ( 0;ЕСЛИ(ЕПУСТО($A$5:A19);»»;СЧЁТЕСЛИ($B$4:B4;$A$5:$A$19));0) );»»)
Решение без формул массива
Для отбора уникальных значений можно обойтись без использования формул массива . Для этого создайте дополнительный служебный столбец для промежуточных вычислений (см. лист «Без CSE» в файле примера ).
СОВЕТ: Список уникальных значений можно создать разными способами, например, с использованием Расширенного фильтра (см. статью Отбор уникальных строк с помощью Расширенного фильтра ), Сводных таблиц или через меню Данные/ Работа с данными/ Удалить дубликаты . У каждого способа есть свои преимущества и недостатки. Преимущество использования формул состоит в том, чтобы при добавлении новых значений в исходный список, список уникальных значений автоматически обновлялся.
СОВЕТ2 : Для тех, кто создает список уникальных значений для того, чтобы в дальнейшем сформировать на его основе Выпадающий список , необходимо учитывать, что вышеуказанные формулы возвращают значение Пустой текст «» , который требует аккуратного обращения, особенно при подсчете значений (вместо обычной функции СЧЕТЗ() нужно использовать СЧЕТЕСЛИ() со специальными аргументами ). Например, см. статью Динамический выпадающий список в MS EXCE L.
Примечание : В статье Восстанавливаем последовательности из списка без повторов в MS EXCEL решена обратная задача: из списка уникальных значений, в котором для каждого значения задано количество повторов, создается список этих значений с повторами.
Источник







